模型容量、欠拟合和过拟合
前面我们讨论了使用线性回归来对一个数据集进行建模,机器学习的真实应用场景是让算法学习到的参数在先前未观测到的新输入数据上仍然能够预测准确,而不只是在训练集上表现良好。能在新输入数据上表现良好的能力被称为**泛化(Generalization)**能力。
为了验证模型的泛化能力,我们一般会从训练集中划分一小部分数据作为测试集,测试集不参与模型的训练,只是为了用来验证训练好的模型在新数据上的表现。
那么,之前我们讨论的线性回归的最优化求解,实际上是在最小化训练集的误差:
实际上,为了衡量模型的泛化能力,我们关注的是模型在测试集上的误差:
在之前的例子中,我们将训练数据集拿来进行最优化求解,优化目标是降低模型在训练集上的误差。但是,机器学习又不能简单等同于最优化问题,因为在一些情况下,尽管我们可以让模型在训练集上将误差优化到很小,但是这个模型很可能在新输入数据上的泛化能力很差。
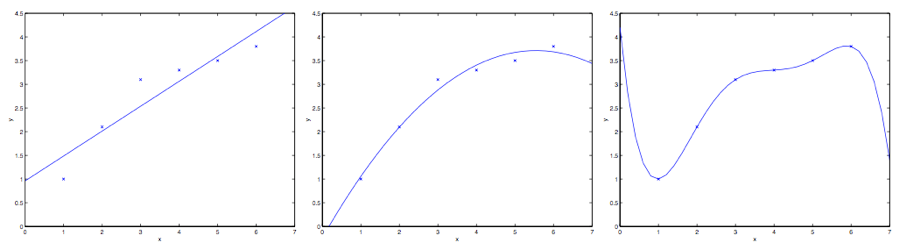
线性、二次、五次线性回归的拟合效果 来源:Andrew Ng CS229
我们制造一些训练数据,让训练数据模拟一个二次函数向上弯曲的趋势。图中最左侧使用线性回归 来对一个数据集进行拟合,这个模型无法捕捉到数据集中的曲率信息,有欠拟合(Underfitting)的可能。中间的图增加了一个二次项,用 来拟合,相当于增加了一维特征,我们对特征补充得越多,拟合效果就越好。不过,增加太多特征也会造成不良后果,最右边的图就是使用了五次多项式 来进行拟合。最后这个模型可以精确地拟合每个点,但是它并没有诠释数据的曲率趋势,这时发生了过拟合(Overfitting)。或者说,中间那个模型泛化能力较好,左右两侧的模型泛化能力一般。
机器学习领域的一大挑战就是如何处理欠拟合和过拟合问题。我们必须考虑:
- 降低模型在训练集上的误差。
- 缩小训练集误差和测试集误差之间的差距。
通过调整模型的容量(Capacity),我们可以控制模型是否偏向于过拟合或欠拟合。模型的容量是指其拟合各种函数的能力,容量低的模型很难拟合训练集,容量高的模型可能会过拟合。一种控制容量的办法是选择以什么样的数学模型来对数据集进行建模。例如,前面的例子中,左图使用的是线性回归函数,线性回归假设输出与输入之间是线性的;中间和右侧采用了广义的线性回归,即包括了二次项、三次项等,这样就增加了模型的容量。其他条件不变的情况下,深度学习模型一般会比线性回归模型的容量大。
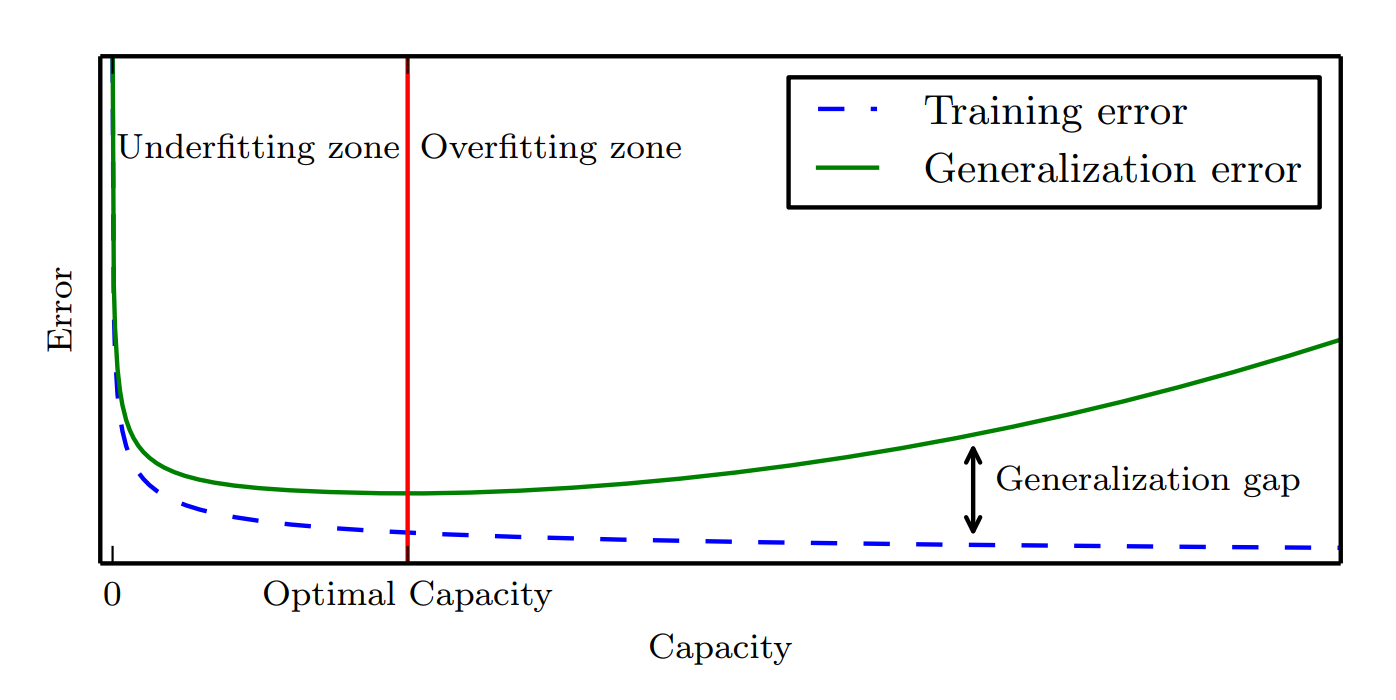
容量与误差之间的关系 来源:Deep Learning
当机器学习算法的容量适合于所执行的任务复杂度和所提供的训练数据数量,算法效果最佳。但如何确定最优容量实际上并没有太好的方法,尤其是确定深度学习模型容量非常困难。
参考资料
- Andrew Ng:CS229 Lecture Notes
- Ian Goodfellow and Yoshua Bengio and Aaron Courville: Deep Learning