线性回归的数学表示
线性回归是统计学中最基础的数学模型,几乎各个学科的研究中都能看到线性回归的影子,比如量化金融、计量经济学等;当前炙手可热的深度学习也一定程度构建在线性回归基础上。因此,每个人都有必要了解线性回归的原理。
线性回归对已有数据进行建模,可以对未来数据进行预测。有些人觉得线性回归太过简单,甚至不屑于称之为机器学习;另外一些人觉得很多编程库已经对线性回归做了封装,使用时调用一下函数就好,不必了解太多数学推导过程。实际上,线性回归是所有机器学习技术的一个最好起点,很多复杂的机器学习技术以及当前大火的深度神经网络都或多或少基于线性回归。
监督学习
吴恩达的机器学习系列课程的第一节以房价数据带领大家入门机器学习,该数据集提供了波特兰市47套房屋的面积、卧室数量和价格。
| 房屋面积(平方英尺) | 卧室数量 | 价格(千美元) |
|---|---|---|
| 2104 | 3 | 400 |
| 1600 | 3 | 330 |
| 2400 | 3 | 369 |
| 1416 | 2 | 232 |
| 3000 | 4 | 540 |
| ... | ... | ... |
我们先只关注房屋面积和价格这两维数据,将这两维数据的分布画出来,可以得到下面这张图:
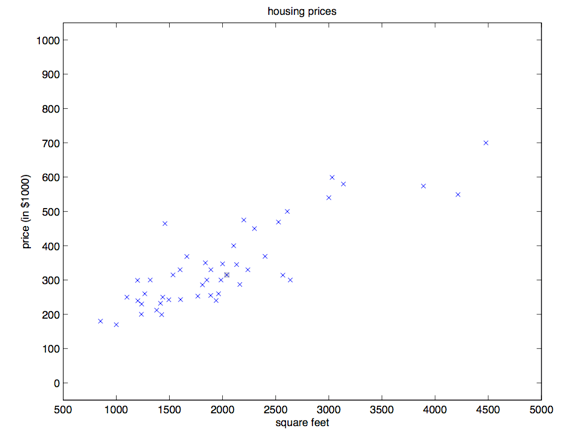
基于已有数据,我们希望通过计算机的学习,找到数据中的规律,并用来预测其他房屋的价格。这是机器学习最朴素的应用场景。这个过程也被称为监督学习(Supervised Learning),即给定一些数据,使用计算机学习到一种模式,然后用它来预测新的数据。
注
本文公式中变量加粗表示该变量为向量或矩阵
给定数据集 ,数据集中有个数据对。在房价的例子中,一共有47个数据对,第行数据为 ,这行数据被称为一组训练样本(Training Example)。其中,是一个两维向量,为房屋面积、为卧室数量,是房屋价格。我们可以基于这些数据,使用某种机器学习模型对其进行建模,学习到数据中的规律,得到一个模型(Model),其中某个给定的数据集为样本(Sample),又被称为训练集(Training Set), 为特征(Feature), 为真实值(Label)或者目标值(Target)。
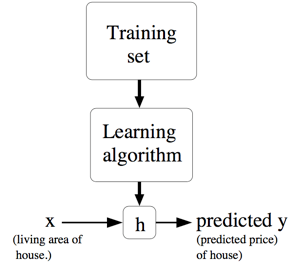
我们再用更加规范的方式来描述一下监督学习问题,我们的目标是,给定一个训练集,机器学习能够学习出一个函数 ,当有新的到达时, 能够得到一个预测值,且预测值与对应的真实 值尽可能接近。这个函数 就被叫做假设(Hypothesis)。监督学习的过程大概就是下图这样。在一些其他机器学习资料中,一般使用符号表示这个函数,本文将使用符号。
在房价预测的例子中,想要预测的目标值房价是连续的,我们称这类问题为回归(Regression)问题。与之相对应,当目标值只能在一个有限的离散集合里选择,比如预测房价是否大于100万,结果只有“是”和“否”两种选项,我们称这类问题为分类(Classification)问题。
注
ISO国际标准推荐使用小写字母加粗或者上标箭头来表示向量。向量一般默认为列向量(Column Vector)。
例如,表示一个名为的向量,因为手写时加粗字体并不现实,一般使用来表示向量。绝大多数教材和资料中会以列向量作为默认的表示形式。假如是一个维向量,一般会以的形式表示,即行1列,如下所示。
一元线性方程
前面我们展示了房价数据集中房屋面积与房价之间的数据。根据我们的社会经验和图中的数据分布,我们觉得能使用一个直线来描述“房价随着房屋面积增加而增加”的现象。针对这个数据集,可以使用一个最简单的机器学习模型——线性回归。
中学时,我们经常使用上面的方程来解一些数学问题,方程描述了变量 随着变量 而变化。方程从图形上来看,是一条直线。如果建立好这样的数学模型,已知 我们就可以得到预测的 了。统计学家给变量带上了一个小帽子,表示这是预测值,以区别于真实观测到的数据。方程只有一个自变量 ,且不含平方立方等非一次项,因此被称为一元线性方程。
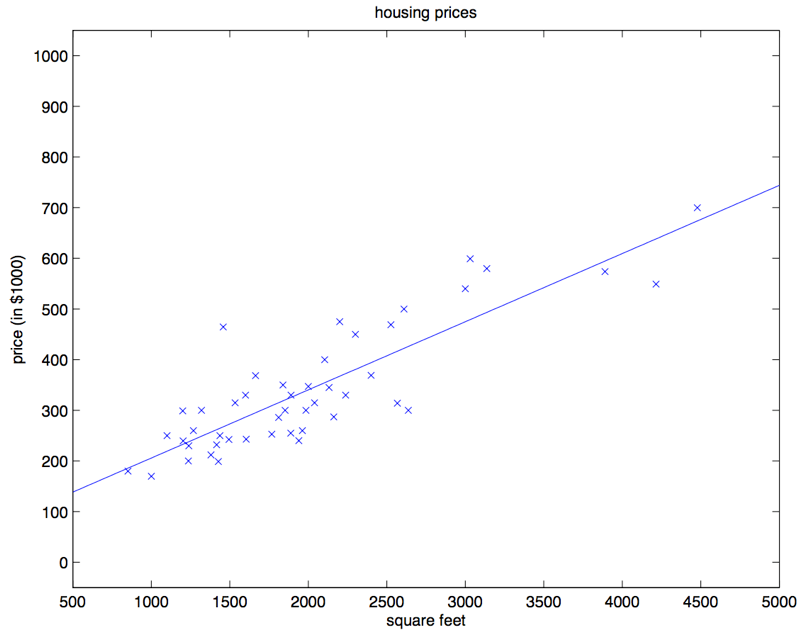
在对数据集进行建模时,我们只关注房屋面积和房价两个维度的数据。我们可以对参数和取不同值来构建不同的直线,这样就形成了一个参数家族。参数家族中有一个最佳组合,可以在统计上以最优的方式描述数据集。那么一元线性回归的监督学习过程就可以被定义为:给定 个数据对 ,寻找最佳参数 和 ,使模型可以更好地拟合这些数据。
和可以取不同的参数,到底哪条直线是最佳的呢?如何衡量模型是否以最优的方式拟合数据呢?机器学习用损失函数(Loss Function)的来衡量这个问题。损失函数又称为代价函数(Cost Function),它计算了模型预测值和真实值之间的差异程度。从名字也可以看出,这个函数计算的是模型犯错的损失或代价,损失函数越大,模型越差,越不能拟合数据。统计学家通常使用来表示损失函数。
对于线性回归,一个简单实用的损失函数为预测值与真实值误差的平方。公式1来表示单个样本点上预测值与真实值的误差的平方。
公式2表示将数据集的所有误差求和取平均。
再在其基础上代入公式,得到公式3。
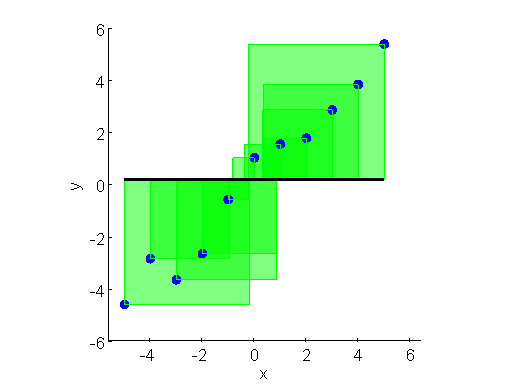
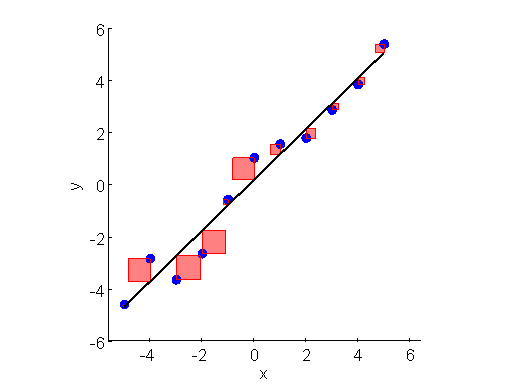
上面两张图直观展示了不同直线(不同模型参数)下损失函数的大小差别。误差的平方是一个正方形,将正方形的面积求和再取平均,就是损失函数。所有的正方形的平均面积越小,损失越小。对于给定数据集,和的值是已知的,参数和是需要求解的,模型求解的过程就是解下面公式的过程。
公式中 是一种常见的数学符号,表示寻找能让函数最小的参数和。
求解这个函数一般有两个方法:
- 基于微积分和线性代数知识,求使得导数为0的点,这个点一般为最优点。
- 基于梯度下降,迭代地搜索最优点。
后面将单独分别分析求解这两种方法。
线性回归的一般形式
我们现在把回归问题扩展到更为一般的场景。假设是多元的,或者说是多维的。比如,要预测房价,需要考虑包括是否学区、房间数量、周边是否繁华、交通方便性等。
这里的是参数(也可以叫做权重),是从 到 的线性回归参数。为了简化表示,我们可以把 里面的 省略掉,就简写成 。这里共有种维度的影响因素,机器学习领域将这种影响因素称为特征(Feature)。
第条样本有一个需要预测的和一组维向量。之前一元回归的参数拓展成了维的向量。这样,某个 可以表示成,其中 表示第 个样本的特征向量 中第 维特征值。
为了简化公式,我们还设 ,那么,这部分为截距项(Intercept Term)。这样简化之后就有了:
等式最右边的 和 都是向量,等式中的 是特征的维度(不包括)。
基于这个公式,得出损失函数,然后根据给定的训练集,尽量让损失函数最小。
相关信息
在上面的公式里,表示取平均,这里是否取平均其实对于求解损失函数的最小值没有影响,因此有些资料里为了表示方便,不取平均。另外一些资料中,为了方便对求导,会在外层添加一个。
同样,针对这个损失函数可以:
- 直接求解导数为零的点
- 使用梯度下降法