Logistic Regression曾经在互联网业务中被广泛用来进行搜索、推荐和广告的点击预估,可以说是使用频次最多的机器学习模型,也是深度神经网络的基础。在一些机器学习新人面试中,面试官经常会考察Logistic Regression的基本公式、损失函数的推导等问题。
从回归到分类
回归问题是指目标值为整个实数域,分类问题是指目标值为有限的离散值。
前面几篇文章系统讨论了线性回归模型:
f(x(i))=j=0∑nwjxj(i)=w⊤x(i)
这是一个回归模型,模型可以预测(−∞,+∞)范围的目标值。在模型求解时,我们可以使用误差平方定义损失函数,最小化损失函数即可求得模型参数。
现在,我们想进行二元分类,目标值有0和1两个选项,一个二分类函数可以表示为:
y={01if z<0if z≥0
当z<0时,将分类目标判定为负例,当z≥0时将分类目标判定为正例。这个分类函数其实是一个阶跃函数,在z=0不连续,或者说在z=0处发生了跳跃,这样的函数不方便求导。我们需要使用其他单调可微的函数来替代这个二元分类函数。
现在,我们可以在这个线性回归的基础上,在其外层套上一个函数g(z)。一个最常见的函数为:
g(z)=1+e−z1
这个函数的形状如下所示,它被称为对数几率函数、Logistic函数或者Sigmoid函数,后文将称之为Logistic函数。
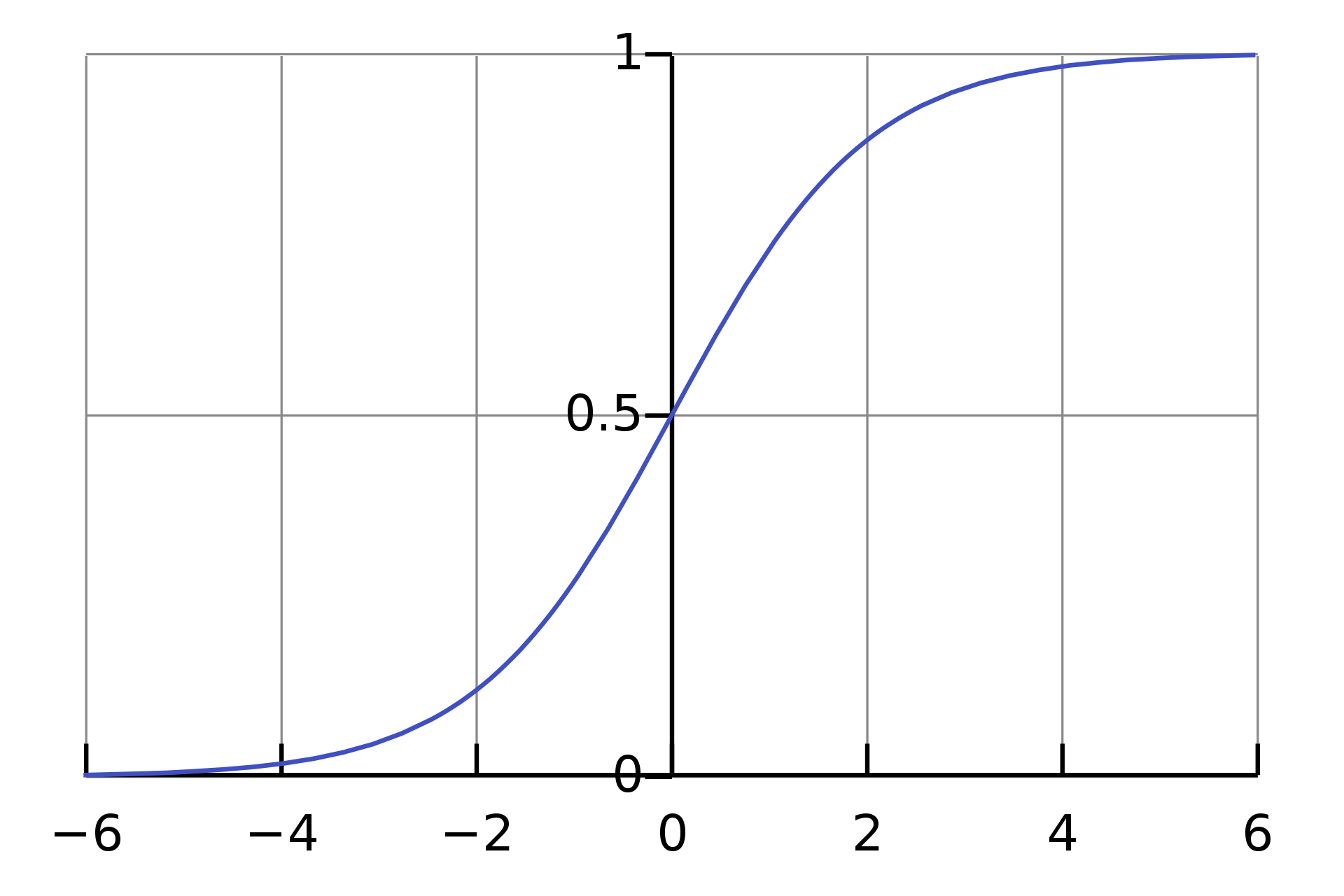 Logistic Function
Logistic Function从图形可以看出,Logistic函数有一些性质:
- 函数定义域为(−∞,+∞),值域为(0,1)。
- 当z趋近于−∞时,g(z)趋近于0;当z趋近于+∞时,g(z)趋近于1;当z取0时,g(z)等于0.5。
- 整个函数呈S形。
- 函数单调可微。
严格来说,Sigmoid函数是一个庞大的函数家族,用来表示S形函数。我们现在讨论的Logistic函数是Sigmoid函数中的一种,也是最具代表性的一个。Sigmoid函数将在神经网络中起重要作用。
Logistic函数的这些性质决定了它可以将(−∞,+∞)映射到(0,1)上,加上它在中心点处取值为0.5,可以用来进行分类。因为Logistic函数有明确的分界线,z小于0的部分将被分为负例(0),z大于0的部分将被分为正例(1)。
我们将线性回归套入Logistic函数,可以得到:
y=f(x)=g(w⊤x)=1+e−w⊤x1
我们在线性回归的基础上增加了一个Logistic函数,于是可以进行二元分类预测。一个训练集中有m条数据,第i条数据按照下面的公式进行拟合:
y(i)=f(x(i))=g(w⊤x(i))=1+e−w⊤x(i)1
这就是Logistic回归、逻辑斯蒂回归(Logistic Regression)。
注意,Logistic Regression中虽然名称中带有Regression回归字样,实际上,这是一个著名的分类模型。
Logistic函数二元概率解释
Logistic函数适合表示二分类概率。假设我们将y表示为分类时作为正例的可能性,那么1−y就是分成负例的可能性。恰好Logistic Regression有如下性质:
ln1−yy=w⊤x
其中,1−yy被称为几率(Odds),表示当前数据被分类到正例的相对可能性。ln1−yy是几率的对数,被称为对数几率(Log Odds,或者Logit)。
我们回顾一下概率知识:我们知道概率都是[0,1]区间上的值,假设一件事物成功的概率为P(Success)=0.8,失败的概率为P(Fail)=1−P(Success)=0.2。那么,这件事成功的几率Odds为:1−P(Success)P(Success)=0.20.8=4。也就是说,它成功的可能性非常大。
回到Logistic Regression上,线性回归w⊤x试图去逼近几率的对数ln1−yy。实际上,Logitstic Regression对分类的可能性进行建模,可以得到近似概率的预测。很多基于概率辅助决策的任务都会使用此模型。比如,包括Google在内的很多公司曾经使用Logistic Regression预测一条互联网广告是否会被点击:训练时,广告被点击标记为正例,否则为负例;预测值越高,该广告越会投放在醒目的位置,以吸引用户点击。
Logistic函数将(−∞,+∞)映射到了(0,1)上,无论多大或者多小的值,都可以和一个(0,1)区间的概率联系起来,这样就得到了一个概率分布。
Logistic Regression的最大似然估计
Logistic函数可以和概率联系起来,于是我们可以将y视为分类到正例的概率估计:P(y=1∣x),分类到负例的概率为:P(y=0∣x)。
P(y=1∣x)=f(x)
P(y=0∣x)=1−f(x)
可以将上面这两个概率写成一个更为紧凑的公式:
P(Y=y∣x;w)=(f(x))y(1−f(x))1−y
由于y只有两种可能,即0(负例)和1(正例):那么如果y=1,(1−f(x))0=1,P(Y=y∣x)=(f(x))1,如果y=0,(f(x))0=1,P(Y=y∣x)=(1−f(x))1。上式中,分号和w表示,w是参数,并不是随机变量。
有了概率表示,我们很容易进行概率上的最大似然估计。因为似然函数与概率函数的形式几乎相似,概率函数就是所有样本发生的概率的乘积,而似然函数是关于参数w的函数。
L(w)=P(y∣X;w)=i=1∏mP(y(i)∣x(i);w)=i=1∏m(f(x(i)))y(i)(1−f(x(i)))1−y(i)
和线性回归一样,我们对上面的公式取log,这样更容易实现似然函数的最大化:
ℓ(w)=logL(w)=i=1∑my(i)logf(x(i))+(1−y(i))log(1−f(x(i)))
如何求得上面公式的解?和线性回归一样,我们可以利用梯度上升法。当前目标是最大化似然函数,因此我们要使用梯度上升,不断迭代寻找最大值。具体而言,参数按照下面的方式来更新:
\boldsymbol{w} := \boldsymbol{w} +\alpha \nabla _\boldsymbol{w} \ell(\boldsymbol{w})
参数估计中最关键的是得到导数公式。求导之前,我们再回顾一下Logistic Regression:
f(x)=g(w⊤x)
g(z)=1+e−z1
而Logistic函数g(z)在求导时有:g′(z)=g(z)(1−g(z)),因为:
g′(z)=dzd1+e−z1=(1+e−z)21(e−z)=(1+e−z)1⋅(1−(1+e−z)1)=g(z)(1−g(z))
然后,我们开始求参数的导数。我们仍然先假设训练集中只有一条数据(x,y)。下面推导的第三行就用到了Logistic函数导数性质g′(z)=g(z)(1−g(z))。
∂wj∂ℓ(w)=(yf(x)1−(1−y)1−f(x)1)∂wj∂f(x)=(yg(w⊤x)1−(1−y)1−g(w⊤x)1)∂wj∂g(w⊤x)=(yg(w⊤x)1−(1−y)1−g(w⊤x)1)g(w⊤x)(1−g(w⊤x))∂wj∂w⊤x=(y(1−g(w⊤x))−(1−y)g(w⊤x))xj=(y−g(w⊤x))xj=(y−f(x))xj
那么,具体到参数迭代更新的公式上,以训练集的第i条样本数据拿来进行计算:
wj:=wj+α(yi−f(x(i)))xj(i)
跟我们之前推导的线性回归函数的公式可以说是一模一样。于是,在这个问题上,我们可以使用梯度上升法来获得最优解。或者做个简单的变换,变成梯度下降法:
wj:=wj−α(f(x(i))−y(i))xj(i)
前面公式只是假设训练集中只有一条样本数据,而当训练集有m条数据,对ℓ(w)=∑i=1my(i)logf(x(i))+(1−y(i))log(1−f(x(i)))进行求导,实际上是可以得到:
∂wj∂ℓ(w)=i=1∑m(y(i))−f(x(i)))xj(i)
直接拿全量数据来更新参数不太现实,绝大多数情况下都会使用随机梯度下降法求解,可以随机挑选某个样本来更新参数,也可以随机挑选一小批Mini-batch样本来更新参数。
分类阈值
Logistic Regression最终返回的是概率,我们可以直接使用这个预测出来的概率,也可以设定阈值,将概率转化成二元分类问题。
例如,预测用户点击某条广告的概率为 0.00023,远高于其他广告,那么这条广告会投放到最醒目的位置,最有可能被用户点击。
我们也可以将返回的概率转换成二元值,例如,预测某封电子邮件是垃圾邮件的概率很大,判定其为垃圾邮件。如果逻辑回归模型对某封电子邮件进行预测时返回的概率为 0.9995,则表示该模型预测这封邮件非常可能是垃圾邮件。相反,在同一个逻辑回归模型中预测分数为 0.0003 的另一封电子邮件很可能不是垃圾邮件。可如果某封电子邮件的预测分数为 0.6 呢?为了将逻辑回归值映射到二元类别,我们必须指定分类阈值(Threshold,也称为判定阈值)。如果逻辑回归返回值高于该阈值,则表示“垃圾邮件”;如果值低于该阈值,则表示“非垃圾邮件”。
分类阈值可以设置为 0.5,实际上,阈值取决于具体问题,我们必须根据具体的业务场景、正负样本的比例等问题对阈值进行调整。选取阈值肯定会非常影响预测结果,一种办法是选择不同的阈值进行测试,计算不同阈值下的准确率(Precision)和召回率(Recall),然后选择出最佳阈值。
类别训练数据不均衡问题
前面介绍的Logistic函数二元分类一直假设不同类别的训练样本数目相当,如果正负例的训练样本数目差别不大,通常对结果没有太大影响,但如果正负例样本差别很大,会对学习过程造成困扰。例如,一个数据集有998个负例,但只有2个正例,那么模型每次都预测为负例,就能达到99.8%的准确率,然而这样的模型其实没有任何价值。现实的分类问题中,经常会遇到类别不平衡的问题,比如:
- 在垃圾邮件识别场景下,比起正常邮件,垃圾邮件的数目相对较少。
- 在信用卡欺诈检测的场景下,绝大多数交易是正常的,只有少量交易有问题。
- 在机器故障报警场景下,机器绝大多数情况下正常运行,发生故障的时间远小于正常运行的时间。
在逻辑回归中,我们用预测出的y值与一个阈值进行比较,通常在y>0.5时判别为正例,否则为负例。y实际上表达了该条数据作为正例的可能性,几率1−yy则反映了正例可能性与负例可能性的比值,当y=0.5时,几率1−yy=1表明正负可能性相同。基于这样的假设,如果1−yy>1,则预测为正例。
然而,当训练集中正负例的数目有较大差异时,令m+表示正例数目,m−表示负例数目,则在训练集中观测到的几率是m−m+。那么预测几率要大于训练集几率,或者说1−yy>m−m+,应该判定为正例。因此,这种情况下,仍然使用0.5作为阈值显然不合适。
为了解决数据不均衡问题,我们需要对训练集进行调整,大体有两类做法:
- 对训练集进行欠采样(Undersampling)或过采样(Oversampling),减少或增加数据,使得训练集正负例数目接近,然后再进行学习。
- 直接使用原始训练集进行学习,但是不再使用0.5作为分类阈值,而是根据业务场景、样本正负例数目对阈值进行一定调整。
如何确定正负样本需要根据具体问题来具体讨论。欠采样会丢弃一些数据,使得训练集远小于初始数据,这可能会丢失一些重要信息,进而影响模型的效果。过采样会伪造一些数据,但不能简单地将原始数据中的样本复制,否则会导致过拟合。过采样的代表性算法为SMOTE(Synthetic Minority Over-sampling Technique),其核心思想是通过插值的方式伪造数据。比如,假设数据集所有特征都是连续的,可以形成一个特征空间,先从数据集中找到一个样本点,再找到一个与之相邻的同类的样本,在特征空间上这两个点之间可以构成一条直线,在这条直线上随机找到一个点用来生成新的数据,加入到训练集中。
当然,如果样本数据不均衡,或许选择另外的算法模型可能更合适,比如决策树模型,决策树的原理决定了其在不均衡样本上表现更好。
参考资料
- Andrew Ng:CS229 Lecture Notes
- 周志华: 机器学习
- https://developers.google.com/machine-learning/crash-courseopen in new window