ResNet 残差神经网络
深度卷积网络的瓶颈
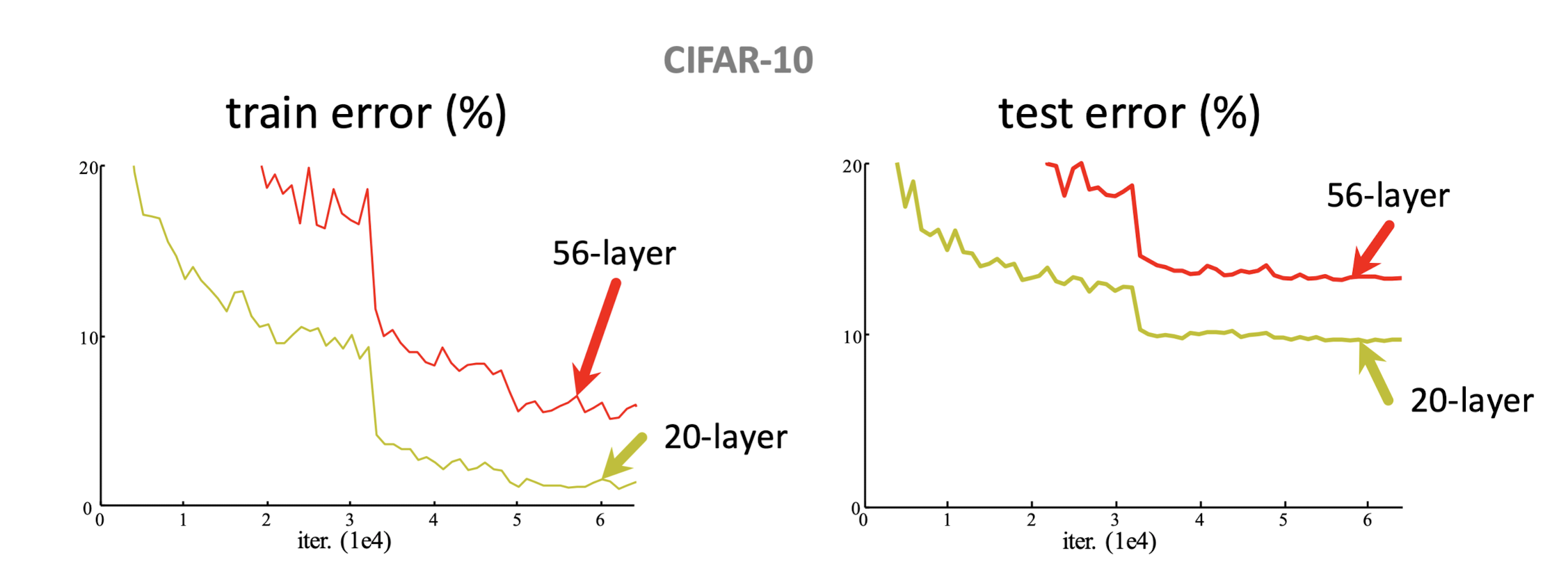
理论上,增加网络层数后,网络可以进行更加复杂的特征模式的提取,所以当模型更深时可以取得更好的结果。但VGG、GoogLeNet等网络单纯增加层数遇到了一些瓶颈:简单增加卷积层,训练误差不但没有降低,反而越来越高。在CIFAR-10、ImageNet等数据集上,单纯叠加3×3卷积,何恺明等[1]人发现,训练和测试误差都变大了。这不是过拟合的问题,因为56层网络的训练误差同样高。这主要是因为深层网络存在着梯度消失或者爆炸的问题,模型层数越多,越难训练。
从另一个角度考虑,假如我们把浅层模型直接拿过来,在此基础上增加新的层,一种极端的情况是,新增加的层什么都不学习,新模型至少不会比浅层模型更差。“什么都不学习”,学术上被称为恒等映射(Identity Mapping),用数学表达式表示为:。其中,是我们希望拟合的一个网络结构,或者说是一种映射关系。
残差块
但是神经网络的ReLU激活函数恰恰不能保证“什么都不学习”。残差网络的初衷就是尽量让模型结构有“什么都不做”的能力,这样就不会因为网络层数的叠加导致梯度消失或爆炸。
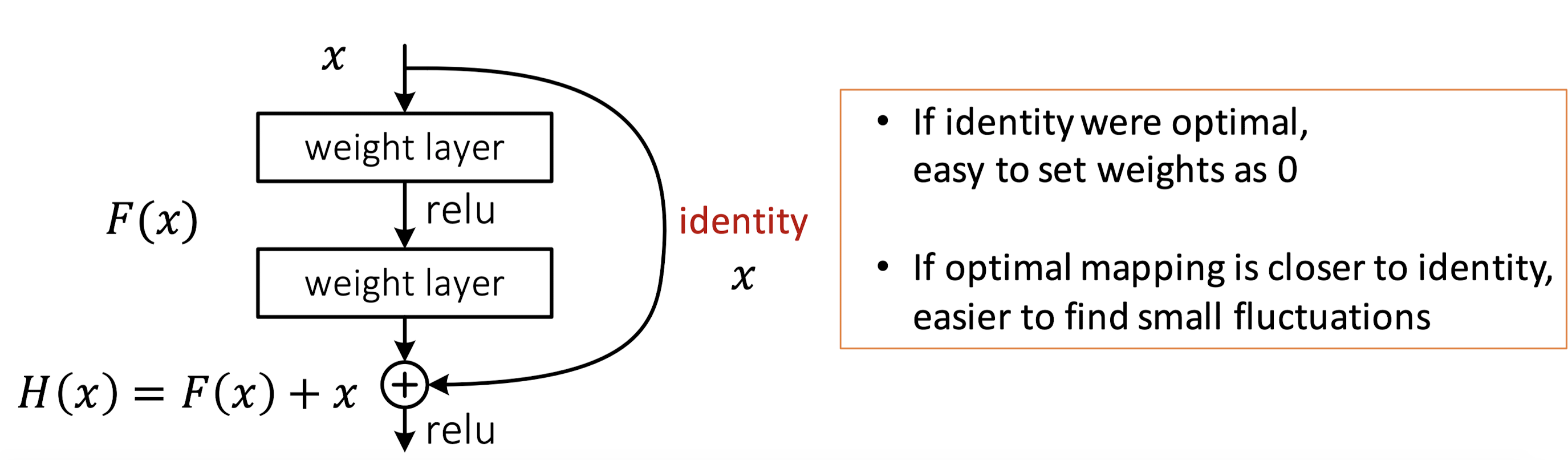
现在有:,只要,那么,就是一个恒等映射,也就是有了“什么都不做”的能力。ResNet基于这种思想提出了一种残差网络的结构,其中,输入可以传递到输出,传递的过程被称为Shortcut;同时,图2里有两个权重层,即部分。假如“什么都不学习”是最优的,或者说是最优的,那么理论上来说,学习到的目标值为0即可;如果不是最优解,那么基于神经网络强大的学习能力,可以尽可能去拟合我们期望的值。
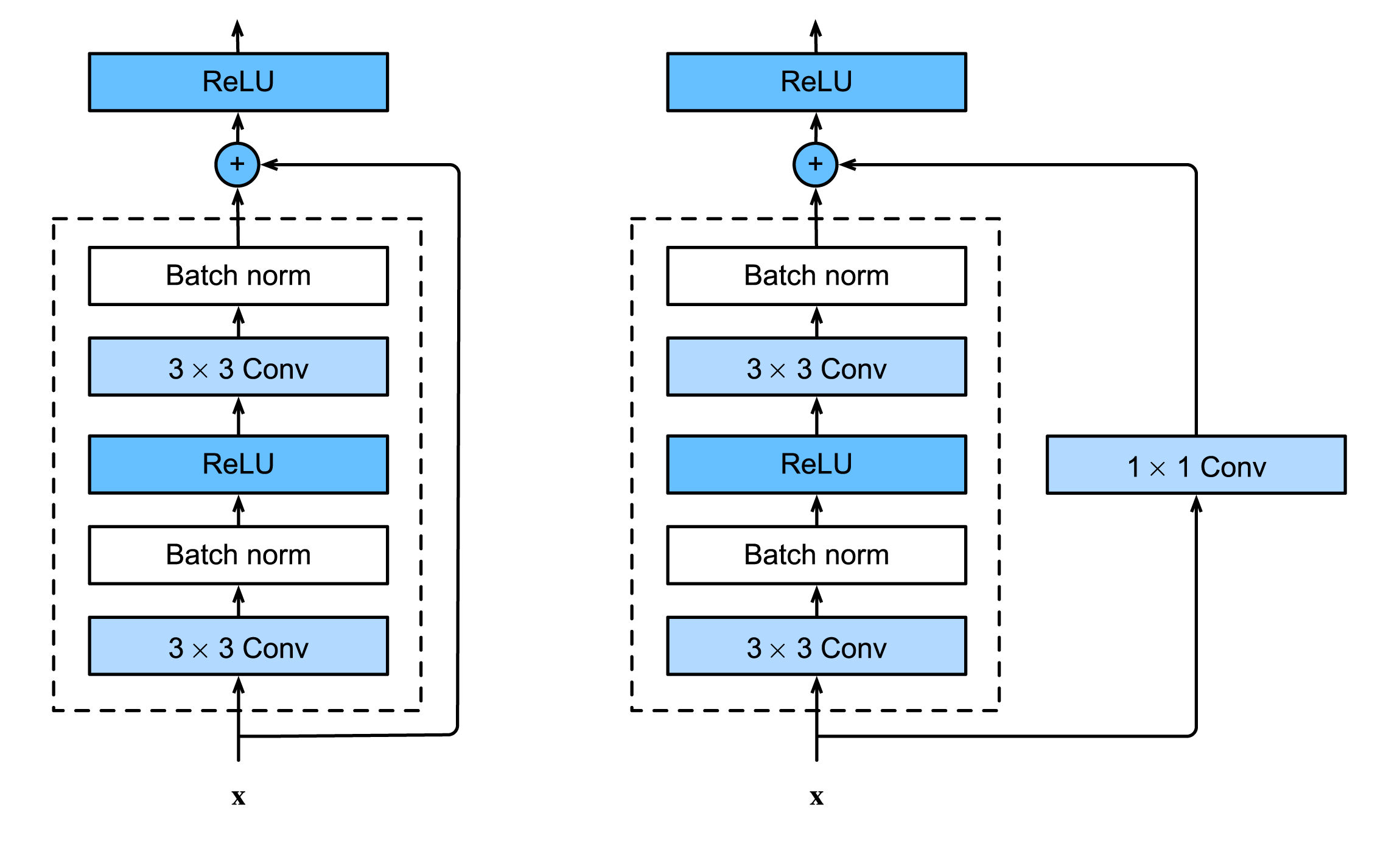
具体实现上,残差基础块有几种构建的方式,如图3所示。图3左侧虚线部分的输出结果与直接相加,图3右侧经过1×1卷积层再与虚线部分相加。虚线部分包含了两个3×3卷积层。图3左侧虚线部分能和输入直接相加的前提是,虚线里的3×3卷积层没有改变的维度,可以直接相加。如果卷积层改变了的维度,一种办法是使用1×1卷积层直接相加(图3右侧),论文作者称之为Option B,一种办法是用0填充(未在图3中画出),论文作者称之为Option A。
import torch
from torch import nn
from torch.nn import functional as F
class Residual(nn.Module):
"""The Residual block of ResNet."""
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
ResNet-34
基于残差基础块,我们可以构建ResNet网络,论文中给出了基于ImageNet数据集的ResNet-34和VGG-19的对比图。图4最左侧是VGG-19,中间是只使用3×3卷积层的Plain Network(没有使用Shortcut),右侧是使用了Shortcut的ResNet-34。ResNet-34除了第一层是7×7卷积层、最后一层是全连接层外,中间全是3×3卷积层。
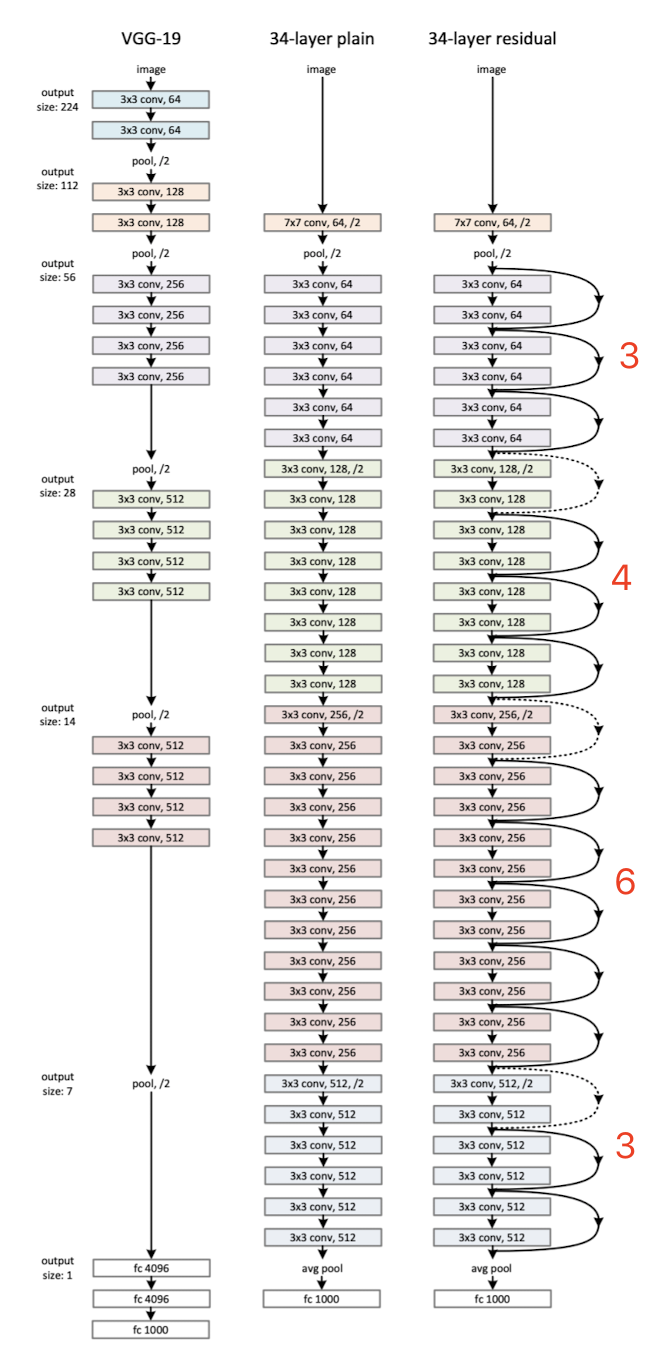
图4最右侧是ResNet-34,命名为ResNet-34,是因为网络中7×7卷积层、3×3卷积层和全连接层共34层。在计算这个34层时,论文作者并没有将BatchNorm、ReLU、AvgPool以及Shortcut中的层考虑进去。图4右侧ResNet-34中的3×3卷积层的颜色不同,共4种颜色。每种颜色表示一个模块,由一组残差基础块组成,只不过残差基础块的数量不同,从上到下依次是[3, 4, 6, 3]个残差基础块。另外,图4右侧,残差基础块中用实线Shortcut表示维度没有变化(可以直接相加);虚线Shortcut表示维度变化了,比如通道数从64变为128,无法直接相加,或者在上填充0,或者使用1×1卷积层改变维度。
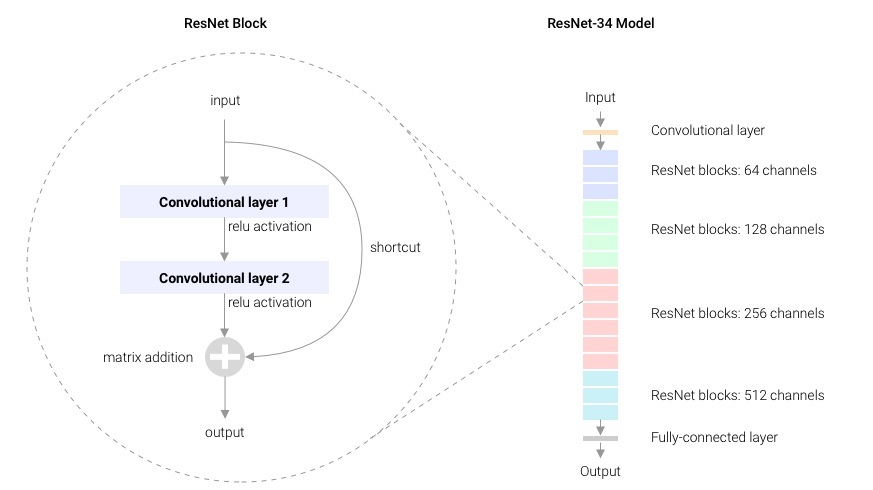
图5的解释更加直观一些,图5右侧是ResNet-34宏观上的网络结构,每个小格子是一个残差基础块(图5左侧)。图5右侧中不同颜色,表示输入的通道数发生了变化。
Bottleneck
ResNet-34核心部分均使用3×3卷积层,总层数相对没那么多,对于更深的网络,作者们提出了另一种残差基础块。图6左侧为ResNet-34所使用的残差基础块,被成为Basic Block;图6右侧为ResNet-50/101/152等深层网络上使用的残差基础块,被称为Bottleneck Block,Bottleneck Block中使用了1×1卷积层。如输入通道数为256,1×1卷积层会将通道数先降为64,经过3×3卷积层后,再将通道数升为256。1×1卷积层的优势是在更深的网络中,用较小的参数量处理通道数很大的输入。
图6左侧,输入输出通道数均为64,残差基础块中两个3×3卷积层参数量是:$ 3 \times 3 \times 64 \times 64 + 3 \times 3 \times 64 \times 64 = 73728$图6右侧,输入输出通道数均为256,残差基础块中的参数量是:。两个一比较,使用1×1卷积层,参数量减少了。当然,使用这样的设计,也是因为更深的网络对显存和算力都有更高的要求,在算力有限的情况下,深层网络中的残差基础块应该减少算力消耗。

ResNets
ResNet-34中残差基础块的数量是[3, 4, 6, 3],如果改变这个列表,可以组合出几种不同的网络,共同构成了ResNet家族。下表为各个网络的信息。
| 网络 | 残差基础块数量 | 基础块类型 |
|---|---|---|
| ResNet-18 | [2, 2, 2, 2] | Basic |
| ResNet-34 | [3, 4, 6, 3] | Basic |
| ResNet-50 | [3, 4, 6, 3] | Bottleneck |
| ResNet-101 | [3, 4, 23, 3] | Bottleneck |
| ResNet-152 | [3, 8, 36, 3] | Bottleneck |
以最常用来作为各类Benchmark的ResNet-50为例,残差基础块的数量为:3 + 4 + 6 + 3 = 16,每个残差基础块都使用Bottleneck,Bottleneck里共3个卷积层(2个1×1卷积层+1个3×3卷积层),16 × 3 = 48,加上一开始的7×7卷积层和最后的全连接层,共50层。
pre-activation
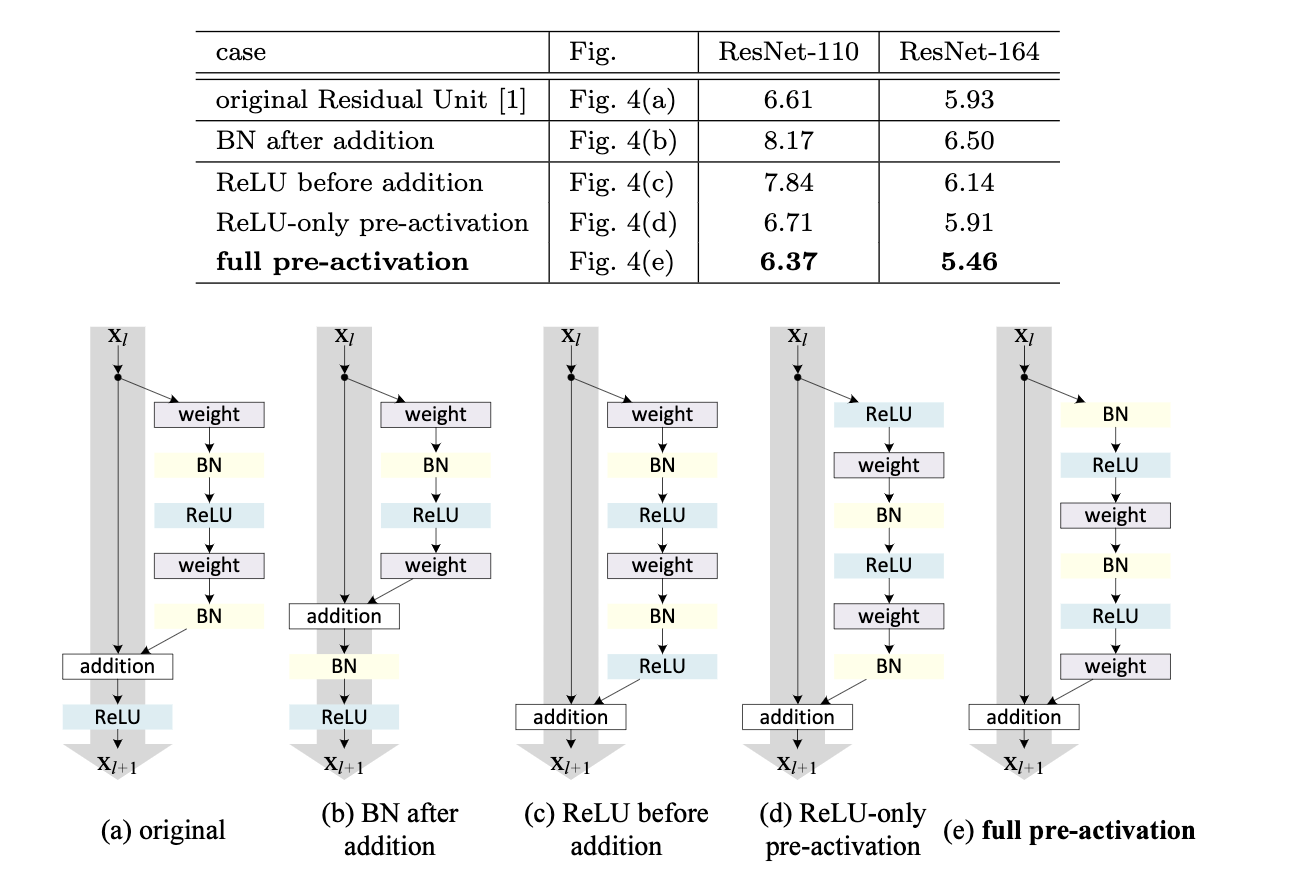
前面介绍的是何恺明等人提出的第一版ResNet,后来他们又在第一版基础上做了一些改进,其中一个重要的方向对BatchNorm、ReLU和卷积层的位置进行调整。图7中a/b/c/d/e是几种残差基础块的构成方式,这几种残差块包含的模块是一样的,都是权重层(卷积层)、BN(BatchNorm)、ReLU以及加法运算。根据作者们的证明和分析,图7中的e能获得很大的收益,在CIFAR-10上的表现最好(图7上半部分的表格为CIFAR-10上的表现)。图7中e先进行BatchNorm和ReLU,再进行卷积运算。这种将BatchNorm和ReLU提前的方式被称为pre-activation,意思是激活(activation)提前到卷积层前面。
小结
- ResNet由残差基础块组成,残差基础块使用了的思想,让模型具有“什么都不做”的能力。
- 如果因为维度不同,无法直接相加,可以在上填充0,或者使用1×1卷积层改变维度。
- 残差基础块分两种:第一种的使用2个3×3卷积层,名为Basic Block;第二种的使用了1×1卷积层降低维度,紧接一个3×3卷积层,最后使用1个1×1卷积层升高维度,名为Bottleneck Block。
- 我们可以调整残差基础块的数量,得到不同深度的网络,这些网络共同组成了ResNet家族。
参考资料
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770–778).
- He K., Zhang X., Ren S., Sun J. (2016) Identity Mappings in Deep Residual Networks. ECCV 2016. ECCV 2016. Lecture Notes in Computer Science, vol 9908. Springer, Cham. https://doi.org/10.1007/978-3-319-46493-0_38
- http://d2l.ai/chapter_convolutional-modern/resnet.html
- https://www.alanmartyn.com/content/how-residual-shortcuts-speed-up-learning.html