BatchNorm 批量归一化
深度神经网络很难训练。因为深度神经网络中网络层数太多,在训练过程中,模型参数的更新会引起靠近输出侧各层的输出结果发生剧烈的变化。Google 将这一现象总结为Internal Covariate Shift(ICS),具体而言,有如下表现:
- 靠近输出侧的各层需要不断去重新适应参数更新,学习速度慢。
- 每层的更新都会影响到其他层,为了训好模型,我们需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略。
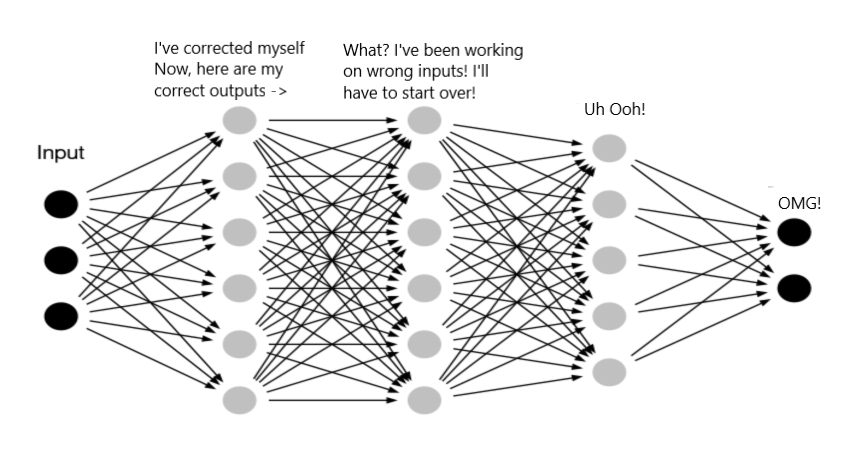
Internal Covariate Shift
从上图可以看到,靠近输入侧的层稍有更新,靠近输出侧的层都需要重新寻找更优参数。这种计算数值的不稳定性通常令我们难以训练出有效的深度模型。对数据进行归一化是解决这类问题的一种思路。
批量归一化的数学表示
归一化是机器学习特征工程常用的技巧,一般是减去均值然后除以标准差。
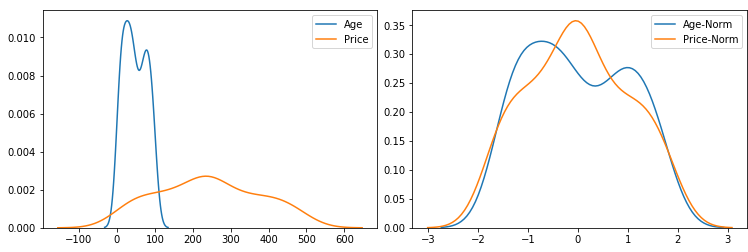
年龄和价格特征,单位不同,作为模型的输入,需要先进行归一化
浅层的模型,比如线性回归,逻辑回归等,需要对输入特征进行归一化。假设我们有两个特征,分别为年龄和价格,这两个特征的度量单位不同,表征含义不同,直接用来作为机器学习算法的特征,分布不均匀。我们需要使用归一化,将这两个特征转成均值为0的分布,机器学习的效果会好很多。
基于这种归一化的思想,我们可以在深度神经网络的层与层之间使用归一化,Google 提出了批量归一化。
批量归一化(Batch Normalization)主要是在一个批次(Batch)上进行归一化。给定一个批次,批次内包含多个样本,表示属于这个批次。Batch Normalization的公式如下:
在这个公式中,是这个批次所有样本的均值,是这个批次所有样本的标准差,是一个对输入数据进行归一化的过程,即减去均值然后除以标准差。数据经过的归一化后,得到一个均值为0,方差为单位误差的分布。
接着,还要对这个归一化的数值进行伸缩(Scale)和偏移(Shift)。是一个伸缩系数,可以对数据扩大或缩小,它和的维度相同,表示中的每个元素与归一化之后的按元素(Element-wise)做乘法。是一个偏移系数,它和的维度相同,按元素做加法。和是两个需要学习的参数。对于一个输入,经过后,得到的数据符合均值为,方差为的分布。
一个疑问是,明明是为了进行归一化,我们得到了均值为0,方差为单位误差的分布了,为什么又在归一化的基础上加了伸缩和平移?怎么又变回去了?答案是:为了保障模型的表达能力不因为归一化而下降。直观上来讲,神经网络某一层的在努力地学习,如果只做,那么这一层的输出会被粗暴地限制到某个固定的范围,后续层输入都是这样一个分布的数据。有了伸缩和平移,而且这两个参数是需要学习的参数,那么这一层的输出就不再被粗暴归一化的了。
如果不使用Batch Normalization,某一层的输入均值取决于前序层神经网络的复杂的前向传播;使用了Batch Normalization,某一层的输入均值仅由来确定,去除了与前序网络前向传播计算的紧耦合。
在计算和时,需要使用下面的公式:
其中,为批次中的样本数量。另外,是一个很小的常数,因为Batch Normalization在计算过程中,在分母上,需要保证分母大于0。
全连接和卷积的批量归一化
对于深度卷积神经网络,全连接层和卷积层的批量归一化实现起来稍有差别。Batch Normalization主要使用一个批次的样本数据,在之前的各个卷积神经网络的讨论中,我们其实一直没有关注批次维度,实际上,模型训练一般(batch_size, features)的形式,批次中的样本数量是一个重要的维度。
全连接层的批量归一化
注
本文公式中变量加粗表示该变量为向量或矩阵
卷积层的一个批次的数据一般遵循(batch_size, features)的模式,第一维是批次中样本数量,第二维是全连接层输入的维度。
原始论文将Batch Normalization放在了仿射变换()的后面,非线性激活函数的前面。后续一些应用也将Batch Normalization放在非线性激活函数的后面。如果按照原始论文,首先经过仿射变换,进行批量归一化,再使用非线性激活函数,输出为完整的公式为:
在进行Batch Normalization时,均值和方差都是基于一个批次内的数据。
卷积层的批量归一化
一般将Batch Normalization放在卷积层后,非线性激活函数前。
区别于全连接层,卷积层一个批次的数据一般遵循(batch_size, channels, height, width)的模式,第一维是批次中样本数量,第二维是频道数,第三维和第四维是高和宽。我们需要对这些通道的输出分别做批量归一化,且每个通道都拥有独立的伸缩和偏移参数,并均为标量。设批次中有个样本。在单个通道上,卷积层输出的高和宽分别为和。我们需要对该通道中个元素同时做批量归一化。具体的计算均值和方差时,我们使用该通道中个元素的均值和方差。如果有个通道,要对这个通道都执行一次批量归一化。
Batch Normalization在一定程度上解决了计算不稳定的问题,可以加速训练的过程,原始论文提到:
We apply Batch Normalization to the best-performing ImageNet classification network, and show that we can match its performance using only 7% of the training steps, and can further exceed its accuracy by a substantial margin.
预测时的批量归一化
使用批量归一化训练时,我们可以将批量大小设得大一点,从而使批量内样本的均值和方差的计算都较为准确。将训练好的模型用于预测时,一般输入都是单个样本,没办法计算归一化的均值和方差。我们可以计算整个训练样本的均值和方差,使用这个均值和方差。这种方法计算量很大,另一种常用的方法是在训练时,通过移动平均估算整个训练数据集的样本均值和方差,并在预测时使用它们得到确定的输出。下面公式计算了移动平均值。
在这个批次内,我们先计算批次内均值和方差,另外有变量和存储着批次之间移动平均值。这里的是一个系数,又被称为Momentum。计算时会跨多个批次,Momentum可以设置为0.9,那么移动平均会保留原来移动平均值的0.9,并将本批次平均值的0.1更新到移动平均值里。
注
需要注意的是,这里的Momentum与优化器中的Momentum不同。另外,移动平均值是在训练过程中,在遍历所有训练样本时计算得到的,训练结束后保留下来,在预测时使用。
框架实现
如前文所述,计算的过程没有那么复杂,深度学习框架PyTorch和TensorFlow已经帮我们实现了。比如,PyTorch中torch.nn.BatchNorm2d,TensorFlow的tf.keras.layers.BatchNormalization。
参考资料
Ioffe, S., & Szegedy, C. (2015). Batch normalization: accelerating deep network training by reducing internal covariate shift.