GoogLeNet 并行连接的网络
在2014年的ImageNet图像识别挑战赛中,Google提出的GoogLeNet夺得头筹。GoogLeNet的名字在向LeNet致敬,但在网络结构上已经很难看到LeNet的影子。GoogLeNet吸收了NiN中1×1卷积层的思想,并在此基础上做了很大改进。在随后的几年里,研究人员对GoogLeNet进行了数次改进,本节将介绍这个模型系列的第一个版本。
Inception块
GoogLeNet中的基础卷积块叫作Inception块,得名于电影《盗梦空间》(Inception)。在电影中,主角在梦境与真实之间穿梭,并一直在强调:“We need to go deeper”。与NiN块相比,这个基础块在结构上更加复杂,如下图所示。
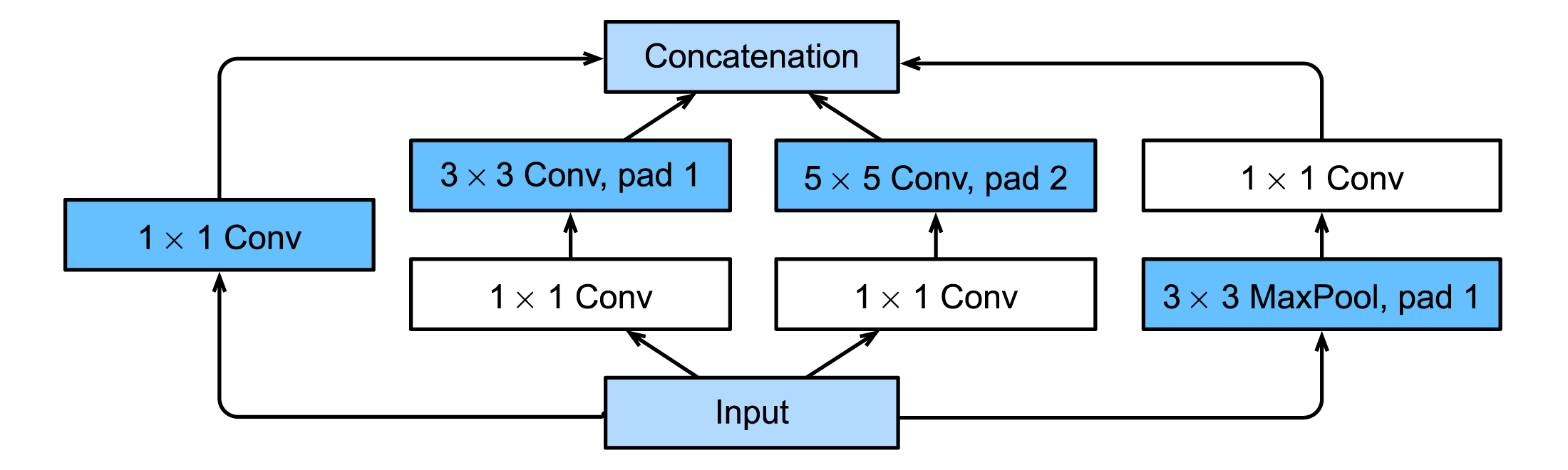
Inception块里有4条并行的路径(Path)。前3条路径使用窗口大小分别是1 × 1、3 × 3和5 × 5的卷积层来抽取不同空间尺寸下的信息,其中中间2个路径会对输入先做1 × 1卷积来减少输入通道数,以降低模型复杂度。第四条路径则使用3 × 3最大池化层,后接1 × 1卷积层来改变通道数。4条路径都使用了合适的填充来使输入与输出的高和宽一致,或者说,假如输入图像为12 × 12,那么四条路径输出尺寸均为 12 × 12,只不过输出通道数不同。每个最后我们将每条路径的输出在通道维上连结。比如,路径1的输出为 64 × 12 × 12,路径2的输出为128 × 12 × 12,路径3的输出为32 × 12 × 12,路径4的输出为32× 12 × 12,整个Inception块输出为(64 + 128 + 32 + 32) × 12 × 12。因此,Inception块一个可调的超参数是不同路径的输出通道数。
下面的代码定义了Inception块,参数in_channels为输入的通道数,c1到c4为各个路径的输出通道数。
class InceptionBlock(nn.Module):
# `c1`--`c4` are the number of output channels for each path
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(InceptionBlock, self).__init__(**kwargs)
# Path 1 is a single 1 x 1 convolutional layer
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# Path 2 is a 1 x 1 convolutional layer followed by a 3 x 3
# convolutional layer
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# Path 3 is a 1 x 1 convolutional layer followed by a 5 x 5
# convolutional layer
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# Path 4 is a 3 x 3 maximum pooling layer followed by a 1 x 1
# convolutional layer
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# Concatenate the outputs on the channel dimension
# the output channel number is c1 + c2[1] + c3[1] + c4
return torch.cat((p1, p2, p3, p4), dim=1)
Inception块使用不同的卷积层对输入进行探索,我们可以将不同的路径通过一定比例融合到一起。
GoogLeNet
比起AlexNet/VGG/NiN,GoogLeNet模型看起来更加复杂,涉及到众多精心设计的模块。
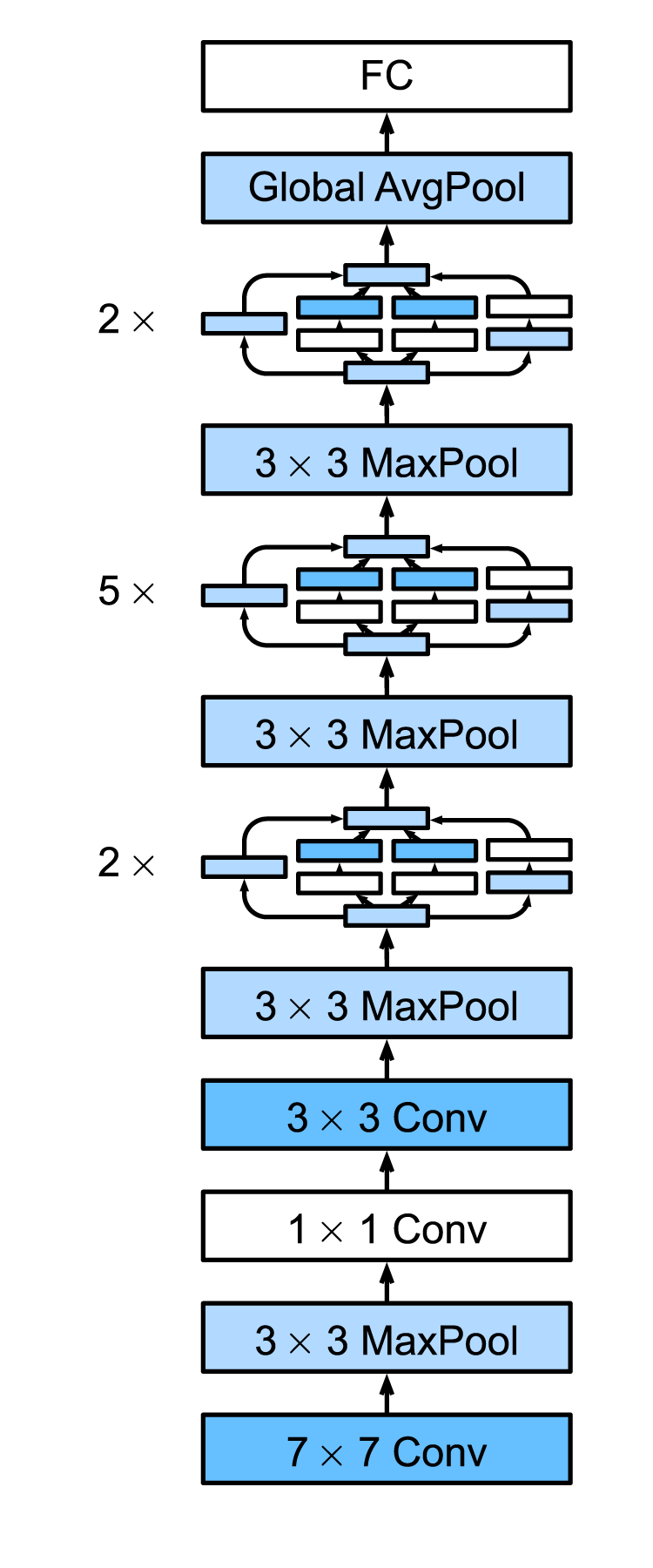
我们用96×96大小的输入来演示各个步骤后数据尺寸的变化。
def googlenet():
# input shape: 1 * 96 * 96
# convolutional and max pooling layer
# 1 * 96 * 96 -> 64 * 24 * 24
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# convolutional and max pooling layer
# 64 * 24 * 24 -> 192 * 12 * 12
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 2 InceptionBlock
# 192 * 12 * 12 -> 480 * 6 * 6
b3 = nn.Sequential(InceptionBlock(192, 64, (96, 128), (16, 32), 32),
InceptionBlock(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 5 InceptionBlock
# 480 * 6 * 6 -> 832 * 3 * 3
b4 = nn.Sequential(InceptionBlock(480, 192, (96, 208), (16, 48), 64),
InceptionBlock(512, 160, (112, 224), (24, 64), 64),
InceptionBlock(512, 128, (128, 256), (24, 64), 64),
InceptionBlock(512, 112, (144, 288), (32, 64), 64),
InceptionBlock(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 2 InceptionBlock and max pooling layer
# 832 * 3 * 3 -> 1024 * 1
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
# AdaptiveMaxPool2d convert the matrix into 1 * 1 scalar
nn.AdaptiveMaxPool2d((1,1)),
nn.Flatten())
# final linear layer, for classification label number
# 1024 -> 10
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
return net
这段代码中,将整个GoogLeNet拆解成5大部分:
- b1: 7 × 7的卷积层和3 × 3的池化层
- b2: 1 × 1的卷积层、3 × 3的卷积层和3 × 3最大池化层
- b3: 2个连续的Inception块和3 × 3最大池化层
- b4: 5个连续的Inception块和3 × 3最大池化层
- b5: 2个连续的Inception块紧跟全局平均池化层,经过全局平均池化层后,每个通道变为1×1的标量
我们以b3为例,b3里有两个Inception块,第一个Inception块中,4条路径的输出通道维数分别为64、128、32和32,这4条路径的比例为:64: 128: 32: 32 = 2: 4: 1: 1。这些参数是在ImageNet数据集上经过大量实验得到的。
最后将1024维变为标签类别数,如果使用Fashion-MNIST,输出类别为10。
模型的训练过程与之前分享的LeNet、AlexNet、VGG基本相似,所有代码放在了GitHub上。
小结
- Inception块相当于一个有4条路径的子网络。4条路径中有不同窗口大小的卷积层和最大池化层,4条路径并行抽取信息。
- GoogLeNet将多个精心设计的Inception块和其他层串联起来。其中Inception块的通道数分配之比是在ImageNet数据集上通过大量的实验得来的。
- GoogLeNet和它的后继者们一度是ImageNet上最高效的模型之一。
参考资料
- Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., & Anguelov, D. & Rabinovich, A.(2015). Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1-9).
- http://d2l.ai/chapter_convolutional-modern/googlenet.html
- https://tangshusen.me/Dive-into-DL-PyTorch/#/chapter05_CNN/5.9_googlenet