混合精度训练
通常而言,神经网络训练的性能瓶颈通常在于GPU显存:一方面是单张GPU卡上可容纳的模型和数据量,另一方面是显存和计算单元的带宽和延迟有限。在Micikevicius et al.[1]提出混合精度训练之前,深度学习模型都是在使用float32精度进行训练的,Micikevicius等人经过实验发现,可以使用更低的精度来训练神经网络,进而带来巨大速度收益。混合精度训练一般能够获得2-3倍的速度提升。
低精度以及混合精度训练开始流行,以至于深刻影响了深度学习框架、GPU和神经网络加速器的设计。
精度:FP32,FP16...
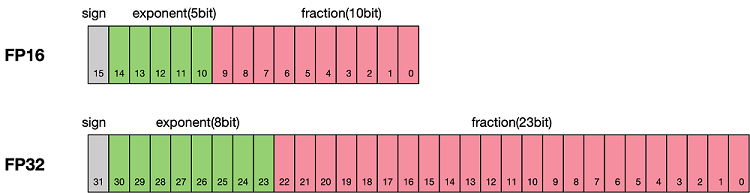
计算机是二进制的,使用多个二进制位表示不同的数字。比如,int8使用8位二进制表示正数,float32(FP32,单精度)使用32位二进制表示浮点数,具体表示的方法类似于科学计数法,如下图所示。FP32总共32位,第一位是sign(符号位),表示正负数;后面八位是exponent,用来计算;再后面八位是fraction。

相比之下,更低精度的float16(FP16,半精度)的exponent和fraction位数更少,所能表示的数字范围也更小。
低精度带来的优势是:
同样的GPU显存,可以容纳更大的参数量、更多的训练数据。FP16的占用的空间是FP32的一半,因此权重等参数所占用的内存也是原来的一半,节省下来的内存可以放更大的网络模型或者使用更多的数据进行训练。
低精度的算力(FLOPS)可以做得更高。一些芯片可以设计很高的低精度计算单元,比如当前主流的神经网络加速芯片都有极高的FP16算力,FP32的算力相比FP16较低。
单位时间内,计算单元访问GPU显存上的数据可以获得更高的速度。此外,针对分布式训练,特别是在大模型训练的过程中,通讯的开销制约了网络模型训练的整体性能,低精度意味着可以提升通讯性能,减少等待时间,加快数据的流通。
低精度的缺点显而易见:能表示的数值范围有限。精度越低,数值范围越小。FP16的有效数据表示范围为,FP32的有效数据表示范围为。可见FP16相比FP32的有效范围要窄很多,使用FP16替换FP32会出现上溢(Overflow)和下溢(Underflow)的情况。在深度学习中,需要计算网络模型中权重的梯度(一阶导数),梯度会比权重值更加小,往往容易出现下溢情况。
Micikevicius等人发现神经网络训练没必要一直用FP32,可以适当使用FP16。这一发现也深刻影响了神经网络硬件和框架的设计。比如:
- 深度学习框架均提供了低精度训练功能。
- NVIDIA在最新架构中考虑了不同的精度,华为的昇腾910处理器的算力主要集中在FP16[2],Google的TPU设计了特殊的bfloat16格式。
混合精度训练
混合精度训练的计算流程如下:
参数以FP32存储;
正向计算过程中,遇到FP16算子,需要把算子输入和参数从FP32转换成FP16进行计算;
将Loss层设置为FP32进行计算;
反向计算过程中,首先乘以Loss Scale值,避免反向梯度过小而产生下溢;
FP16参数参与梯度计算,其结果将被转换回FP32;
除以loss scale值,还原被放大的梯度;
判断梯度是否存在溢出,如果溢出则跳过更新,否则优化器以FP32对原始参数进行更新。
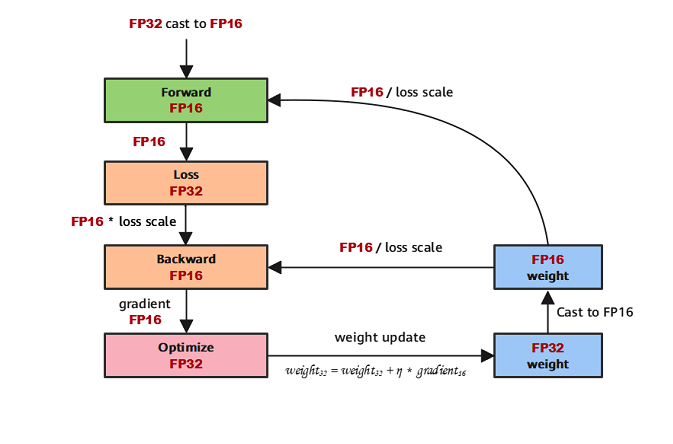
具体而言,混合精度训练使用了三个技术。
FP32模型权重
FP32 master copy of weights。模型的权重使用FP32来表示,保证了数值准确性。在前向和反向计算时,先将FP32权重转化成FP16,同时还保留一份FP32的Master Copy。最后将梯度更新到Master Copy上。那么计算时可以获得FP16的速度提升,而权重这样重要的数据仍然以FP32的高精度来保存。
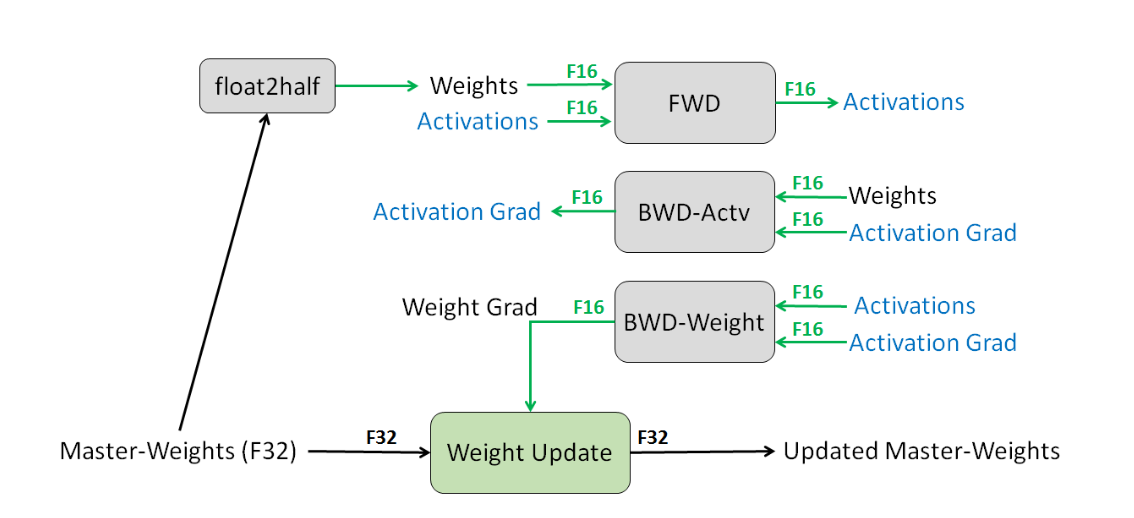
Loss Scale
FP16的精度范围有限,训练一些模型的时候,梯度数值在FP16精度下都被表示为0,如下图所示。
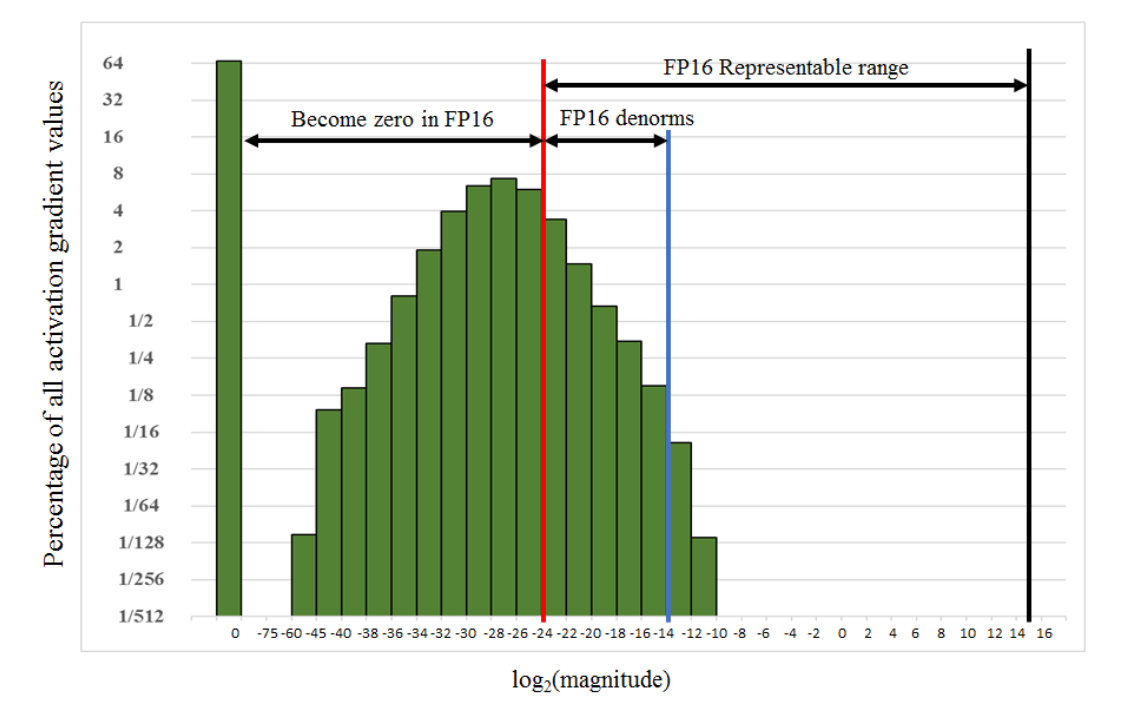
为了让这些梯度能够被FP16表示,可以在计算Loss的时候,将loss乘以一个扩大的系数loss scale,比如1024。这样,一个接近0的极小的数字经过乘法,就能过被FP16表示。这个过程发生在前向传播的最后一步,反向传播之前。
loss scale有两种设置策略:
- loss scale固定值,比如在[8, 32000]之间;
- 动态调整,先将loss scale初始化为65536,如果出现上溢或下溢,在loss scale值基础上适当增加或减少。
高精度运算使用FP32
对于其他一些特定的计算,比如向量求和,尽量使用FP32进行计算,以保证精度。
框架支持
目前主流的深度学习框架都支持了混合精度训练,其实对于用户来说主要就是要选择何种精度来进行计算。以PyTorch为例,其余代码基本没有差别,只是加了torch.cuda.amp.GradScaler和torch.autocast。torch.cuda.amp.GradScaler默认可以动态调整loss scale,torch.autocast自动为不同的算子选择合适的精度。
更加精细的PyTorch混合精度训练方法可以参考PyTorch的文档。
# 创建模型和优化器
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
# 创建`torch.cuda.amp.GradScaler`
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
# 增加`torch.autocast`,将必要的计算从FP32转换为FP16
with autocast(device_type='cuda', dtype=torch.float16):
output = model(input)
loss = loss_fn(output, target)
# Loss Scale
scaler.scale(loss).backward()
# 更新参数
scaler.step(optimizer)
# 更新scaler
scaler.update()
参考文献
P. Micikevicius et al., “Mixed Precision Training,” in 6th International Conference on Learning Representations, ICLR 2018, Vancouver, Canada, 2018. [Online]. Available: https://openreview.net/forum?id=r1gs9JgRZ ↩︎
鲁蔚征, et al., “华为昇腾神经网络加速器性能评测与优化,” 计算机学报, vol. 45, no. 08, pp. 1618–1637, 2022. ↩︎