深度学习编译
深度学习编译已经成为当前各个主流深度学习的标配。例如,PyTorch 2.x的 torch.compile,TensorFlow 2.x 的 tf.function。深度学习编译的流行主要因为两种原因:
- 深度学习编译可明显提升训练和推理速度:深度学习编译过程进行了大量优化,优化过后的程序能更好地运行在硬件上。
- 深度学习加速器硬件层出不穷,上层软件为每种加速器硬件都进行编程适配的工作量太大,深度学习编译器是一种中间层,尽量减少上层软件开发的成本。
深度学习编译器
在整个深度学习软硬件栈中,深度学习编译器处于深度学习框架和底层硬件之间,它提供了一种中间层,可以覆盖不同的加速器硬件。下图中,Graph Level和Kernel Level都是深度学习编译器所希望做的事情。
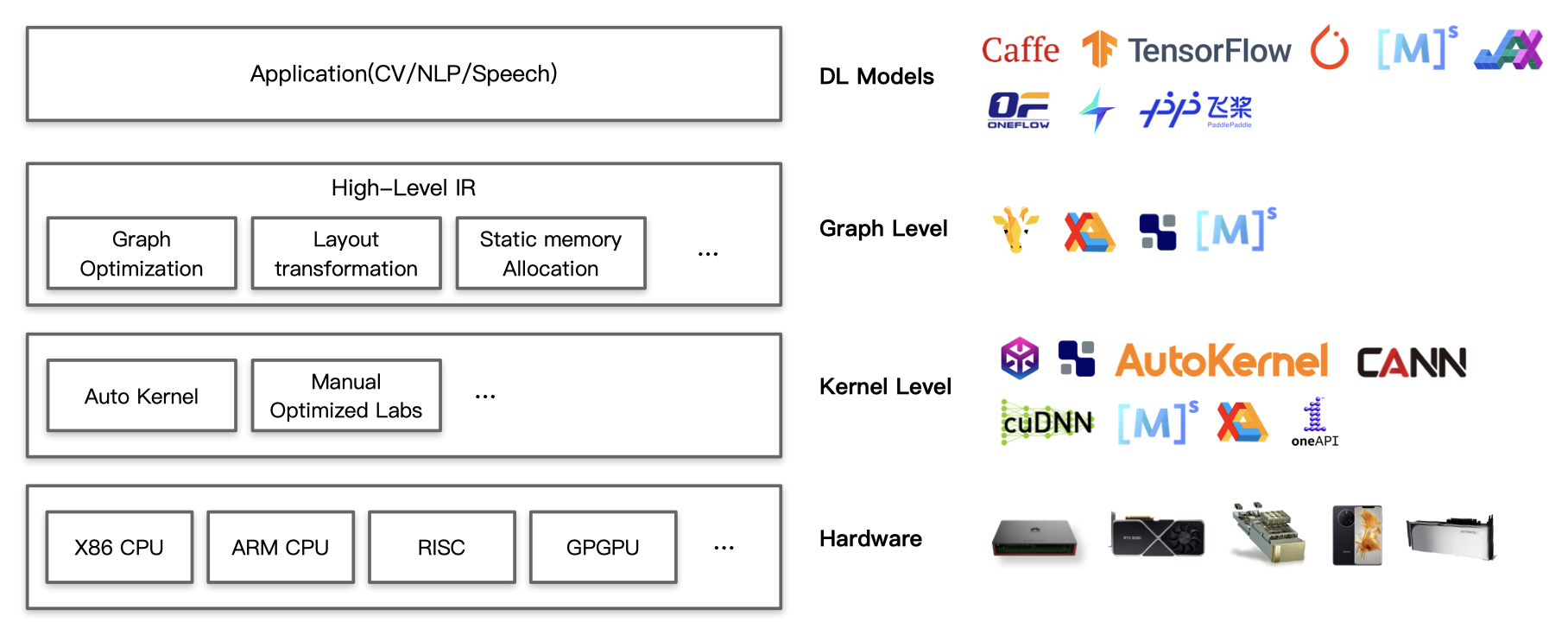
如果对软硬件栈不熟悉,这张图给人感觉比较抽象,我们仍然不是很了解深度学习编译器到底做了什么。这里给出一些具体的例子。
IR:中间表示
深度学习编译器领域出现最多的一个词就是IR,英文全称是Intermediate Representation(中间表示)。IR这个词给人一种高大上的感觉,实际上IR类似下面的代码:
%add_float_.52 (x.53: f32[], y.54: f32[]) -> f32[] {
%x.53 = f32[] parameter(0)
%y.54 = f32[] parameter(1)
ROOT %add.55 = f32[] add(f32[] %x.53, f32[] %y.54)
}
这是一段Google深度学习编译器XLA编译出来的IR[1],这种IR是Google自己定义的一套特定的格式,Google称其为HLO(High Level Optimizer)。咋一看有点像汇编,但又不是汇编;有点像编程语言的函数,但又貌似比编程语言的函数复杂。IR确实就是介于编程语言和汇编之间的东西。仔细看这个代码,它要做的事情是对两个float32数值进行加法运算。可以认为“函数名”是“add_float_.52”,“函数输入”是“x.53”和“y.54”,“函数”最后返回的是两个输入的加法。
IR的这种形式其实叫做SSA(Static Single Assignment,静态单赋值)。静态单赋值指的是:每个变量都有且只有一个赋值语句。IR并不是因为深度学习才出现的,早在深度学习兴起之前,编译器领域就已经开始广泛采用了,最著名的当属LLVM。LLVM是一种介于不同上层语言和不同下层的编译器。就算有不同的上层语言(C/C++、Fortran、Haskell、Julia...),LLVM都可以把程序员所写的上层语言代码转化成IR。因为虽然上层语言不一样,但是程序员所想表达的逻辑是近乎相同的,这些业务逻辑可以被表示成IR,IR再被编译到不同的硬件上。
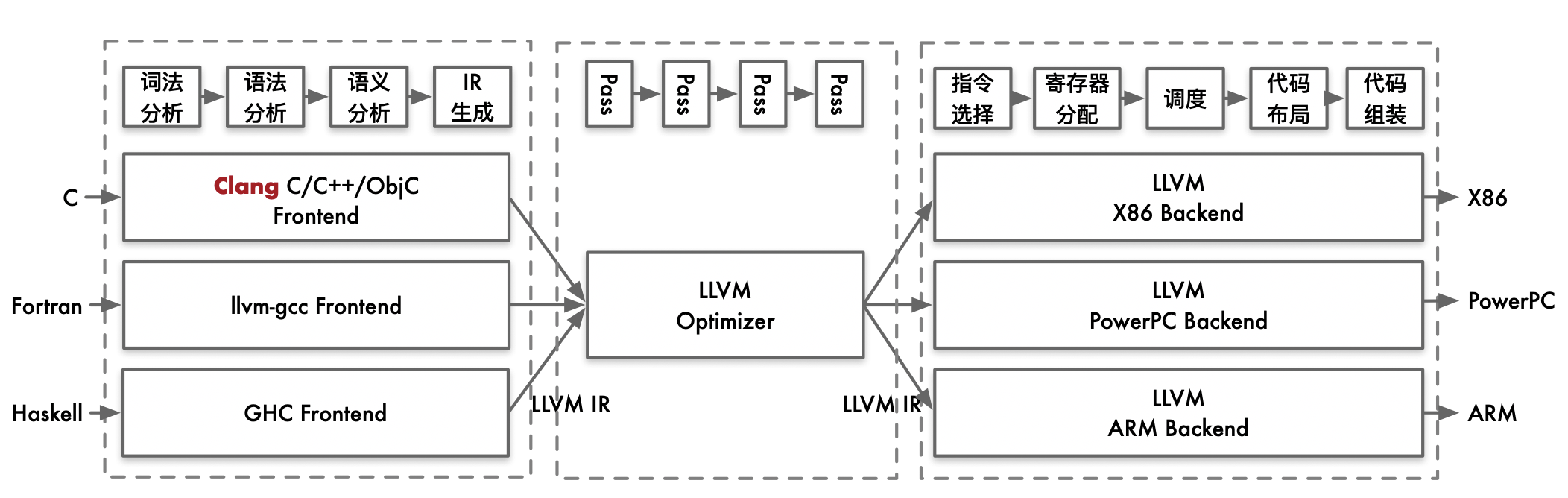
一个LLVM的IR如下所示,这段代码进行了乘法和加法的计算。
%e = mul i32 %a, %b
%c = add i32 %a, %b
IR再经过多次优化,可以被编译成不同的硬件平台上的可执行代码。不同的优化被称为Pass。最后,硬件厂商可以将自己的加法和乘法计算实现贡献到LLVM社区,LLVM就可以实现可执行文件的编译。
前端优化:从计算图到IR
在深度学习领域,通常使用计算图来表示计算,深度学习编译器将计算图转化为优化过的IR,并进一步转化为高性能的程序。下图[2]使用Google JAX先生成(a)的计算图,再经过一系列优化,生成(b)和(c)的HLO IR表示。
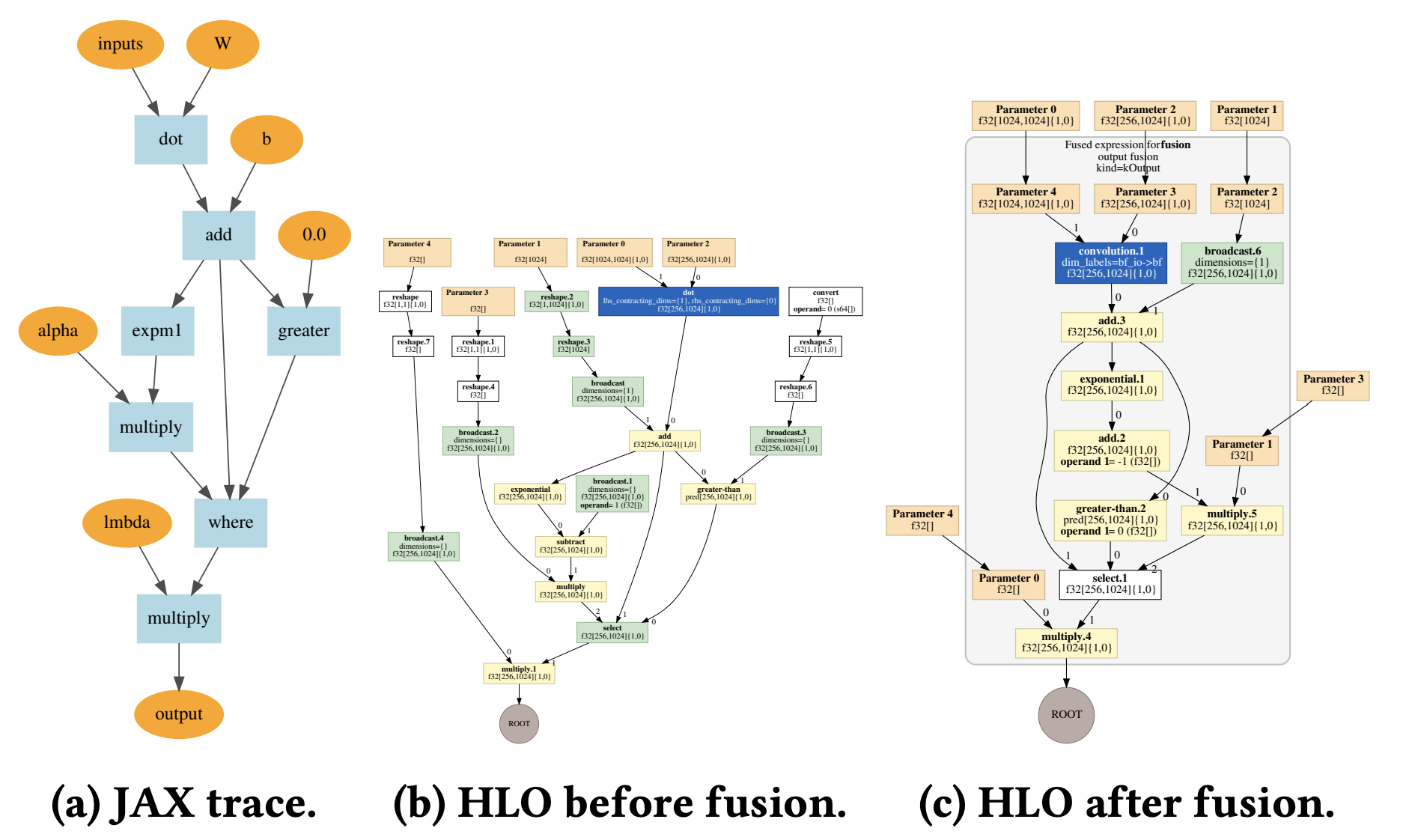
(a)的计算图进行的是:
(b)是将这个计算图转化成的HLO IR,此时的IR还未进行任何优化。(c)是对这个计算图进行了优化,这里使用了算子融合技术,将矩阵乘法和激活函数的计算SeLU融合到灰色方框的计算。
前端优化主要关注计算图整体拓扑结构,而不关心算子的具体实现,主要包括:对算子进行融合、消除、化简等操作,使计算图的计算和存储开销最小。
前端优化通常是将用户定义的计算图转化为图级别(Graph Level)的IR,这些优化通常有几十甚至上百个,也就是说一个初始的计算图要经过几十种优化,才能得到一个优化后的IR。这些优化主要有几类:
- 相邻算子算子融合(Operator Fusion)等
- 死代码消除(Dead Code Elimination,DCE)
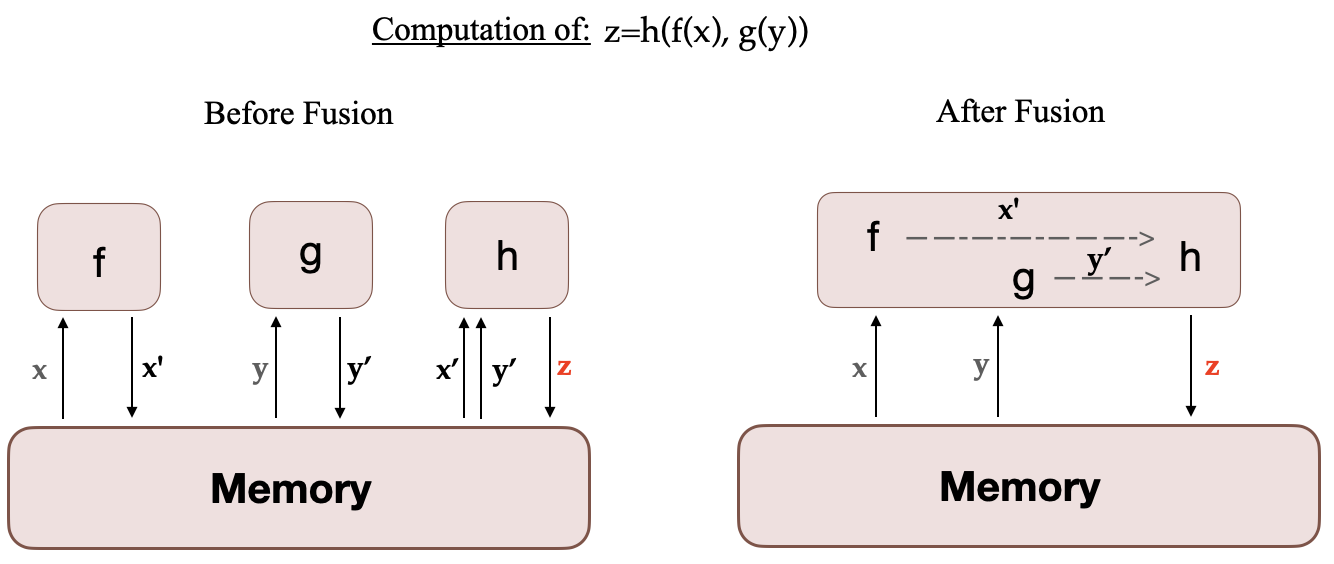
优化的收益很大,其中收益最大的优化是相邻间算子融合。算子融合可以减少算子的个数。如下图[3]所示,原本需要3个GPU Kernel,在GPU上启动3次核函数,调用多次内存读写,现在经过算子融合之后,合并为1个GPU Kernel,调用更少次数的内存读写。深度学习里使用最多的是 Conv + ReLU + BatchNorm 和 GEMM + BiasAdd + ReLU 这两类融合。
另外两个经常用到的优化是死代码消除(Dead Code Elimination,DCE)和公共子表达式消除(Common Subexpression Elimination,CSE)。DCE就是消除用户代码中写的,但实际计算中根本没有使用到的代码。CSE是把多个相同的公共表达式提出取来进行复用。例如:
a = b * c + g
d = b * c + e
b * c是公共的表达式,可以提取出来,不需要计算2次:
temp = b * c
a = temp + g
d = temp + e
后端优化:图IR到可执行文件
后端优化关注IR图中每个算子节点的内部具体实现,针对不同的硬件使得性能达到最优。这些优化重点关心每个节点的输入,输出,以及计算的逻辑。
相比前端优化,后端优化更偏向硬件和芯片,需要开发者非常熟悉芯片设计架构。以卷积为例,卷积的实现有很多种算法,在什么场景(输入、输出)下使用什么算法,以取得最优的性能?
一种做法是提供常用算子库:NVIDIA的cuBLAS和cuDNN,Intel的oneAPI。这些算子库中的卷积、矩阵乘法等常用算子经过了高度手工优化,针对某种特定的输入输出,它会选择最优的算法。当然,这种做法非常耗费人力,只有大厂才有实力;而且移植性差,NVIDIA的算子库无法应用给Intel。
另一种方法是自动化生成算子。很多顶级研究团队都在专注于自动化代码生成,发表了很多论文,比如TVM、MindSpore等。不过,自动化生成的理想很丰满,但在一些特定场景仍然无法跟手工优化的算子相比。
框架支持
深度学习编译的技术确实很复杂。但对于用户来说,可以不用深究,深度学习框架已经帮我们做好了,只需要加一行代码就行。比如:将torch.compile 和 tf.function包裹到训练的一个step函数上就好了。
参考文献
Compiling machine learning programs via high-level tracing ↩︎
J. Filipovič, M. Madzin, J. Fousek, and L. Matyska, “Optimizing CUDA code by kernel fusion: application on BLAS,” The Journal of Supercomputing, vol. 71, no. 10, pp. 3934–3957, Oct. 2015, doi: 10.1007/s11227-015-1483-z. ↩︎