Softmax
Softmax是一种激活函数,它可以将一个数值向量归一化为一个概率分布向量,且各个概率之和为1。Softmax可以用来作为神经网络的最后一层,用于多分类问题的输出。Softmax层常常和交叉熵损失函数一起结合使用。
从二分类到多分类
对于二分类问题,我们可以使用Sigmod函数(又称Logistic函数)。将范围内的数值映射成为一个区间的数值,一个区间的数值恰好可以用来表示概率。
比如,在互联网广告和推荐系统中,曾广泛使用Sigmod函数来预测某项内容是否有可能被点击。Sigmoid函数输出值越大,说明这项内容被用户点击的可能性越大,越应该将该内容放置到更加醒目的位置。
除了二分类,现实世界往往有其他类型的问题。比如我们想识别手写的阿拉伯数字0-9,这就是一个多分类问题,需要从10个数字中选择一个概率最高的作为预测结果。

对于多分类问题,一种常用的方法是Softmax函数,它可以预测每个类别的概率。对于阿拉伯数字预测问题,选择预测值最高的类别作为结果即可。Softmax的公式如下,其中是一个向量,和是其中的一个元素。
下图中,我们看到,Softmax将一个的向量转化为了,而且各项之和为1。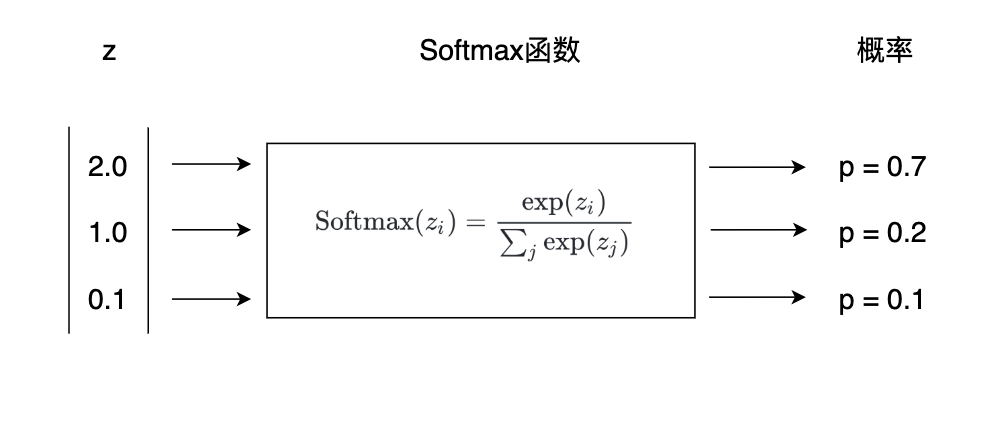
Softmax函数可以将上一层的原始数据进行归一化,转化为一个之间的数值,这些数值可以被当做概率分布,用来作为多分类的目标预测值。Softmax函数一般作为神经网络的最后一层,接受来自上一层网络的输入值,然后将其转化为概率。
下图为VGG16网络,是一个图像分类网络,原始图像中的数据经过卷积层、池化层、全连接层后,最终经过Softmax层输出成概率。
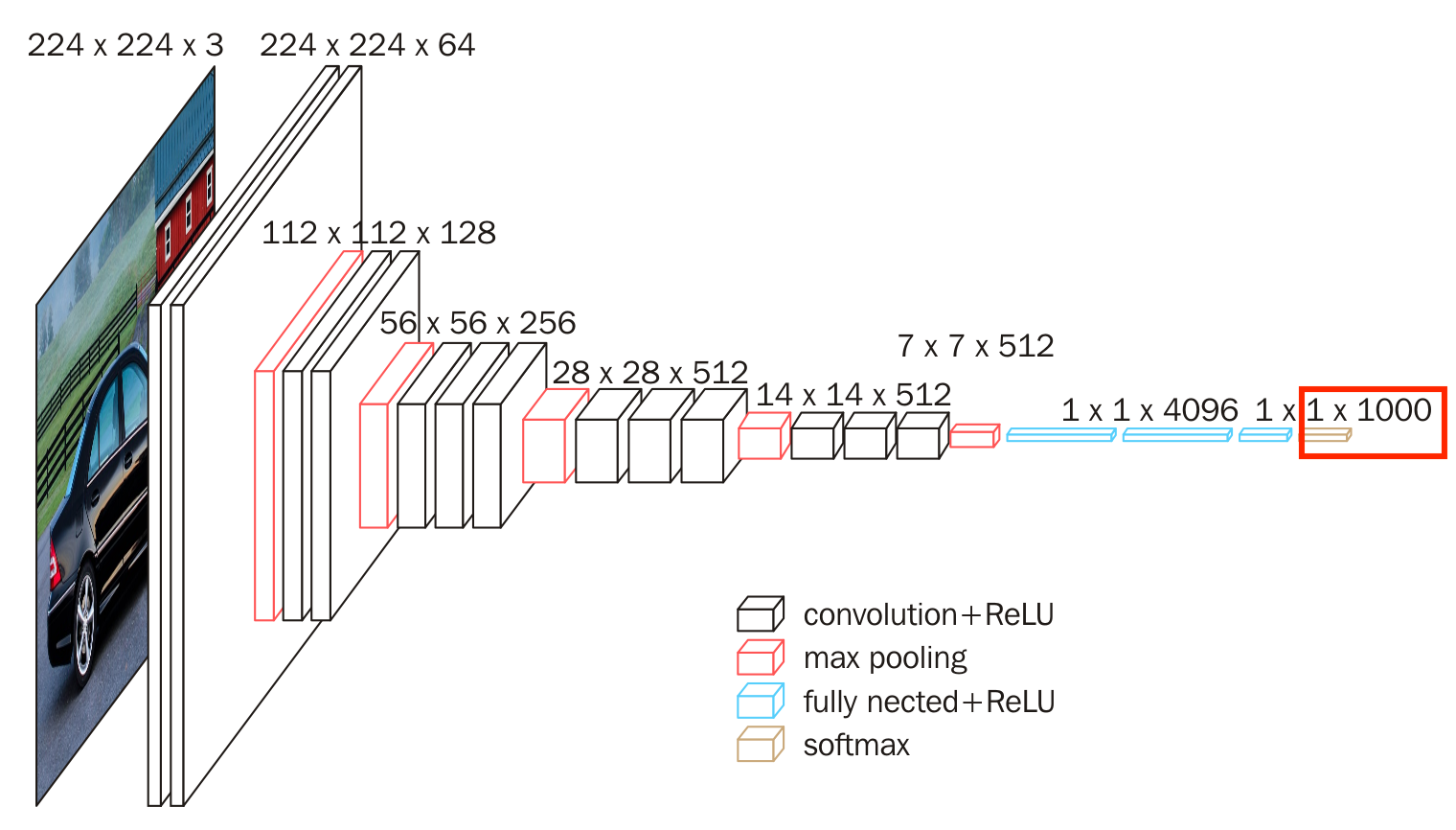
实际上,Sigmod函数是Softmax函数的一个特例,Sigmod函数只能用于预测值为0或1的二元分类。
指数函数
Softmax函数使用了指数,对于每个输入,需要计算的指数。在深度学习进行反向传播时,我们经常需要求导,指数函数求导比较方便:。
我们可以用NumPy实现一个简单的Softmax:
def softmax(x):
return np.exp(x) / np.sum(np.exp(x), axis=0)
对于下面的输入,可以得到:
a = np.asarray([2, 3, 5])
softmax(a)
array([0.04201007, 0.1141952 , 0.84379473])
如果不使用指数,单纯计算百分比:
def percentile(x):
return x / np.sum(x, axis=0)
得到的结果为:
percentile(a)
array([0.2, 0.3, 0.5])
指数函数在x轴正轴的变化非常明显,斜率越来越大。x轴上一个很小的变化都会导致y轴非常大的变化。相比求和计算百分比的方式:,指数能把一些数值差距拉大。
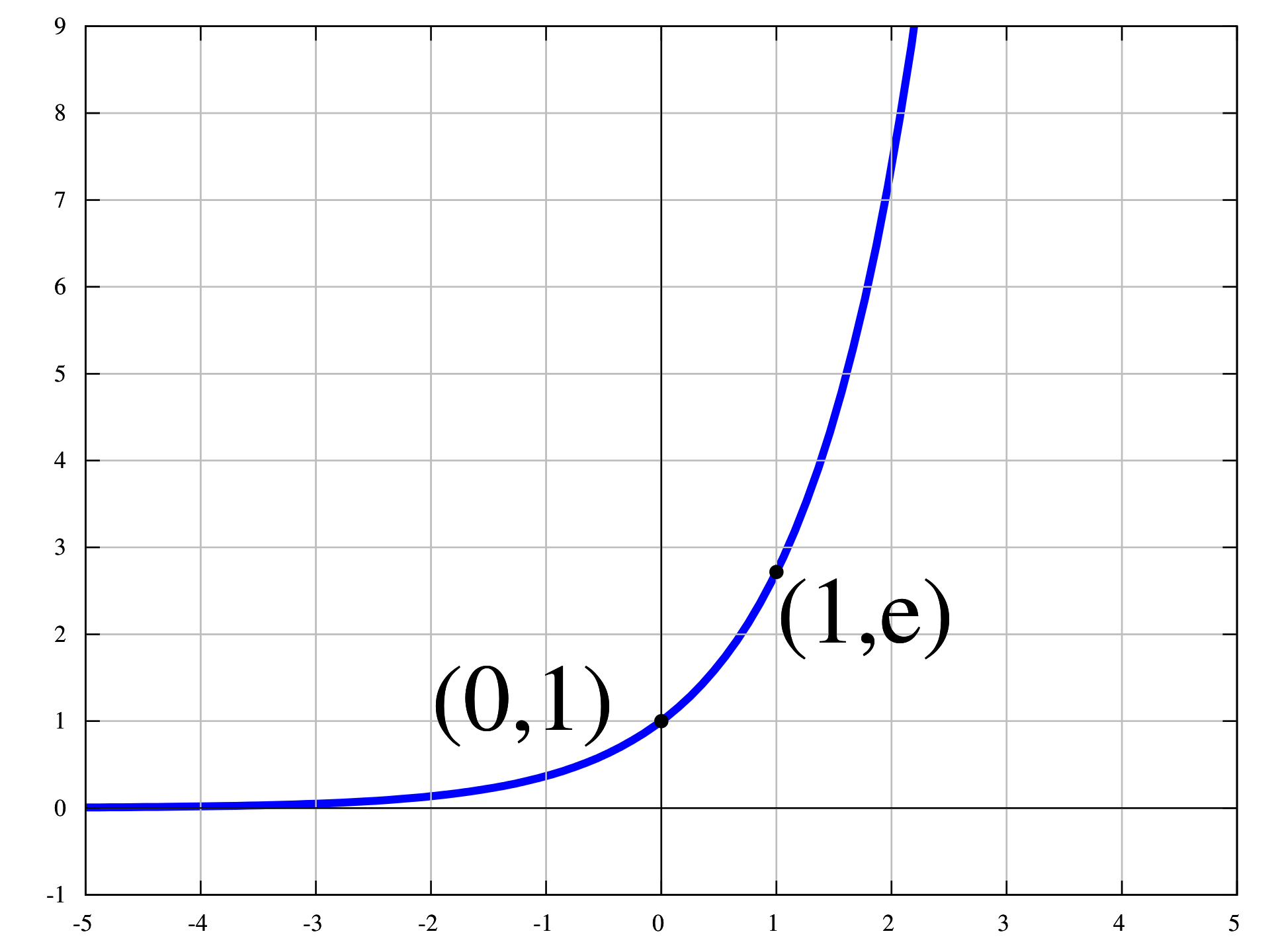
指数函数
但正因为指数在x轴正轴爆炸式地快速增长,如果比较大,也会非常大,得到的数值可能会溢出。溢出又分为下溢出(Underflow)和上溢出(Overflow)。计算机用一定长度的二进制表示数值,数值又被称为浮点数。当数值过小的时候,被四舍五入为0,这就是下溢出;当数值过大,超出了最大界限,就是上溢出。
比如,仍然用刚才那个NumPy实现的简单的Softmax:
b = np.array([20, 300, 5000])
softmax(b)
会报错:
RuntimeWarning: overflow encountered in exp return np.exp(x) / np.sum(np.exp(x), axis=0)
一个简单的办法是,先求得输入向量的最大值,然后所有向量都减去这个最大值:
参考资料