神经元模型与神经网络
在生物神经网络中,一个神经元(Neuron,又被称为Unit)会和多个神经元相连,当神经元兴奋时,它会向相连的神经元发送化学物质,进而改变相连神经元的电位;如果某个神经元的电位超过了阈值(Threshold),这个神经元被激活为兴奋状态,再进而向其他神经元发送化学物质。机器学习领域的神经网络(Neural Network)模型借鉴了生物学的一些思想。
下图左侧是神经元的生物学表示,神经元会接受来自树突(Dendrite)的信号,会沿着轴突(Axon)向下发送信号。轴突会继续和下游神经元通过突触(Synapse)相连。
下图右侧是机器学习领域对神经网络的建模。中间部分是当前神经元,左侧是与之相连的上层神经元,当前神经元接收到来自上层神经元的输入信号x。两层神经元之间有连接权重w,权重和输入信号相乘,上层神经元的信号通过连接权重传递下去。权重是可以学习的,权重控制着上层信号对其影响,如果权重为正数,表示更易兴奋,权重为负数,表示该路信号被抑制。当前神经元将接收到的各路输入值求和,所得的和与神经元的阈值进行比较,然后通过激活函数(Activation Function),生成输出。真实的神经元的激活原理更复杂,一方面要依据电位阈值,另一方面还要控制激活时间。机器学习中的激活函数做了精简,不去控制激活时间。
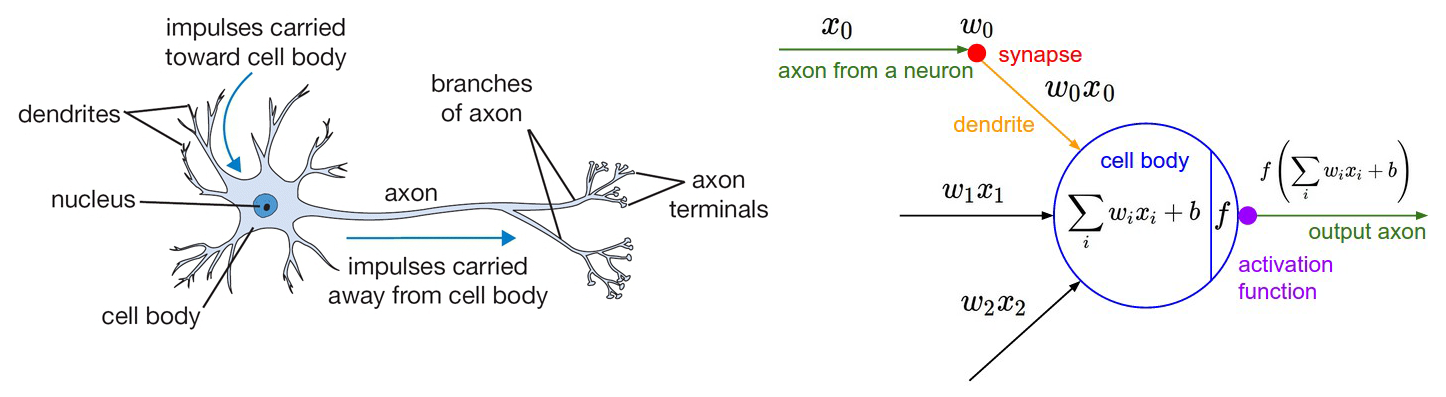 图1 神经元模型
图1 神经元模型在生物神经系统中,神经元不止一种,一路信号肯定不是一个权重值就能控制的,而且神经元能实现很多非线性的激活函数,激活时间也是可以控制的,这个时间对于神经系统非常重要。总之,生物神经元是一个复杂的、动态的、非线性的系统,显然机器学习的神经元模型做了大量精简。
把许多这样的神经元按照一定层次结构连接起来,就得到了神经网络。下图是一种神经网络,图中有3维特征。最左侧是输入数据,被称为输入层(Input Layer),最右侧是输出数据,被称为输出层(Output Layer),中间层不直接与输入输出相连,常被称为隐藏层(Hidden Layer)。
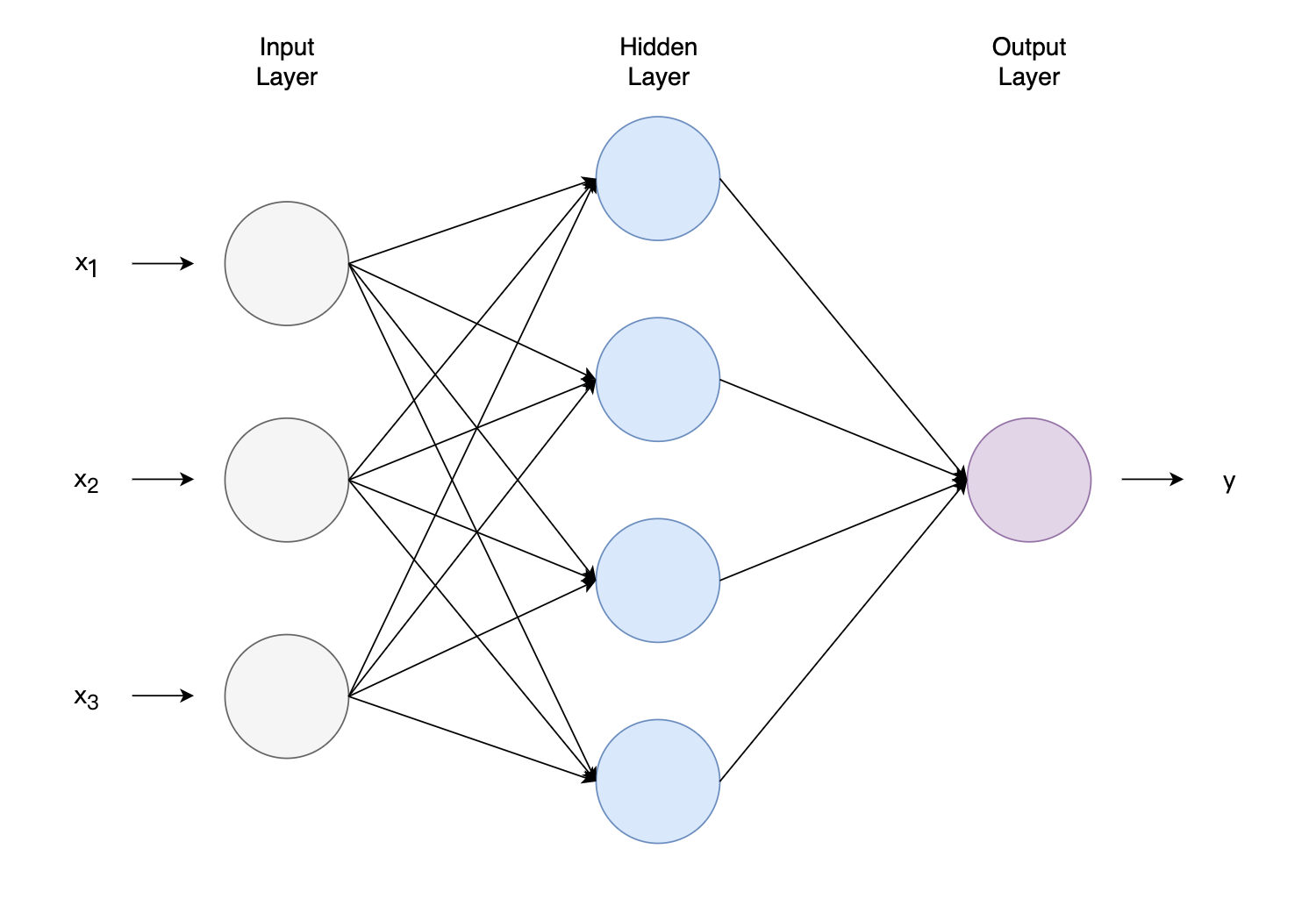 图2 神经网络
图2 神经网络我们用g(z)表示激活函数,常见的激活函数有:
g(z)g(z)g(z)=1+exp(−z)1(sigmoid)=max(z,0)(ReLU)=ez+ezez−ez(tanh)
这些激活函数的形状如下图所示:
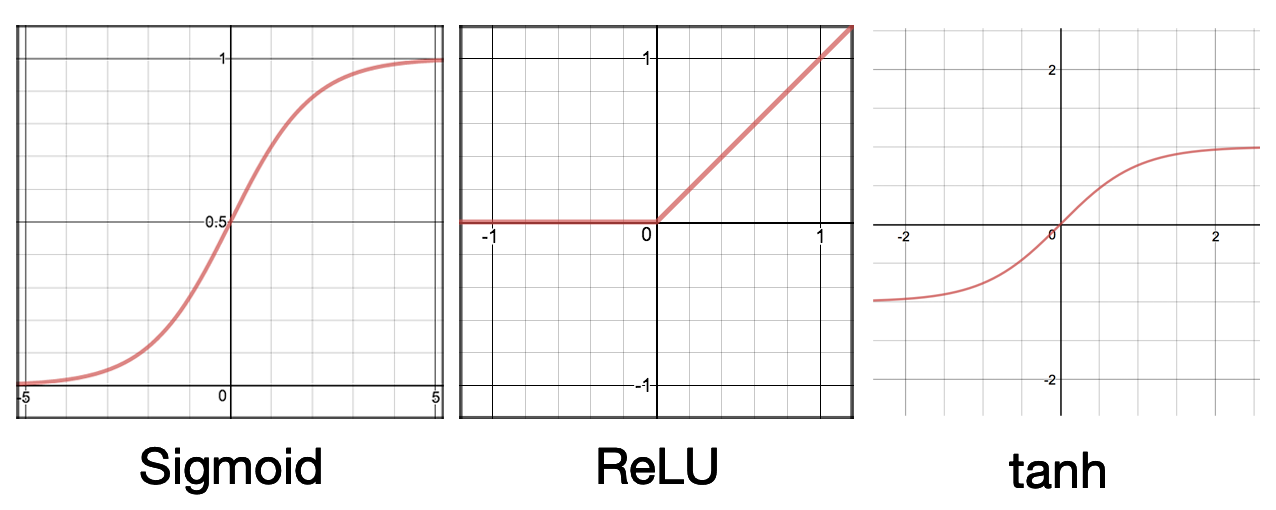 图3 常见激活函数
图3 常见激活函数Sigmoid函数或者又称为Logistic函数,我们曾在Logistic Regression中介绍过,它将(−∞,+∞)的输入压缩到了0和1之间。经过Sigmoid函数后,较大的负数会接近0,较大的正数会接近1。Sigmoid函数的这些特征可以很好地解释神经元模型,0表示不产生兴奋,1表示产生兴奋。早期的神经网络喜欢使用Sigmoid函数作为激活函数,但Sigmoid函数也有一些弊端,现在的神经网络几乎不再使用它了。Logistic Regression使用了Sigmoid函数,Logistic Regression又被认为是一种非常简单的神经网络。
前馈神经网络
图2是一种最简单的神经网络,网络的输入层向前传播影响到了隐藏层,隐藏层进一步向前传播影响到输出层,这种网络又被成为前馈神经网络(Feedforward Neural Network),有些地方也会称之为多层感知机(Multilayer Perceptron,MLP)。前馈神经网络中数据是从输入层到输出层按照一个方向流动的,中间没有任何循环,这种前向传播的网络区别于循环神经网络。
向量化表示
继续以图2中的网络为例,网络的输入是一个3维向量x,隐藏层的各个节点接受来自x的输入,求和后得到z,经过激活函数,输出为a。
在多层神经网络中,区分哪一层非常有必要。以下公式中,方括号[]表示该参数属于哪一层,本例中只有一个隐藏层,用[1]表示。
z1[1]=W1[1]Tx+b1[1]a1[1]=g(z1[1])⋮z4[1]=W4[1]Tx+b4[1]a4[1]=g(z4[1])
数据经过隐藏层,得到一个4维的输出向量a[1]:
a[1]=a1[1]a2[1]a3[1]a4[1]
将这个向量a[1]发送到输出层:
z[2]=W[2]a[1]+b[2]a[2]=g(z[2])
公式中用[2]表示输出层(第2层)的参数。输出层是一个1维的标量a[2],它表示最终的预测结果。
对于上述计算,首先想到的是使用for循环,但是for循环的并行效率并不高。在神经网络中,我们应该尽量避免使用for循环,而应该将计算向量化。很多CPU和GPU程序针对向量化计算进行过优化。用向量表示隐藏层的计算过程为:
z[1]=W[1]x+b[1]a[1]=g(z[1])
具体拆解为:
z1[1]⋮⋮z4[1]=−W1[1]T−−W2[1]T−⋮−W4[1]T−x1x2x3+b1[1]b2[1]⋮b4[1]
输出层的计算过程为:
z[2]=W[2]a[1]+b[2]a[2]=g(z[2])
训练集批量计算
以上推导基于单个样本,数据从输入层出发,前向传播。实际计算中,一般是对一个训练集的多个样本批量计算得到最终结果。在以下公式中,我们开始用圆括号()表示训练集中第i个样本,X下某个样本为x(i),这个样本的第1维特征为:x1(i)。
假如训练集有三个样本,那么:
z[1](1)z[1](2)z[1](3)=W[1]x(1)+b[1]=W[1]x(2)+b[1]=W[1]x(3)+b[1]
单个样本是个列向量,我们将单个样本按列拼接为一个矩阵,得到矩阵X:
X=∣x(1)∣∣x(2)∣∣x(3)∣
对矩阵X我们使用z[1]=W[1]x+b[1]进行计算,向量化表示为:
Z[1]=∣z[1](1)∣∣z[1](2)∣∣z[1](3)∣=W[1]X+b[1]
反向传播算法
神经网络通常使用反向传播算法(Back Propagation,又称BP算法)。
我们仍然以前面的网络为例,输入层是一个3维的向量,输出是一个1维的标量。对于训练集中的单个样本(x(i),y(i)),产生的均方误差为:
L=21(y^(i)−y(i))2
这里的21是为了方便求导,y^表示模型预测值,y为真实值。
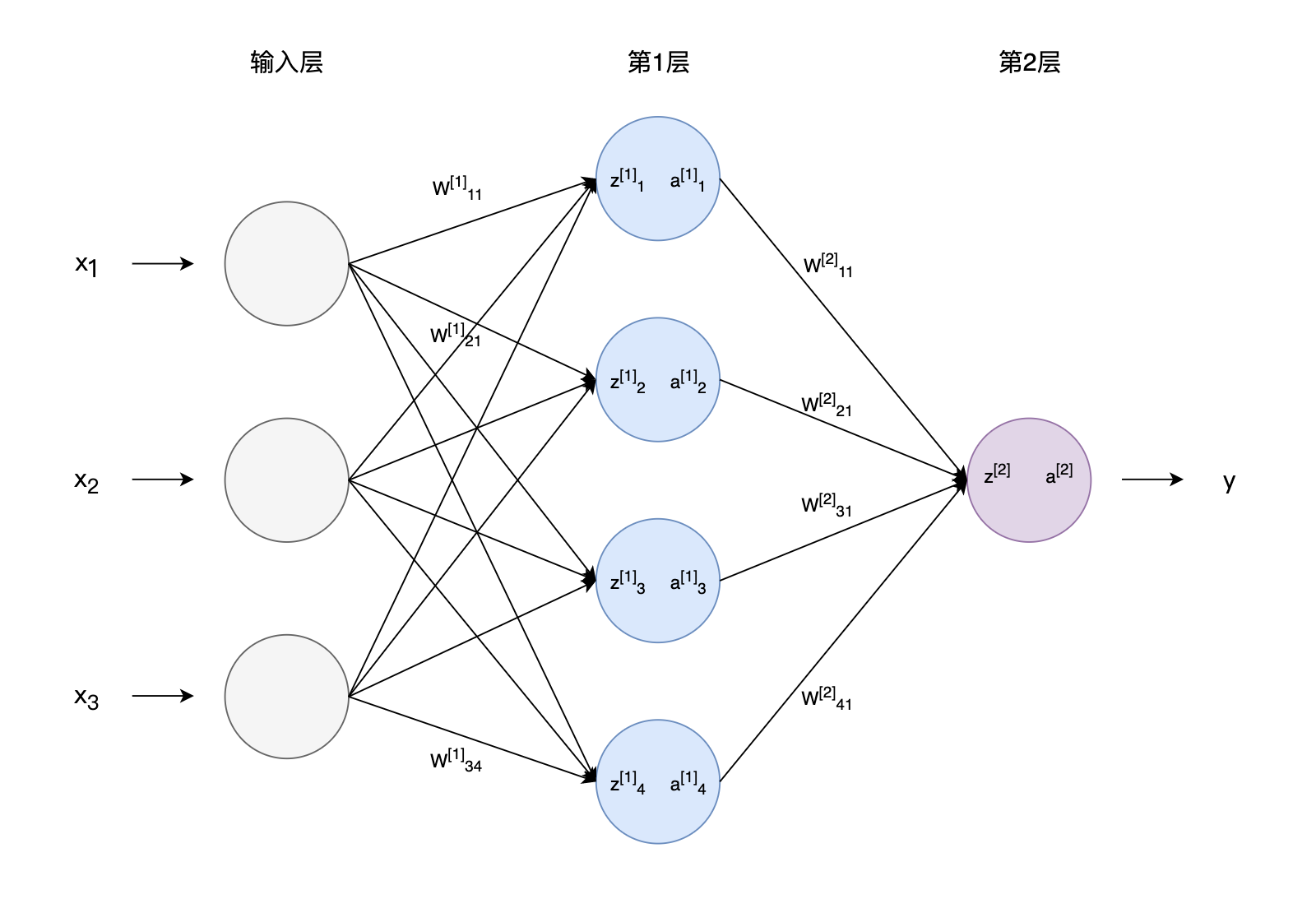 图4 神经网络中各参数符号表示
图4 神经网络中各参数符号表示我们继续使用梯度下降法来更新模型中的各类参数,模型的参数包括输出层(第2层)的W[2]和b[2],隐藏层(第1层)的W[1]和b[1]。对任意的一个给定的网络层次l,该层下的参数更新方法如下所示,其中α为学习率。
W[l]b[l]=W[l]−α∂W[l]∂L=b[l]−α∂b[l]∂L
使用梯度下降法,最关键的一步是要得到对应参数的梯度:∂W[l]∂L和∂b[l]∂L。我们先求解第2层中的参数W11[2],该参数连接了第1层第1个节点和第2层唯一的节点,下角标的11表示第一层的第1个节点和第二层第一个节点。注意到,参数W11[2]首先影响到第二层的求和项z[2],再影响到输出值y^=a[2]=g(z[2])。下面计算梯度的公式中,我们应用了微积分中的链式法则(Chain Rule)。
∂W11[2]∂L=∂a[2]∂L⋅∂z[2]∂a[2]⋅∂W11[2]∂z[2]=∂a[2]∂[21(y^(i)−y(i))2]⋅g′(z[2])⋅a1[1]=(y^(i)−y(i))⋅g′(z[2])⋅a1[1]
这个公式的求导分为三个部分:第一部分∂a[2]∂L是平方误差对a[2]求导;第二部分∂z[2]∂a[2],由于 a=g(z),所以这部分主要是对激活函数求导;最后一部分由于z[2]=W[2]a[1]+b[2],∂W11[2]∂z[2]=a1[1]。这三部分中, (y^(i)−y(i)) 是误差项,是可以直接计算得到的;g′(z[2]) 是激活函数的导数,如果激活函数是Sigmoid,有 g′(z)=g(z)(1−g(z)) ,这部分也是可以计算得到的;最后一部分 a1[1] 是前向传播过程中计算过的。可见,在求梯度时,我们先要应用前向传播,得到 a[1]、z[2]、y^(i) 的值,将这些值代入梯度公式,可以得到W11[2]当前的梯度。按照这个思路,我们也可以得到W[2]其他分量的梯度。
如果我们想进一步求第1层的W[1]的梯度,比如其中的W21[1]的梯度,我们可以继续应用链式法则。我们知道,损失函数L依赖于第2层,第2层又依赖于第1层。
∂W21[1]∂L=∂a[2]∂L⋅∂z[2]∂a[2]⋅∂a1[1]∂z[2]⋅∂z1[1]∂a1[1]⋅∂W21[1]∂z1[1]=(y^(i)−y(i))⋅g′(z[2])⋅W11[2]⋅g′(z1[1])⋅x2(i)
我们得到了W[1]在x2分量上的梯度,其他分量的梯度也可以按此方式计算得到。当然,我们要把这些公式尽量向量化,这样才能获得并行加速。
学习率α∈(0,1)控制着算法每轮迭代的更新补偿,如果学习率太大则容易振荡,太小则收敛速度又会过慢。
假设我们已经得到了各参数的梯度,接下来就可以使用随机梯度下降法来更新参数。我们刚才的推导是基于单个样本的损失函数,实际一般使用Mini-batch思想,即Mini-batch SGD算法,每次使用一个批次的样本来迭代更新参数。
反向传播BP算法的流程为:
- 在整个训练集中随机选择Mini-batch大小的样本,将样本提供给输入层,逐层前向传播,得到各层各参数。
- 得到各参数的梯度,梯度的计算一般从输出层开始,反向传播。根据这些梯度更新参数。
不断重复迭代上面两步,直到达到停止条件。
使用Mini-batch SGD进行训练时,读取整个训练集一遍被称为一轮(Epoch)。假设一个训练集有1000个样本,一个Mini-batch大小为10,为了让每个样本都能参与到训练中,一轮需要进行100次小批次的参数更新。
我们在这里做了一些梯度相关的推导,其实是想了解那些深度学习框架内部所做的事情。无论是TensorFlow还是PyTorch,这些深度学习框架所做的一项重要工作就是帮我们去做了自动微分求导。
参考资料
- Andrew Ng:CS229 Lecture Notes
- Ian Goodfellow and Yoshua Bengio and Aaron Courville:《Deep Learning》
- 周志华:《机器学习》
- https://cs231n.github.io/neural-networks-1/open in new window
- https://ml-cheatsheet.readthedocs.io/en/latest/open in new window
- 《动手学深度学习》
- https://tangshusen.me/Dive-into-DL-PyTorchopen in new window
- https://datawhalechina.github.io/pumpkin-book/open in new window