BERT
自BERT(Bidirectional Encoder Representations from Transformer)[1]出现后,NLP界开启了一个全新的范式。本文主要介绍BERT的原理,以及如何使用HuggingFace提供的 transformers 库完成基于BERT的微调任务。
预训练
BERT在一个较大的语料上进行预训练(Pre-train)。预训练主要是在数据和算力充足的条件下,训练一个大模型,在其他任务上可以利用预训练好的模型进行微调(Fine-tune)。
训练目标
BERT使用了维基百科等语料库数据,共几十GB,这是一个庞大的语料库。对于一个GB级的语料库,雇佣人力进行标注成本极高。BERT使用了两个巧妙方法来无监督地训练模型:Masked Language Modeling和Next Sentence Prediction。这两个方法可以无需花费时间和人力标注数据,以较低成本无监督地得到训练数据。图1就是一个输入输出样例。
对于Masked Language Modeling,给定一些输入句子(图1中最下面的输入层),BERT将输入句子中的一些单词盖住(图1中Masked层),经过中间的词向量和BERT层后,BERT的目标是让模型能够预测那些刚刚被盖住的词。还记得英语考试中,我们经常遇到“完形填空”题型吗?能把完形填空做对,说明已经理解了文章背后的语言逻辑。BERT的Masked Language Modeling本质上就是在做“完形填空”:预训练时,先将一部分词随机地盖住,经过模型的拟合,如果能够很好地预测那些盖住的词,模型就学到了文本的内在逻辑。
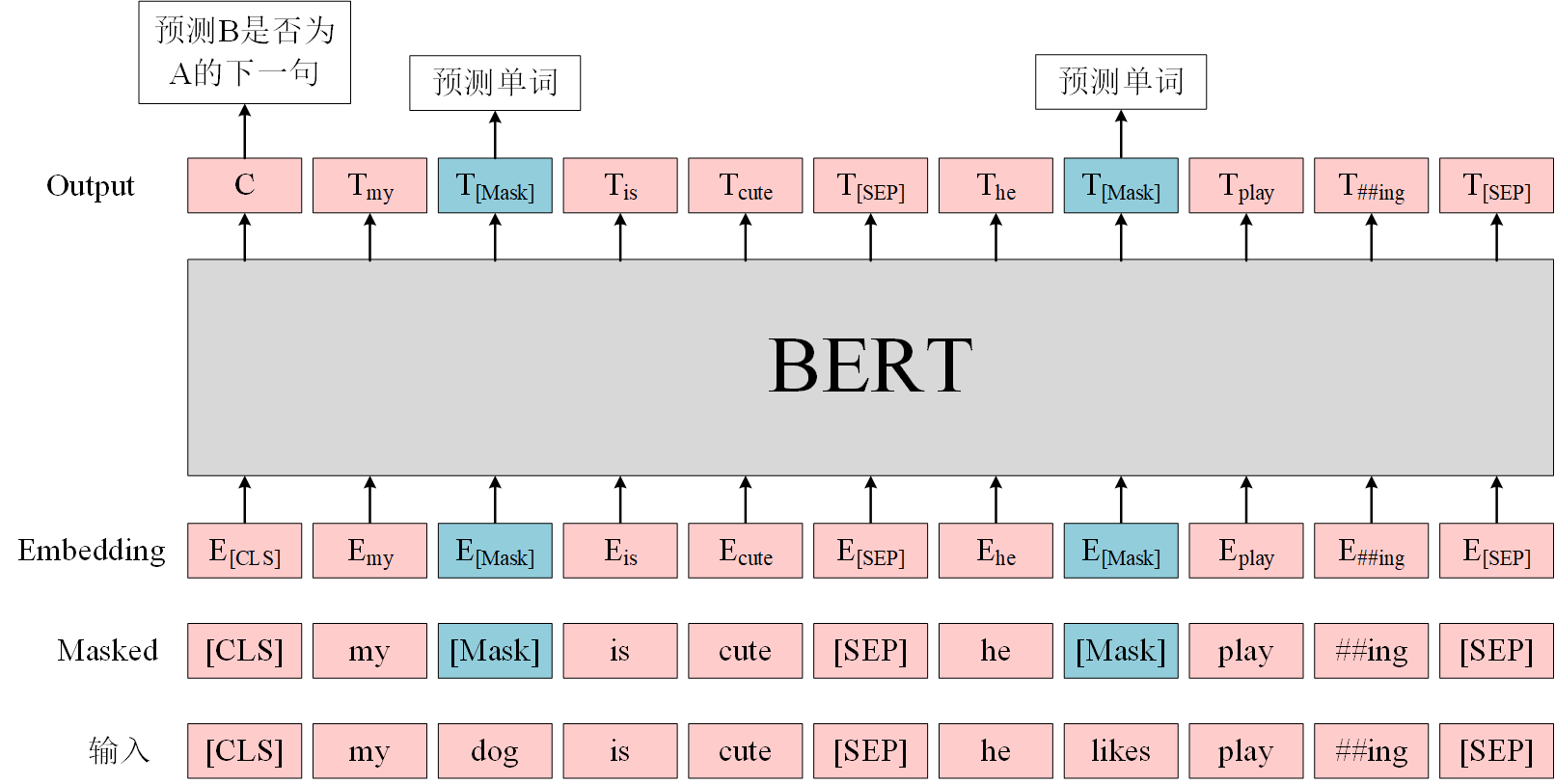
除了“完形填空”,BERT还需要做Next Sentence Prediction任务:预测句子B是否为句子A的下一句。Next Sentence Prediction有点像英语考试中的“段落排序”题,只不过简化到只考虑两句话。如果模型无法正确地基于当前句子预测Next Sentence,而是生硬地把两个不相关的句子拼到一起,两个句子在语义上是毫不相关的,说明模型没有读懂文本背后的意思。
词向量
在基于深度学习的NLP方法中,文本中的词通常都用一维向量来表示。某两个词向量的 Cosine 距离较小,说明两个词在语义上相似。
相关信息
词向量一般由Token转换而成。英文中,一个句子中的词由空格、句号等标点隔开,我们很容易从句子中获得词。英文的词通常有前缀、后缀、词根等,在获得英文的词后,还需要抽出词根,比如图1所展示的,将“playing”切分为“play”和“##ing”。如果不对英文词进行类似词根抽取,词表过大,不容易拟合。对于英文,“play”和“##ing”分别对应两个Token。
中文一般由多个字组成一个词,传统的中文文本任务通常使用一些分词工具,得到严格意义上的词。在原始的BERT中,对于中文,并没有使用分词工具,而是直接以字为粒度得到词向量的。所以,原始的中文BERT(bert-base-chinese)输入到BERT模型的是字向量,Token就是字。后续有专门的研究去探讨,是否应该对中文进行必要的分词,以词的形式进行切分,得到向量放入BERT模型。
为了方面说明,本文不明确区分字向量还是词向量,都统称为词向量。
我们首先需要将文本中每个Token都转换成一维词向量。假如词向量的维度为hidden_size,句子的Token长度为seq_len,或者说句子共包含seq_len个Token,那么上图中,输入就是seq_len * hidden_size。再加上batch_size,那么输入就是batch_size * seq_len * hidden_size。上图只展示了一个样本,未体现出batch_size,或者可以理解成batch_size = 1,即每次只处理一条文本。为便于理解,本文的图解中不考虑batch_size这个维度,实际模型训练时,batch_size通常大于1。
词向量经过BERT模型一系列复杂的转换后,模型最后仍然以词向量的形式输出,用以对文本进行语义表示。输入的词向量是seq_len * hidden_size,句子共seq_len个Token,将每个Token都转换成词向量,送入BERT模型。经过BERT模型后,得到的输出仍然是seq_len * hidden_size维度。输出仍然是seq_len的长度,其中输出的i 个位置(0 < i < seq_len)的词向量,表示经过了拟合后的第i个Token的语义表示。后续可以用输出中每个位置的词向量来进行一些其他任务,比如命名实体识别等。
除了使用Masked方法故意盖住一些词外,BERT还加了一些特殊的符号:[CLS]和[SEP]。[CLS]用在句首,是句子序列中i = 0位置的Token。BERT认为输出序列的i = 0位置的Token对应的词向量包含了整个句子的信息,可对整个句子进行分类。[SEP]用在分割前后两个句子上。
微调
经过预训练后,得到的模型可以用来微调各类任务。
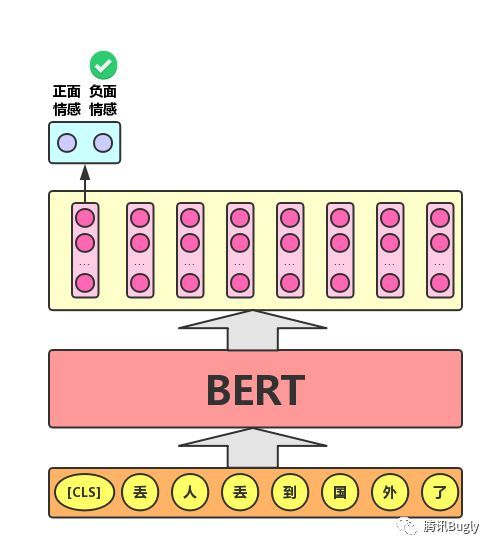
- 单文本分类任务。刚才提到,BERT模型在文本前插入一个
[CLS]符号,并将该符号对应的输出向量作为整篇文本的语义表示,用于文本分类,如图2所示。对于[CLS]符号,可以理解为:与文本中已有的其它字/词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个字/词的语义信息。
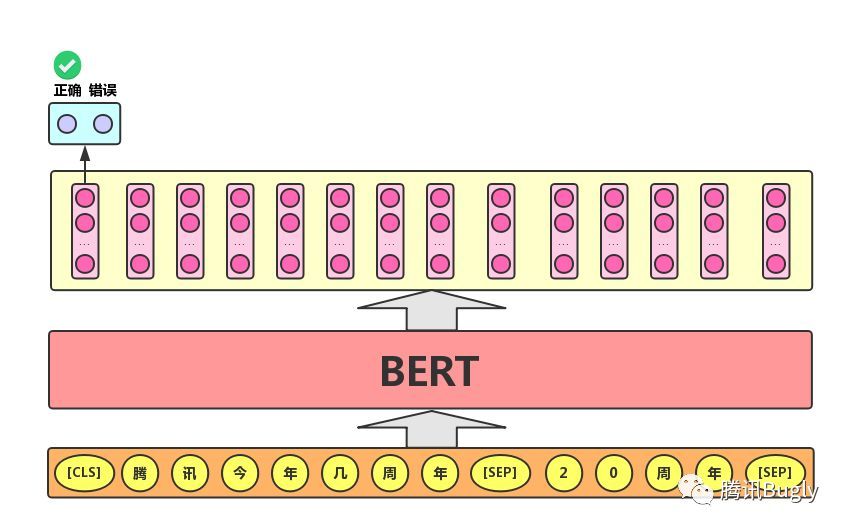
- 语句对分类任务。语句对分类任务的实际应用场景包括:问答(判断一个问题与一个答案是否匹配)、语句匹配(两句话是否表达同一个意思)等。对于该任务,BERT模型除了添加
[CLS]符号并将对应的输出作为文本的语义表示,输入两句话之间用[SEP]符号作分割。
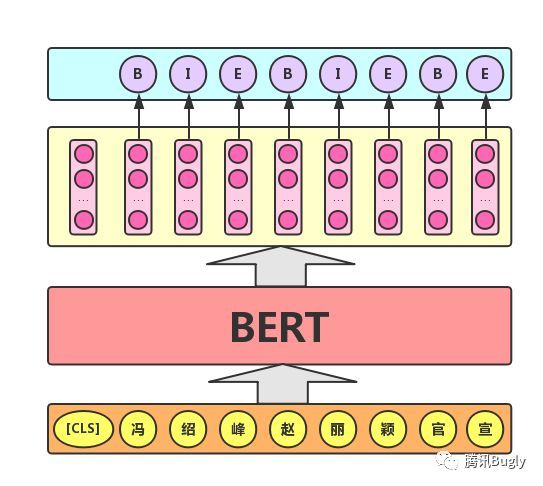
- 序列标注任务。序列标注任务的实际应用场景包括:命名实体识别、中文分词、新词发现(标注每个字是词的首字、中间字或末字)、答案抽取(答案的起止位置)等。对于该任务,BERT模型利用文本中每个Token对应的输出向量对该Token进行标注(分类),如下图所示(B(Begin)、I(Inside)、E(End)分别表示一个词的第一个字、中间字和最后一个字)。
模型结构
Transformer是BERT的核心模块,Attention注意力机制又是Transformer中最关键的部分。前两篇文章,我们介绍了Attention注意力机制和Transformer,这里不再赘述。BERT用到的主要是Transformer的Encoder,没有使用Transformer Decoder。
把多个Transformer Encoder组装起来,就构成了BERT。在论文中,作者分别用12个和24个Transformer Encoder组装了两套BERT模型,两套模型的参数总数分别为110M和340M。
HuggingFace Transformers
使用BERT和其他各类Transformer模型,绕不开HuggingFace提供的Transformers生态。HuggingFace提供了各类BERT的API(transformers库)、训练好的模型(HuggingFace Hub)还有数据集(datasets)。最初,HuggingFace用PyTorch实现了BERT,并提供了预训练的模型,后来。越来越多的人直接使用HuggingFace提供好的模型进行微调,将自己的模型共享到HuggingFace社区。HuggingFace的社区越来越庞大,不仅覆盖了PyTorch版,还提供TensorFlow版,主流的预训练模型都会提交到HuggingFace社区,供其他人使用。
使用transformers库进行微调,主要包括:
- Tokenizer:使用提供好的Tokenizer对原始文本处理,得到Token序列;
- 构建模型:在提供好的模型结构上,增加下游任务所需预测接口,构建所需模型;
- 微调:将Token序列送入构建的模型,进行训练。
Tokenizer
下面两行代码会创建 BertTokenizer,并将所需的词表加载进来。首次使用这个模型时,transformers 会帮我们将模型从HuggingFace Hub下载到本地。
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
用得到的tokenizer进行分词:
>>> encoded_input = tokenizer("我是一句话")
>>> print(encoded_input)
{'input_ids': [101, 2769, 3221, 671, 1368, 6413, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1]}
得到的一个Python dict。其中,input_ids最容易理解,它表示的是句子中的每个Token在词表中的索引数字。词表(Vocabulary)是一个Token到索引数字的映射。可以使用decode()方法,将索引数字转换为Token。
>>> tokenizer.decode(encoded_input["input_ids"])
'[CLS] 我 是 一 句 话 [SEP]'
可以看到,BertTokenizer在给原始文本处理时,自动给文本加上了[CLS]和[SEP]这两个符号,分别对应在词表中的索引数字为101和102。decode()之后,也将这两个符号反向解析出来了。
token_type_ids主要用于句子对,比如下面的例子,两个句子通过[SEP]分割,0表示Token对应的input_ids属于第一个句子,1表示Token对应的input_ids属于第二个句子。不是所有的模型和场景都用得上token_type_ids。
>>> encoded_input = tokenizer("您贵姓?", "免贵姓李")
>>> print(encoded_input)
{'input_ids': [101, 2644, 6586, 1998, 136, 102, 1048, 6586, 1998, 3330, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
句子通常是变长的,多个句子组成一个Batch时,attention_mask就起了至关重要的作用。
>>> batch_sentences = ["我是一句话", "我是另一句话", "我是最后一句话"]
>>> batch = tokenizer(batch_sentences, padding=True, return_tensors="pt")
>>> print(batch)
{'input_ids':
tensor([[ 101, 2769, 3221, 671, 1368, 6413, 102, 0, 0],
[ 101, 2769, 3221, 1369, 671, 1368, 6413, 102, 0],
[ 101, 2769, 3221, 3297, 1400, 671, 1368, 6413, 102]]),
'token_type_ids':
tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask':
tensor([[1, 1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1]])}
对于这种batch_size = 3的场景,不同句子的长度是不同的,padding=True表示短句子的结尾会被填充[PAD]符号,return_tensors="pt"表示返回PyTorch格式的Tensor。attention_mask告诉模型,哪些Token需要被模型关注而加入到模型训练中,哪些Token是被填充进去的无意义的符号,模型无需关注。
Model
下面两行代码会创建BertModel,并将所需的模型参数加载进来。
>>> from transformers import BertModel
>>> model = BertModel.from_pretrained("bert-base-chinese")
BertModel是一个PyTorch中用来包裹网络结构的torch.nn.Module,BertModel里有forward()方法,forward()方法中实现了将Token转化为词向量,再将词向量进行多层的Transformer Encoder的复杂变换。
forward()方法的入参有input_ids、attention_mask、token_type_ids等等,这些参数基本上是刚才Tokenizer部分的输出。
>>> bert_output = model(input_ids=batch['input_ids'])
forward()方法返回模型预测的结果,返回结果是一个tuple(torch.FloatTensor),即多个Tensor组成的tuple。tuple默认返回两个重要的Tensor:
>>> len(bert_output)
2
- last_hidden_state:输出序列每个位置的语义向量,形状为:(batch_size, sequence_length, hidden_size)。
- pooler_output:
[CLS]符号对应的语义向量,经过了全连接层和tanh激活;该向量可用于下游分类任务。
下游任务
BERT可以进行很多下游任务,transformers库中实现了一些下游任务,我们也可以参考transformers中的实现,来做自己想做的任务。比如单文本分类,transformers库提供了BertForSequenceClassification类。
class BertForSequenceClassification(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.config = config
self.bert = BertModel(config)
classifier_dropout = ...
self.dropout = nn.Dropout(classifier_dropout)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
...
def forward(
...
):
...
outputs = self.bert(...)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
...
在这段代码中,BertForSequenceClassification在BertModel基础上,增加了nn.Dropout和nn.Linear层,在预测时,将BertModel的输出放入nn.Linear,完成一个分类任务。除了BertForSequenceClassification,还有BertForQuestionAnswering用于问答,BertForTokenClassification用于序列标注,比如命名实体识别。
transformers 中的各个API还有很多其他参数设置,比如得到每一层Transformer Encoder的输出等等,可以访问他们的文档查看使用方法。
参考资料
- Devlin J, Chang M-W, Lee K, Toutanova K. BERT: pre-training of deep bidirectional transformers for language understanding. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis, Minnesota: Association for Computational Linguistics, 2019: 4171–4186.
- 彻底理解Google BERT
- 图解BERT模型:从零开始构建BERT