基础知识:函数调用 v.s. 协程调用
Python 在 3.5 版中引入了 asyncio ,在 Python 3.6 中有了显著改进,并在 3.7 和 3.8 中不断发展。但异步编程的思想并不容易被人理解。python.org 的官方文档虽然非常详细和准确,但并不适合上手,特别是对于没有异步编程经验的程序员。这一系列的帖子旨在填补这一空白。
并行计算
计算机的 CPU 一次只做一件事。现代计算机配备了多个 CPU 核心,通过多线程(multi-threading)或者多进程(multi-processing)等方式来并行化,以充分利用多核。不同编程语言的实现也稍有不同,其中 Python 使用最多的是 multiprocessing 库。这些库的核心思想是让 Python 代码并行地在多个CPU核心上同时执行。
asyncio 并不是传统意义上的多线程或多进程!
使用 asyncio 并不是将代码转换成多线程,它不会导致多条Python指令同时执行,也不会以任何方式让你避开所谓的全局解释器锁(Global Interpreter Lock,GIL)。
CPU bound v.s. IO bound
CPU bound:有些应用受 CPU 速度的限制,并不需要频繁IO。很多传统高性能计算应用就是CPU bound的,例如,分子动力学模拟。
IO bound:有些应用受 IO 速度的限制,即使 CPU 速度再快,也无法充分发挥 CPU 的性能。这些应用花费大量时间从存储或网络设备读写数据,往往需要等待数据到达后才能进行计算,在等待期间,CPU 什么都做不了。大数据和AI就是典型的 IO bound 应用。
如果应用是 IO bound ,CPU 大量时间什么都做不了,单纯等待其他地方把数据准备好并搬运过来。其实,在 CPU 等待期间其实可以给它安排一些其他工作。 asyncio 的目的就是为了给 CPU 安排更多的工作:当前单线程代码正在等待某个事情发生时,另一段代码可以接管并使用 CPU,以充分利用 CPU 的计算性能。
asyncio 更多是关于更有效地使用单核,而不是如何使用多核。
函数 v.s. 协程
Subroutine
许多编程语言使用术语“函数”(Function)或“方法”(Method)或“过程”(Procedure)或“子程序”(Subroutine)来表示可以被其他代码调用的一段代码。一些比较古老的编程语言,比如 Fortran,会使用 Subroutine 这个词,在 Python 中,主要使用“函数”(Function)或“方法”(Method)这两个概念。
大多数编程语言都有所谓的“子程序”(Subroutine)调用模型。父函数遇到一个子程序,开始调用该函数,进入到该函数的开头,然后一直执行,直到函数的结尾(或遇到 return 语句),返回到调用该函数的地方。所有对该函数的调用都遵循上面的这个流程:进入函数,从头开始,直到 return 结尾,返回父函数调用处。这种调用模型我们再熟悉不过了。
此外,还有另一种代码执行模型,称为“协程”(Coroutine)调用模型。在这个调用模型中,被调用者可以“让出”控制权而不是把整个函数都返回。当这个被调用的协程“让出”控制权时,调用他的父函数会立即返回到当初调用协程的的位置。但未来再次调用协程时,不会从头开始,而是从上一次该协程执行停止的地方继续执行。控制权在父函数和协程之间来回跳转,如下图所示:
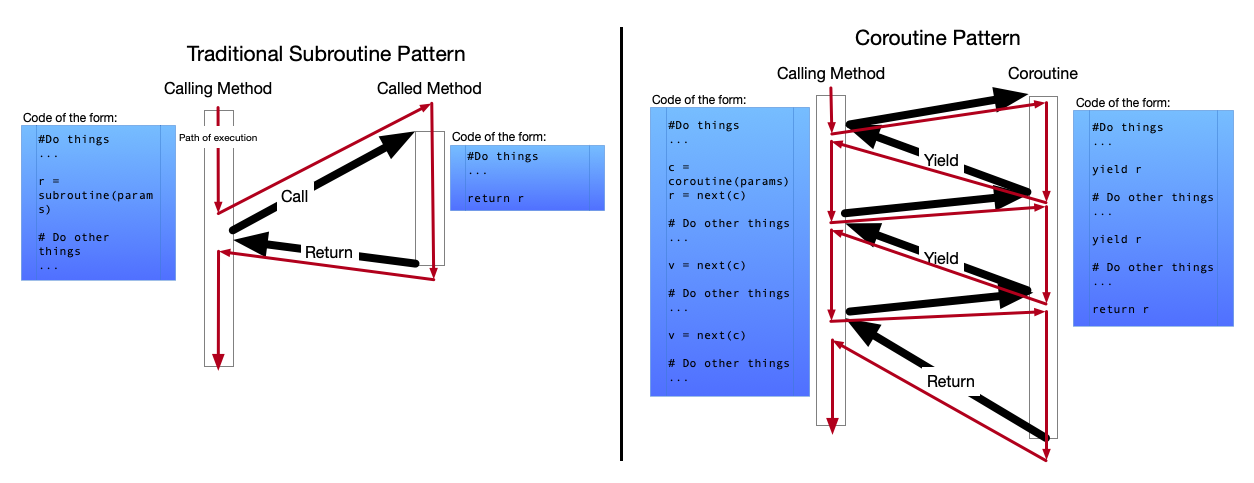
函数调用栈
继续深入探究函数调用,大多数操作系统和编程语言都使用一种称为“调用栈”的抽象。调用栈是一个堆栈数据结构。
为了说明这一点,下面使用一段简单的 Python 代码来演示:
def a_func(x):
return x-2
def main():
some_value = 12
some_other_value = a_func(some_value)
main()
当我们开始执行这段代码时,堆栈被初始化为内存中一个后进先出(Last In First Out)存储区,整个函数从最后一行 main() 开始执行。
假设我们对这段 Python 代码进行了编译,得到下面这个编译后的代码段。每行有一个行号,用来记录程序运行到哪一行。同时有一个名为指令指针(Instruction Pointer,IP)的指针,指向下一步将要运行哪一行代码。

由于 main() 函数本身就是一个函数调用,Python 解释器会调用 main() 函数:
- Python 解释器将一个新的“栈帧”添加到堆栈的顶部。栈帧是一个数据结构,是为这个函数调用单独分配的栈空间。
- Python 解释器在栈顶添加了一个“返回指针”(Return Point)。这是一个地址,它告诉解释器,当函数返回时,回到哪一行。
- Python 解释器根据 Instruction Pointer 中存的地址确定下一行将要执行什么。

下一条指令:some_value = 12 创建了一个局部变量,这个局部变量仅存在于这个 main() 函数的上下文,一旦离开 main() 函数,some_value 就不存在了。因此,局部变量 some_value 存储在 main() 栈帧中。

下一条指令: some_other_value = a_func(some_value)。这又是一个函数调用,Python 解释器继续进行函数调用:
- 它将一个新栈帧添加到堆栈的顶部。
- 它添加了一个 Return Point,该指针指向 04。
- 这个函数调用传递了参数,参数被放置在栈帧的顶部(x = 12)。
- Instruction Pointer 设置为 01,
a_func是下一条要执行的指令。

下一条要执行的指令是 return x-2 ,这里面有 return ,Python 解释器执行从函数返回的过程。
- 它从堆栈中删除顶部栈帧,包括其中的所有内容。
- 它将函数的返回值放在栈顶。
- Instruction Pointer 设置为 04,即刚刚记录的 Return Point。

几乎所有编程语言的函数调用都遵循这种模式。多线程跟这种方式也很像,只不过每个线程都有一个单独的堆栈,除此之外几乎完全相同。
然而,说了这么多,都是关于传统的函数调用的。asyncio 的原理跟这种函数调用有很大不同。
Event Loops/Tasks/Coroutines
在 asyncio 中,每个线程不再只有一个堆栈。相反,每个线程都有一个被称为事件循环(Event Loop)的对象。Event Loop 中包含一个称为任务(Task)的对象列表。每个 Task 维护一个堆栈,以及它自己的 Instruction Pointer。

在任意时刻,Event Loop 只能有一个 Task 实际执行,毕竟 CPU 在某一时刻只能做一件事,Event Loop 中的其他任务都暂停了。当前正在执行的 Task 跟我们经常使用的函数调用的 Python 程序一模一样。唯一区别在于,遇到需要等待的事情时接下来的处理方式,即当 Task 遇到需要等待的事情,比如 IO bound 应用需要等待数据到达。
此时,Task 中的代码不再等待,而是让出控制权。Event Loop 暂停正在运行的 Task。未来的某个时刻,当这个 Task 所等待的事情已经成熟,Event Loop 将再次唤醒这个 Task。
Task 让出控制权后,Event Loop 唤醒某个休眠的 Task,并将这个新唤醒的 Task 设置为当前执行的 Task。有一种可能,所有 Task 都无法被唤醒,因为所有 Task 都在等待自己所依赖的事情发生,那么 Event Loop 和所有 Task 一起等待。
通过这种方式,CPU 可以被不同的 Task 共享。Task 或者在执行自己的代码,或者在休眠,休眠期间等待自己所依赖的事情。
Event Loop 不能中断正在执行的协程
Event Loop 不能强制中断当前正在执行的协程。当前正在执行的协程将继续执行,直到它让出控制权。Event Loop 选择下一个被调度的协程,并跟踪这些协程的状态,例如哪些协程被阻塞且无法执行,直到某些 IO 完成。Event Loop 仅在当前没有协程正在执行时才执行去做这些跟踪状态的工作。
控制权在不同 Task 之间来回切换,下次唤醒 Task 时正好在上次停止的地方继续执行。这种方式被称为“协程调用”(Coroutine Calling)。这就是 Python asyncio 所提供的功能,它使得 CPU 闲置的时间更少。
这种调用方法适用于 IO bound 应用,在这类应用中,长时间的暂停是为了等待其他事情,比如某个应用请求一个 HTTP 网页,需要等待网页内容返回后才能进行下面的操作。有关 HTTP 或其他互联网流量的处理任务几乎都是 IO bound 的。
总结
本文并未介绍如何使用 asyncio 进行编程,而是明确了传统函数调用与协程调用的区别,了解 Event Loop、Task 的概念。再次做个总结:
- 异步(Asynchronous)编程:与传统的同步(Synchronous)编程相对应,同步编程就是传统的函数调用的方式,异步编程不需要等待事情完成,而是把控制权让出。
- 协程(Coroutine):异步编程中的某个函数体。
- Event Loop:管理和控制协程。
- Task:某个可运行的任务。
参考资料