Flink的时间语义
提示
本教程已出版为《Flink原理与实践》,感兴趣的读者请在各大电商平台购买!
在流处理中,时间是一个非常核心的概念,是整个系统的基石。我们经常会遇到这样的需求:给定一个时间窗口,比如一个小时,统计时间窗口内的数据指标。那如何界定哪些数据将进入这个窗口呢?在窗口的定义之前,首先需要确定一个作业使用什么样的时间语义。
本节将介绍Flink的Event Time、Processing Time和Ingestion Time三种时间语义,接着会详细介绍Event Time和Watermark的工作机制,以及如何对数据流设置Event Time并生成Watermark。
Flink的三种时间语义
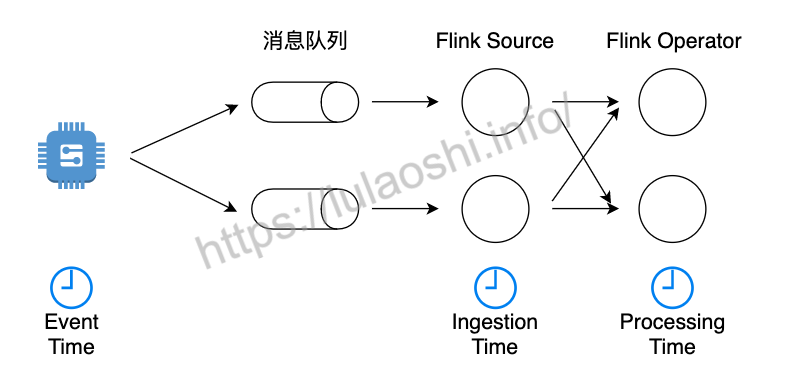
如上图所示,Flink支持三种时间语义。
Event Time
Event Time指的是数据流中每个元素或者每个事件自带的时间属性,一般是事件发生的时间。由于事件从发生到进入Flink时间算子之间有很多环节,一个较早发生的事件因为延迟可能较晚到达,因此使用Event Time意味着事件到达有可能是乱序的。
使用Event Time时,最理想的情况下,我们可以一直等待所有的事件到达后再进行时间窗口的处理。假设一个时间窗口内的所有数据都已经到达,基于Event Time的流处理会得到正确且一致的结果。无论我们是将同一个程序部署在不同的计算环境,还是在相同的环境下多次计算同一份数据,都能够得到同样的计算结果。我们根本不同担心乱序到达的问题。
但这只是理想情况,现实中无法实现,因为我们既不知道究竟要等多长时间才能确认所有事件都已经到达,更不可能无限地一直等待下去。在实际应用中,当涉及到对事件按照时间窗口进行统计时,Flink会将窗口内的事件缓存下来,直到接收到一个Watermark,Watermark假设不会有更晚数据的到达。Watermark意味着在一个时间窗口下,Flink会等待一个有限的时间,这在一定程度上降低了计算结果的绝对准确性,而且增加了系统的延迟。比起其他几种时间语义,使用Event Time的好处是某个事件的时间是确定的,这样能够保证计算结果在一定程度上的可预测性。
一个基于Event Time的Flink程序中必须定义:一、每条数据的Event Time时间戳作为Event Tme,二、如何生成Watermark。我们可以使用数据自带的时间作为Event Time,也可以在数据到达Flink后人为给Event Time赋值。
总之,使用Event Time的优势是结果的可预测性,缺点是缓存较大,增加了延迟,且调试和定位问题更复杂。
Processing Time
对于某个算子来说,Processing Time指算子使用当前机器的系统时钟时间。在Processing Time的时间窗口场景下,无论事件什么时候发生,只要该事件在某个时间段到达了某个算子,就会被归结到该窗口下,不需要Watermark机制。对于一个程序,在同一个计算环境来说,每个算子都有一定的耗时,同一个事件的Processing Time,第n个算子和第n+1个算子不同。如果一个程序在不同的集群和环境下执行,限于软硬件因素,不同环境下前序算子处理速度不同,对于下游算子来说,事件的Processing Time也会不同,不同环境下时间窗口的计算结果会发生变化。因此,Processing Time在时间窗口下的计算会有不确定性。
Processing Time只依赖当前执行机器的系统时钟,不需要依赖Watermark,无需缓存。Processing Time是实现起来非常简单,也是延迟最小的一种时间语义。
Ingestion Time
Ingestion Time是事件到达Flink Source的时间。从Source到下游各个算子中间可能有很多计算环节,任何一个算子的处理速度快慢可能影响到下游算子的Processing Time。而Ingestion Time定义的是数据流最早进入Flink的时间,因此不会被算子处理速度影响。
Ingestion Time通常是Event Time和Processing Time之间的一个折中方案。比起Event Time,Ingestion Time可以不需要设置复杂的Watermark,因此也不需要太多缓存,延迟较低。比起Processing Time,Ingestion Time的时间是Source赋值的,一个事件在整个处理过程从头至尾都使用这个时间,而且后续算子不受前序算子处理速度的影响,计算结果相对准确一些,但计算成本比Processing Time稍高。
设置时间语义
在Flink中,我们需要在执行环境层面设置使用哪种时间语义。下面的代码使用Event Time:
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
如果想用另外两种时间语义,需要替换为:TimeCharacteristic.ProcessingTime和TimeCharacteristic.IngestionTime。
相关信息
首次进行时间相关计算的读者可能因为没有正确设置数据流时间相关属性而得不到正确的结果。包括本书前序章节的示例代码在内,一些测试或演示代码常常使用StreamExecutionEnvironment.fromElements()或StreamExecutionEnvironment.fromCollection()方法来创建一个DataStream,用这种方法生成的DataStream没有时序性,如果不对元素设置时间戳,无法进行时间相关的计算。或者说,在一个没有时序性的数据流上进行时间相关计算,无法得到正确的结果。想要建立数据之间的时序性,一种方法是继续用StreamExecutionEnvironment.fromElements()或StreamExecutionEnvironment.fromCollection()方法,使用Event Time时间语义,对数据流中每个元素的Event Time进行赋值。另一种方法是使用其他的Source,比如StreamExecutionEnvironment.socketTextStream()或Kafka,这些Source的输入数据本身带有时序性,支持Processinng Time时间语义。
Event Time和Watermark
Flink的三种时间语义中,Processing Time和Ingestion Time都可以不用设置Watermark。如果我们要使用Event Time语义,以下两项配置缺一不可:第一,使用一个时间戳为数据流中每个事件的Event Time赋值;第二,生成Watermark。
实际上,Event Time是每个事件的元数据,如果不设置,Flink并不知道每个事件的发生时间,我们必须要为每个事件的Event Time赋值一个时间戳。关于时间戳,包括Flink在内的绝大多数系统都使用Unix时间戳系统(Unix time或Unix epoch)。Unix时间戳系统以1970-01-01 00:00:00.000 为起始点,其他时间记为距离该起始时间的整数差值,一般是毫秒(millisecond)精度。
有了Event Time时间戳,我们还必须生成Watermark。Watermark是Flink插入到数据流中的一种特殊的数据结构,它包含一个时间戳,并假设后续不会有小于该时间戳的数据。下图展示了一个乱序数据流,其中方框是单个事件,方框中的数字是其对应的Event Time时间戳,圆圈为Watermark,圆圈中的数字为Watermark对应的时间戳。
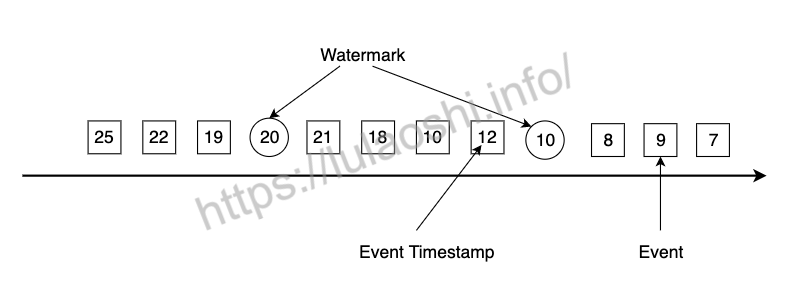
Watermark的生成有以下几点需要注意:
- Watermark与事件的时间戳紧密相关。一个时间戳为t的Watermark会假设后续到达事件的时间戳都大于t。
- 假如Flink算子接收到一个违背上述规则的事件,该事件将被认定为迟到数据,如上图中时间戳为19的事件比Watermark(20)更晚到达。Flink提供了一些其他机制来处理迟到数据。
- Watermark时间戳必须单调递增,以保证时间不会倒流。
- Watermark机制允许用户来控制准确度和延迟。Watermark设置得与事件时间戳相距紧凑,会产生不少迟到数据,影响计算结果的准确度,整个应用的延迟很低;Watermark设置得非常宽松,准确度能够得到提升,但应用的延迟较高,因为Flink必须等待更长的时间才进行计算。
分布式环境下Watermark的传播
在实际计算过程中,Flink的算子一般分布在多个并行的算子子任务(或者称为实例、分区)上,Flink需要将Watermark在并行环境下向前传播。如下图中第一步所示,Flink的每个并行算子子任务会维护针对该子任务的Event Time时钟,这个时钟记录了这个算子子任务Watermark处理进度,随着上游Watermark数据不断向下发送,算子子任务的Event Time时钟也要不断向前更新。由于上游各分区的处理速度不同,到达当前算子的Watermark也会有先后快慢之分,每个算子子任务会维护来自上游不同分区的Watermark信息,这是一个列表,列表内对应上游算子各分区的Watermark时间戳等信息。
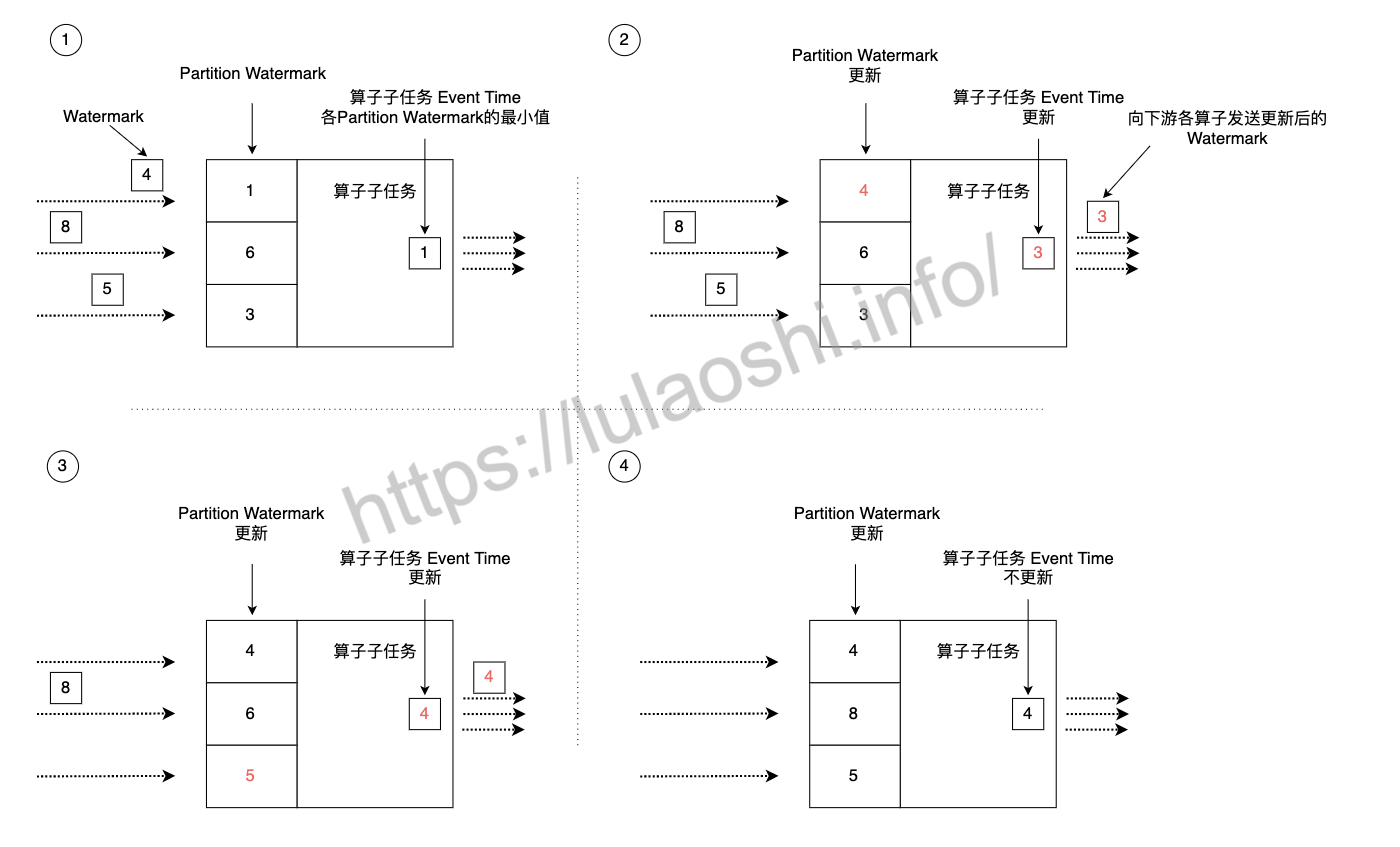
当上游某分区有Watermark进入该算子子任务后,Flink先判断新流入的Watermark时间戳是否大于Partition Watermark列表内记录的该分区的历史Watermark时间戳,如果新流入的更大,则更新该分区的Watermark。如上图中第二步所示,某个分区新流入的Watermark时间戳为4,算子子任务维护的该分区Watermark为1,那么Flink会更新Partition Watermark列表为最新的时间戳4。接着,Flink会遍历Partition Watermark列表中的所有时间戳,选择最小的一个作为该算子子任务的Event Time。同时,Flink会将更新的Event Time作为Watermark发送给下游所有算子子任务。算子子任务Event Time的更新意味着该子任务将时间推进到了这个时间,该时间之前的事件已经被处理并发送到下游。上图中第二步和第三步均执行了这个过程。Partition Watermark列表更新后,导致列表中最小时间戳发生了变化,算子子任务的Event Time时钟也相应进行了更新。整个过程可以理解为:数据流中的Watermark推动算子子任务的Watermark更新。Watermark像一个幕后推动者,不断将流处理系统的Event Time向前推进。我们可以将这种机制总结为:
- Flink某算子子任务根据各上游流入的Watermark来更新Partition Watermark列表。
- 选取Partition Watermark列表中最小的时间作为该算子子任务的Event Time,并将这个时间发送给下游算子。
这样的设计机制满足了并行环境下Watermark在各算子中的传播问题,但是假如某个上游分区的Watermark一直不更新,Partition Watermark列表其他地方都在正常更新,唯独个别分区的Watermark停滞,这会导致算子的Event Time时钟不更新,相应的时间窗口计算也不会被触发,大量的数据积压在算子内部得不到处理,整个流处理处于空转状态。这种问题可能出现在数据流自带Watermark的场景,自带的Watermark在某些分区下没有及时更新。针对这种问题,一种解决办法是根据机器当前的时钟,周期性地生成Watermark。
此外,在union()等多数据流处理时,Flink也使用上述Watermark更新机制,那就意味着,多个数据流的时间必须对齐,如果一方的Watermark时间较老,那整个应用的Event Time时钟也会使用这个较老的时间,其他数据流的数据会被积压。一旦发现某个数据流不再生成新的Watermark,我们要在SourceFunction中的SourceContext里调用markAsTemporarilyIdle()设置该数据流为空闲状态,避免空转。
抽取时间戳及生成Watermark
至此,我们已经了解了Flink的Event Time和Watermark机制的大致工作原理,接下来我们将展示如何在代码层面设置时间戳并生成Watermark。因为时间在后续处理中都会用到,时间的设置要在任何时间窗口操作之前。总之,时间越早设置越好。对时间和Watermark的设置只对Event Time时间语义起作用,如果一个作业基于Processing Time或Ingestion Time,那设置时间没有什么意义。Flink提供了新老两种方法设置时间戳和Watermark。无论哪种方法,我们都需要明白,Event Time时间戳和Watermark是捆绑在一起的,一旦涉及到Event Time,就必须抽取时间戳并生成Watermark。
Source
我们可以在Source阶段完成时间戳抽取和Watermark生成的工作。Flink 1.11开始推出了新的Source接口,并计划逐步替代老的Source接口,我们将在第七章展示两种接口的具体工作方式,这里暂时以老的Source接口来展示时间戳抽取和Watermark生成的过程。在老的Source接口中,通过自定义SourceFunction或RichSourceFunction,在SourceContext里重写void collectWithTimestamp(T element, long timestamp)和void emitWatermark(Watermark mark)两个方法,其中,collectWithTimestamp()给数据流中的每个元素T赋值一个timestamp作为Event Time,emitWatermark()生成Watermark。下面的代码展示了调用这两个方法抽取时间戳并生成Watermark。
class MyType {
public double data;
public long eventTime;
public boolean hasWatermark;
public long watermarkTime;
...
}
class MySource extends RichSourceFunction[MyType] {
@Override
public void run(SourceContext<MyType> ctx) throws Exception {
while (/* condition */) {
MyType next = getNext();
ctx.collectWithTimestamp(next, next.eventTime);
if (next.hasWatermarkTime()) {
ctx.emitWatermark(new Watermark(next.watermarkTime));
}
}
}
}
Source之后
如果我们不想修改Source,也可以在Source之后,通过assignTimestampsAndWatermarks()方法来设置。与Source接口一样,Flink 1.11重构了assignTimestampsAndWatermarks()方法,重构后的assignTimestampsAndWatermarks()方法和新的Source接口结合更好、表达能力更强,这里介绍一下重构后的assignTimestampsAndWatermarks()方法。
新的assignTimestampsAndWatermarks()方法主要依赖WatermarkStrategy,通过WatermarkStrategy我们可以为每个元素抽取时间戳并生成Watermark。assignTimestampsAndWatermarks()方法结合WatermarkStrategy的大致使用方式为:
DataStream<MyType> stream = ...
DataStream<MyType> withTimestampsAndWatermarks = stream
.assignTimestampsAndWatermarks(
WatermarkStrategy
.forGenerator(...)
.withTimestampAssigner(...)
);
可以看到WatermarkStrategy.forGenerator(...).withTimestampAssigner(...)链式调用了两个方法,forGenerator()方法用来生成Watermark,withTimestampAssigner()方法用来为数据流的每个元素设置时间戳。
withTimestampAssigner()方法相对更好理解,它抽取数据流中的每个元素的时间戳,一般是告知Flink具体哪个字段为时间戳字段。例如,一个MyType数据流中eventTime字段为时间戳,数据流的每个元素为event,使用Lambda表达式来抽取时间戳,可以写成:.withTimestampAssigner((event, timestamp) -> event.eventTime)。这个Lambda表达式可以帮我们抽取数据流元素中的时间戳eventTime,我们暂且可以不用关注第二个参数timestamp。
基于Event Time时间戳,我们还要设置Watermark生成策略,一种方法是自己实现一些Watermark策略类,并使用forGenerator()方法调用这些Watermark策略类。我们曾多次提到,Watermark是一种插入到数据流中的特殊元素,Watermark元素包含一个时间戳,当某个算子接收到一个Watermark元素时,算子会假设早于这条Watermark的数据流元素都已经到达。那么如何向数据流中插入Watermark呢?Flink提供了两种方式,一种是周期性地(Periodic)生成Watermark,一种是逐个式地(Punctuated)生成Watermark。无论是Periodic方式还是Punctuated方式,都需要实现WatermarkGenerator接口类,如下所示,T为数据流元素类型。
// Flink源码
// 生成Watermark的接口类
@Public
public interface WatermarkGenerator<T> {
// 数据流中的每个元素流入后都会调用onEvent()方法
// Punctunated方式下,一般根据数据流中的元素是否有特殊标记来判断是否需要生成Watermark
// Periodic方式下,一般用于记录各元素的Event Time时间戳
void onEvent(T event, long eventTimestamp, WatermarkOutput output);
// 每隔固定周期调用onPeriodicEmit()方法
// 一般主要用于Periodic方式
// 固定周期用 ExecutionConfig#setAutoWatermarkInterval() 方法设置
void onPeriodicEmit(WatermarkOutput output);
}
Periodic
假如我们想周期性地生成Watermark,这个周期是可以设置的,默认情况下是每200毫秒生成一个Watermark,或者说Flink每200毫秒调用一次生成Watermark的方法。我们可以在执行环境中设置这个周期:
// 每5000毫秒生成一个Watermark
env.getConfig.setAutoWatermarkInterval(5000L)
下面的代码定期生成Watermark,数据流元素是一个Tuple2,第二个字段Long是Event Time时间戳。
// 定期生成Watermark
// 数据流元素 Tuple2<String, Long> 共两个字段
// 第一个字段为数据本身
// 第二个字段是时间戳
public static class MyPeriodicGenerator implements WatermarkGenerator<Tuple2<String, Long>> {
private final long maxOutOfOrderness = 60 * 1000; // 1分钟
private long currentMaxTimestamp; // 已抽取的Timestamp最大值
@Override
public void onEvent(Tuple2<String, Long> event, long eventTimestamp, WatermarkOutput output) {
// 更新currentMaxTimestamp为当前遇到的最大值
currentMaxTimestamp = Math.max(currentMaxTimestamp, eventTimestamp);
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// Watermark比currentMaxTimestamp最大值慢1分钟
output.emitWatermark(new Watermark(currentMaxTimestamp - maxOutOfOrderness));
}
}
我们用变量currentMaxTimestamp记录已抽取的时间戳最大值,每个元素到达后都会调用onEvent()方法,更新currentMaxTimestamp时间戳最大值。当需要发射Watermark时,以时间戳最大值减1分钟作为Watermark发送出去。这种Watermark策略假设Watermark比已流入数据的最大时间戳慢1分钟,超过1分钟的将被视为迟到数据。
实现好MyPeriodicGenerator后,我们要用forGenerator()方法调用这个类:
// 第二个字段是时间戳
DataStream<Tuple2<String, Long>> watermark = input.assignTimestampsAndWatermarks(
WatermarkStrategy
.forGenerator((context -> new MyPeriodicGenerator()))
.withTimestampAssigner((event, recordTimestamp) -> event.f1));
考虑到这种基于时间戳最大值的场景比较普遍,Flink已经帮我们封装好了这样的代码,名为BoundedOutOfOrdernessWatermarks,其内部实现与上面的代码几乎一致,我们只需要将最大的延迟时间作为参数传入:
// 第二个字段是时间戳
DataStream<Tuple2<String, Long>> input = env
.addSource(new MySource())
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<Tuple2<String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner((event, timestamp) -> event.f1)
);
除了BoundedOutOfOrdernessWatermarks,另外一种预置的Watermark策略为AscendingTimestampsWatermarks。AscendingTimestampsWatermarks其实是继承了BoundedOutOfOrdernessWatermarks,只不过AscendingTimestampsWatermarks会假设Event Time时间戳单调递增,从内部代码实现上来说,Watermark的发射时间为时间戳最大值,不添加任何延迟。使用时,可以参照下面的方式:
// 第二个字段是时间戳
DataStream<Tuple2<String, Long>> input = env
.addSource(new MySource())
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<Tuple2<String, Long>>forMonotonousTimestamps()
.withTimestampAssigner((event, timestamp) -> event.f1)
);
Punctuated
假如数据流元素有一些特殊标记,标记了某些元素为Watermark,我们可以逐个检查数据流各元素,根据是否有特殊标记判断是否要生成Watermark。下面的代码以一个Tuple3<String, Long, Boolean>为例,其中第二个字段是时间戳,第三个字段标记了是否为Watermark。我们只需要在onEvent()方法中根据第三个字段来决定是否生成一条新的Watermark,由于这里不需要周期性的操作,因此onPeriodicEmit()方法里不需要做任何事情。
// 逐个检查数据流中的元素,根据元素中的特殊字段,判断是否要生成Watermark
// 数据流元素 Tuple3<String, Long, Boolean> 共三个字段
// 第一个字段为数据本身
// 第二个字段是时间戳
// 第三个字段判断是否为Watermark的标记
public static class MyPunctuatedGenerator implements WatermarkGenerator<Tuple3<String, Long, Boolean>> {
@Override
public void onEvent(Tuple3<String, Long, Boolean> event, long eventTimestamp, WatermarkOutput output) {
if (event.f2) {
output.emitWatermark(new Watermark(event.f1));
}
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 这里不需要做任何事情,因为我们在 onEvent() 方法中生成了Watermark
}
}
注
假如每个元素都带有Watermark标记,Flink是允许为每个元素都生成一个Watermark的,但这种策略非常激进,大量的Watermark会增大下游计算的延迟,拖累整个Flink作业的性能。
平衡延迟和准确性
至此,我们已经了解了Flink的Event Time和Watermark生成方法,那么具体如何操作呢?实际上,这个问题可能并没有一个标准答案。批处理中,数据都已经准备好了,不需要考虑未来新流入的数据,而流处理中,我们无法完全预知有多少迟到数据,数据的流入依赖业务的场景、数据的输入、网络的传输、集群的性能等等。Watermark是一种在延迟和准确性之间平衡的策略:Watermark与事件的时间戳贴合较紧,一些重要数据有可能被当成迟到数据,影响计算结果的准确性;Watermark设置得较松,整个应用的延迟增加,更多的数据会先缓存起来以等待计算,会增加内存的压力。对待具体的业务场景,我们可能需要反复尝试,不断迭代和调整时间戳和Watermark策略。