RDMA高速网络与集合通讯
很少有人深入分析其中的一个关键技术:网络。这篇文章带大家认识一下大模型训练的高速网络。
RDMA
Remote Direct Memory Access (RDMA) 是一种超高速的网络内存访问技术,它允许程序以极快速度访问远程计算节点的内存。速度快的原因如下图所示,一次网络访问,不需要经过操作系统的内核(Sockets、TCP/IP等),这些操作系统内核操作都会耗费CPU时间。RDMA直接越过了这些操作系统内核开销,直接访问到网卡(Network Interface Card,NIC)。一些地方又称之为HCA(Host Channel Adapter)。
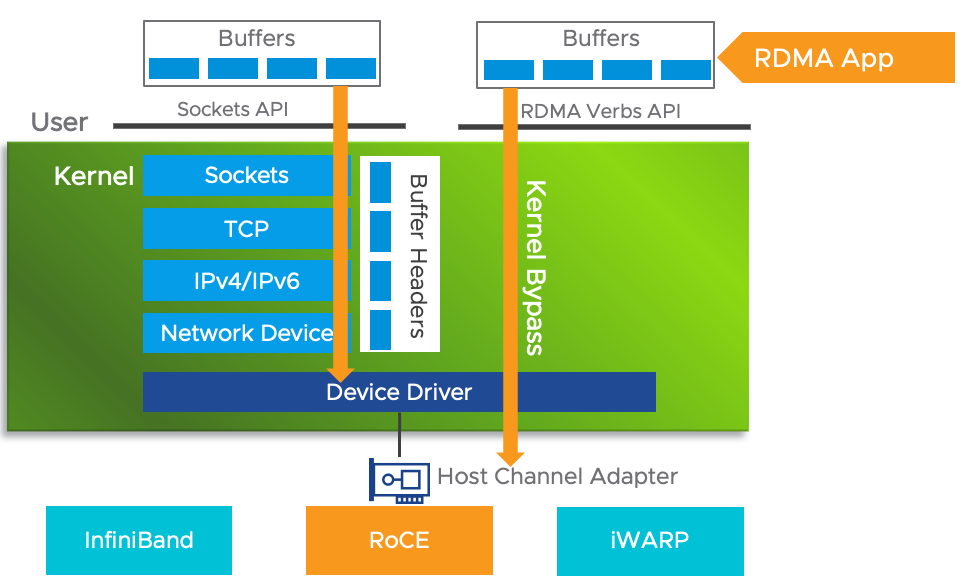
RDMA的硬件主要有三种实现:InfiniBand、RoCE和iWARP。据我了解,InfiniBand和RoCE是目前比较主流的技术。
InfiniBand:无限带宽
从名字可以看出,InfiniBand要达到无限带宽,名字听起来牛逼哄哄。实际上,也确实很牛逼。InfiniBand来自一家以色列公司:Mellanox,这家公司在2020年以69亿美元卖给了NVIDIA,被老黄收入旗下。
InfiniBand目前主流的技术是100G、200G。人家起了一些很极客的名字,Enhanced Data Rate(EDR,100G)High Data Rate (HDR,200G)。
绝大多数IT从业者可能很少接触到InfiniBand,因为这个技术很贵,大家舍不得买。但在各大高校和科研院所的超算中心,InfiniBand几乎标配,它支撑着非常关键的超级计算任务。有多贵呢?一条InfiniBand 10米网线,大概长下面这样,大概1w人民币;网线的两端要配网卡,两头的网卡一块6k人民币,2块就是1.2w,那一根网线加上两端的网卡就是2w块钱。

下图是1G以太网线与InfiniBand交换机对比图,上面是1G以太网线,下面是HDR交换机。

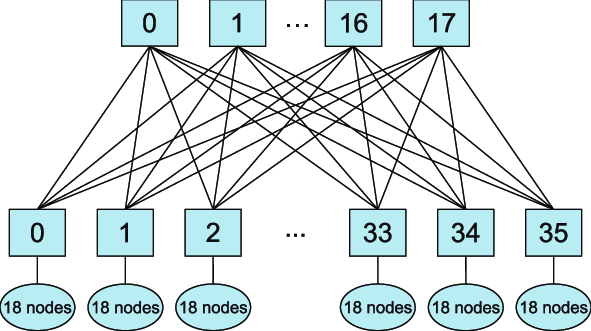
这还没结束,InfiniBand的组网成本也极高。InfiniBand组网跟普通的交换机还不太一样,如果希望这个网络中任何两个计算节点的网卡之间互相无损地通信,需要使用一种叫做胖树(Fat Tree)的网络拓扑,大概是如下一种拓扑结构,方块是交换机,椭圆是计算节点。胖树主要有两层,上面一层是核心层,不连任何计算节点,它的功能就是转发流量;下面一层是接入层,接入各类计算节点。胖树拓扑成本高的主要原因是:某一个汇聚交换机上,假如有36个口,那如果为了达到无损速率,一半的口,也就是18个口可以给计算节点连,剩下一半要连到上层的核心交换机上。要知道,任何一根线,就是1万多块钱呢,如果达到无损,就要冗余地做这些连接。
说了这么多成本,再来说性能。贵的就是好的;好的就是贵的。InfiniBand确实能够达到极高的带宽和极低的延迟。据维基百科,InfiniBand对比以太网,延迟分别是100纳秒和230纳秒。包括微软、NVIDIA、以及美国国家实验室等世界上主流的超级计算机,都是用的InfiniBand。
RoCE
相比InfiniBand这种爱马仕,RoCE是另外一种稍微便宜一点的选项,但也便宜不到哪儿去。RDMA over Converged Ethernet (RoCE),主要在以太网上提供RDMA。近些年来发展很快,因为InfiniBand太贵了,大家需要一个替代品。
目前来说,华为在力推RoCE,但如果也要做无损网络,整个网络成本也很难控制在InfiniBand的50%以下。
GPUDirect RDMA
训练大模型,节点间通信成本很高,InfiniBand与GPU的组合可以提供跨节点的 GPUDirect RDMA,就是说两个节点的GPU通信不需要经过内存和CPU,而是直接由InfiniBand网卡通信。GPUDirect RDMA对于大模型训练尤其重要,因为模型都在GPU上,模型拷贝到CPU上就已经耗费了大量时间,再通过CPU发送至其他节点就更慢了。
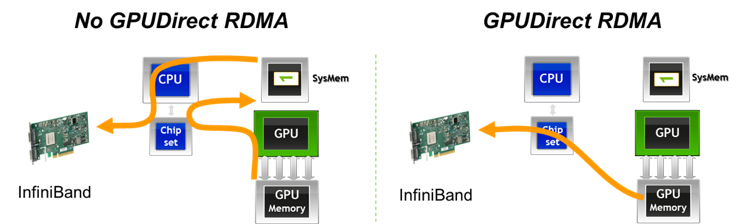
驱动
如何让硬件工作,以释放NVIDIA GPU和InfiniBand网卡的性能?其实很简单,只需要安装NVIDIA推荐的最新的驱动即可,在NVIDIA最新的驱动中,有一个名为 nv_peer_mem 的模块,加载之后即可以开启GPUDirect RDMA。上层的应用,比如PyTorch或者TensorFlow,几乎不用改代码,就可以充分利用多张GPU卡和InfiniBand网卡带来的性能提升。
MPI&NCCL
前面聊完了硬件,再聊聊软件。在这些高速网络上编程,有几个常用的方案,最通用的可能是MPI(Message Passing Interface),然后就是深度学习训练所需要的NCCL(NVIDIA Collective Communication Library)。
MPI是经典的并行计算接口,主要有OpenMPI和Intel MPI几个实现,可以达到节点间通信的需求。一般情况下,在计算节点上安装了InfiniBand驱动,安装了OpenMPI/Intel MPI之后,一些高性能的计算流量会走InfiniBand网络。
NCCL是16年左右开始的一个项目,已经有了MPI,NVIDIA还要造一个轮子,因为MPI是一个通用的框架,并不是专门做深度学习的。NCCL试图解决深度学习训练中特有的通讯问题。
NCCL主要实现了以下几个通信原语:
- AllReduce
- Broadcast
- Reduce
- AllGather
- ReduceScatter
说白了,就是提供了一个接口,用户不需要知道哪些节点的如何相互之间通信,只需要调用接口,就可以实现GPU之间的通信。
NCCL的接口比较底层,大多数搞深度学习上层应用的人不需要太深入了解,它主要给深度学习框架来用,深度学习框架PyTorch、MindSpore等等都是调用NCCL来进行GPU上的集合通讯的。
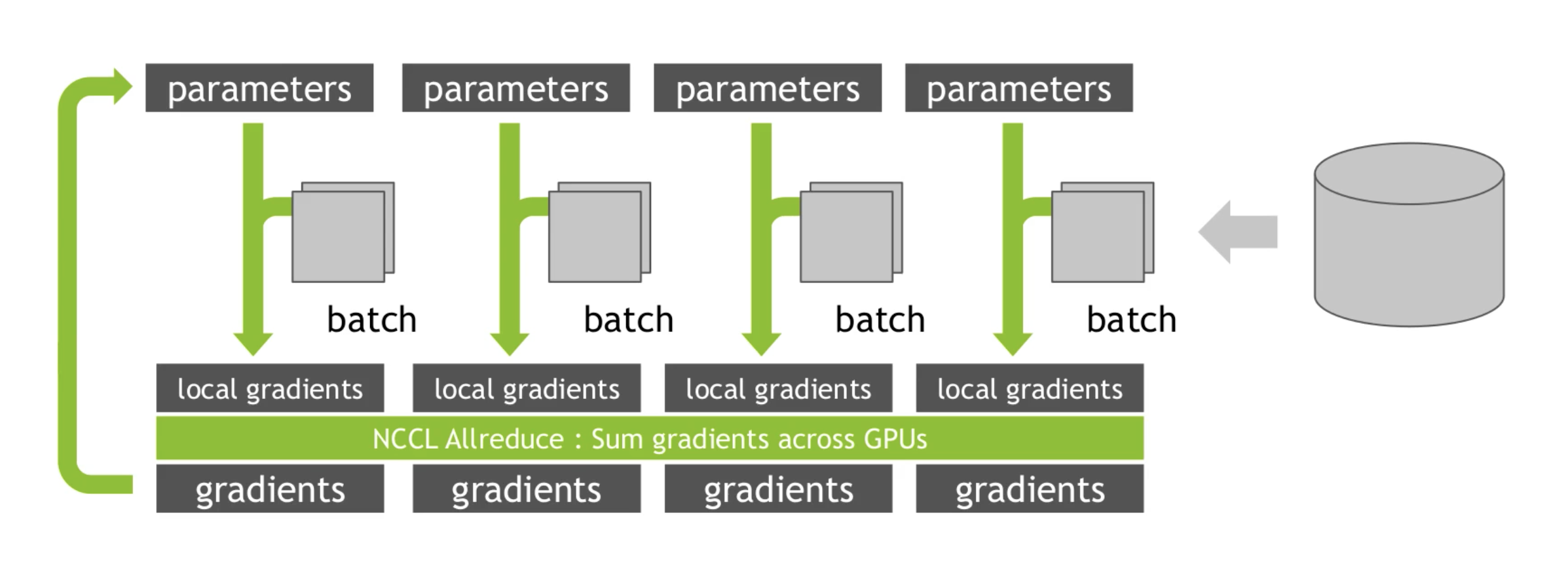
下面是一个最经典的 DataParallel 模式,NCCL提供Allreduce原语,把不同GPU上的梯度同步一下。
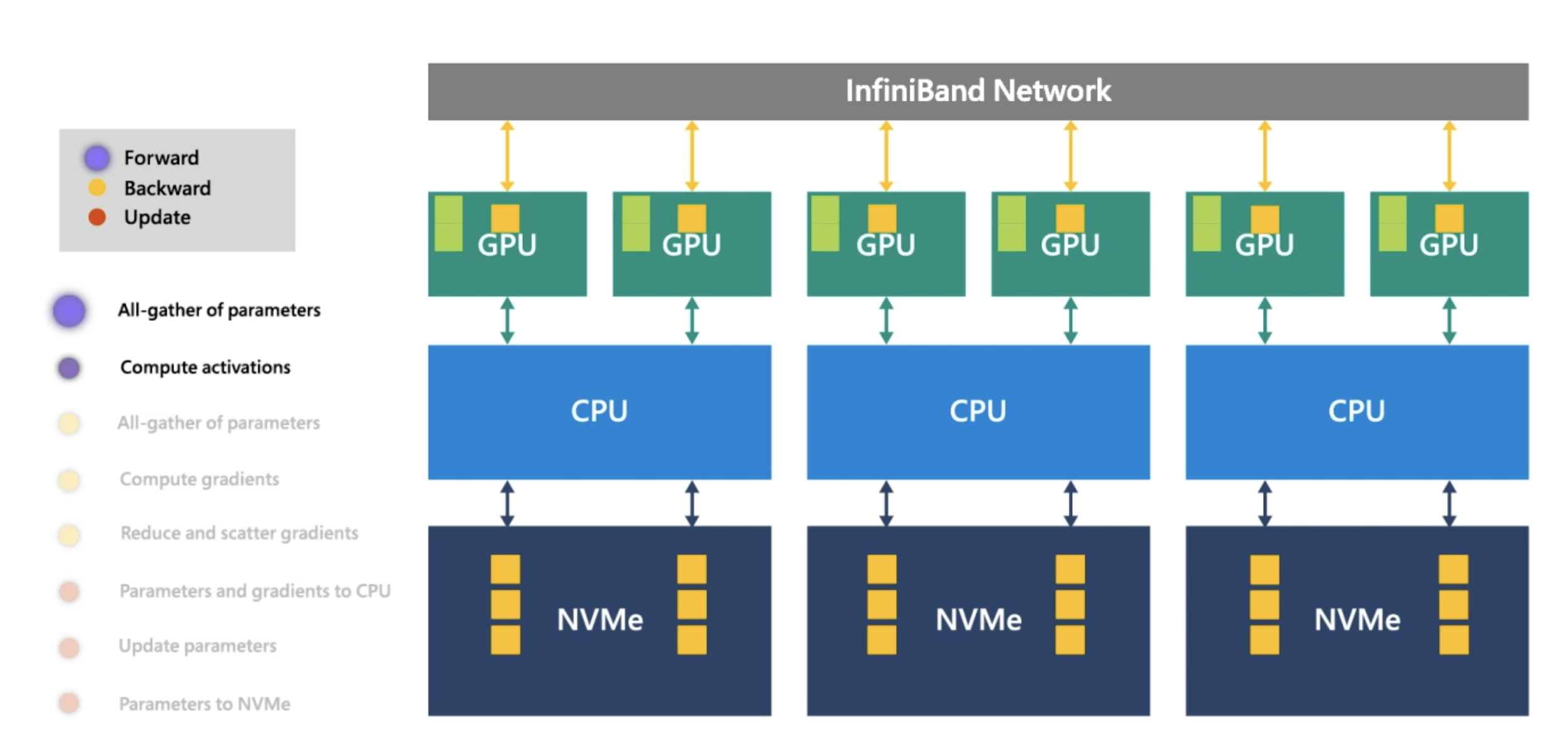
下面是微软 DeepSpeed Infinity 的架构,核心的网络在 InfiniBand 上,训练在GPU上,部分参数转移到 CPU 和 NVMe上。
我们可以了解一下NCCL的原理。NCCL主要做几件事:探测计算节点的网络设备和拓扑结构,使用算法自动调优选择一个最优的通信方式。
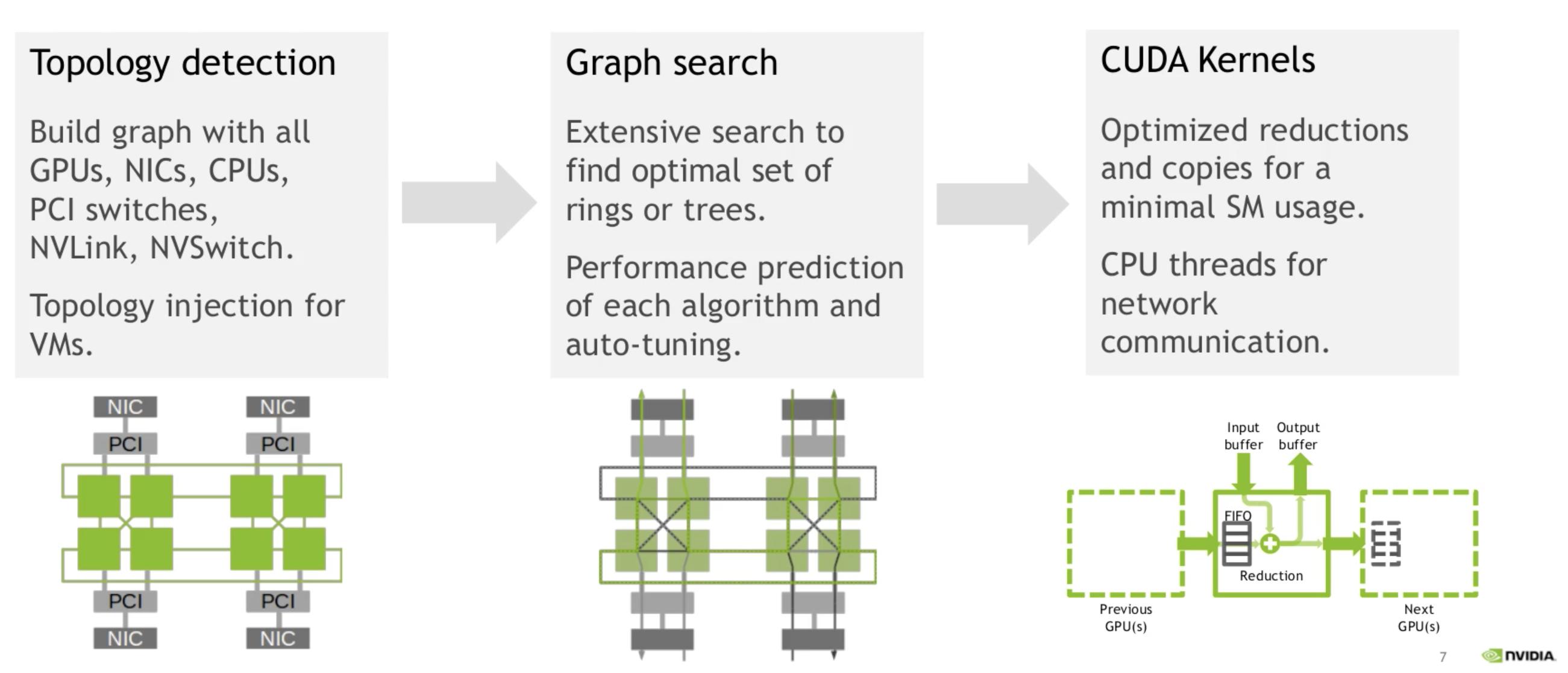
为什么要做拓扑探测?因为每个计算节点的设备情况差异比较大,每个计算节点可能有自己特定的网卡NIC,可能是InfiniBand也可能是RoCE,每个计算节点上的GPU可能是NVLink,也可能是PCI-E。为了达到最优的传输效率,NCCL先要摸清当前计算节点的网络、CPU和GPU情况。之后使用调优工具,进行调优,从众多通信方式中选择一个最优方式。
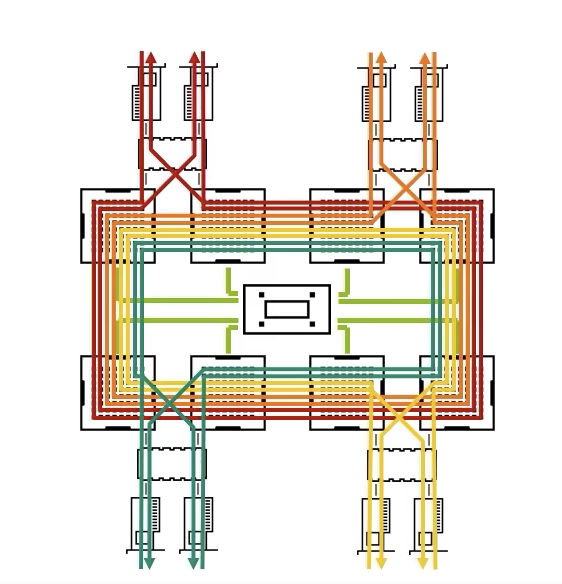
下面这张图是1台计算节点搭载了8个GPU和8张网卡,某种通信路径的演示图。
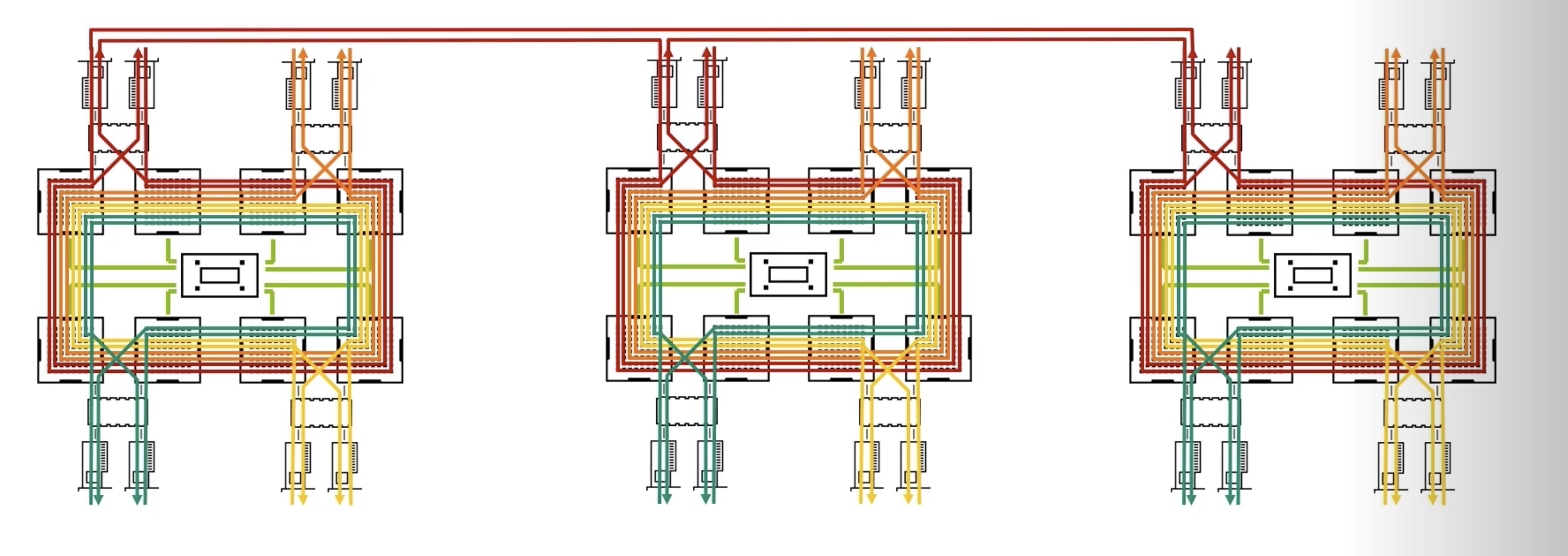
下面是3台计算节点的通信示意图。
大模型网卡配置
如果要做大模型,最佳的方案是一张GPU卡配一个InfiniBand网卡,NVIDIA的DGX系统就是这么搭配的。那么一个计算节点上通常可能有9个InfiniBand网卡,其中1个给存储系统(比如Lustre),另外8个分别给8个GPU卡。这样的成本极高。预算有限的话,最好也要1 + 4。一般情况下,GPU和InfiniBand都是连在PCI-E Switch上,2个GPU会连在1个PCI-E Switch上。最理想情况是给每个GPU分配1个InfiniBand网卡,这样无疑是最优的。如果给2个GPU配1个InfiniBand网卡,2个GPU共享PCI-E Switch和InfiniBand网卡,两个GPU之间会争抢这1个InfiniBand网卡。如果InfiniBand网卡数量越少,GPU之间的争抢越明显,节点间的通信效率就越低。
下面这张图里可以看到,如果只配置1张100Gbps的网卡,带宽是12GB/s,将bit转换为byte,即 。随着网卡数量的增多,带宽也近乎线性地增长。8张H100搭配8张400G的InfiniBand NDR,这速度也是没谁了。

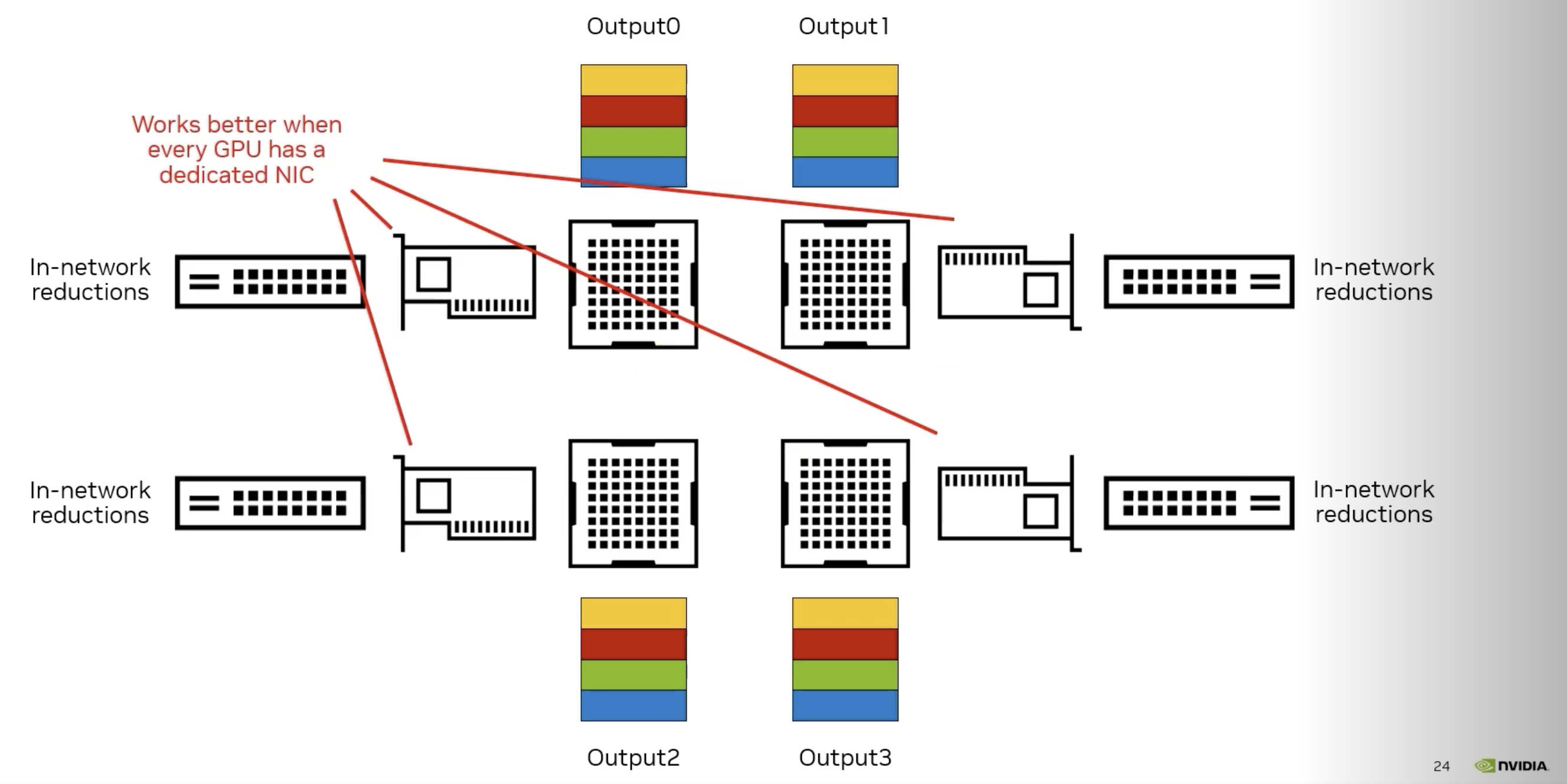
大模型网络拓扑:导轨优化
如果想做大模型,还需要配置专用的胖树网络拓扑,这种胖树网络拓扑和普通的HPC胖树还不太一样,NVIDIA起名为Rails(导轨优化),具体来说,像下面两张图。
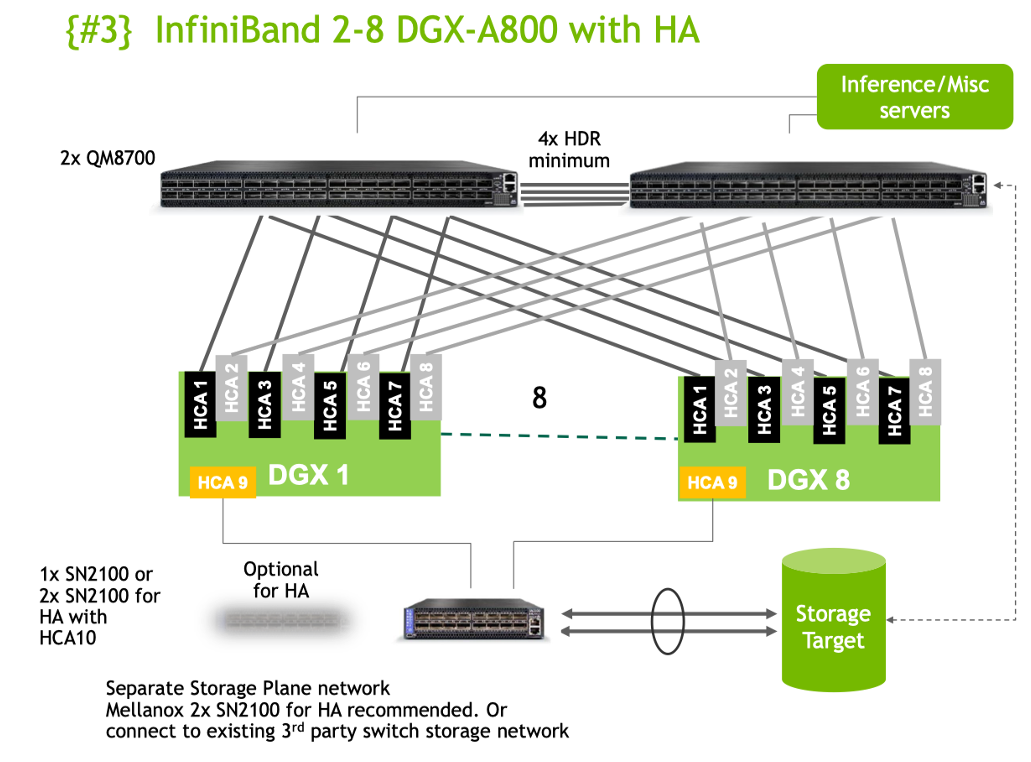
这张图是一个低配版本的胖树和导轨优化拓扑:共配置了2台交换机,QM8700是HDR交换机,两个HDR交换机通过4根HDR线缆相连以保证互联速率;每台DGX GPU节点共9张IB卡(图中的HCA),其中1张给存储(Storage Target),剩下8张给大模型训练。这8张IB卡中的HCA1/3/5/7连到第一个交换机,HCA2/4/6/8连到第二个交换机。
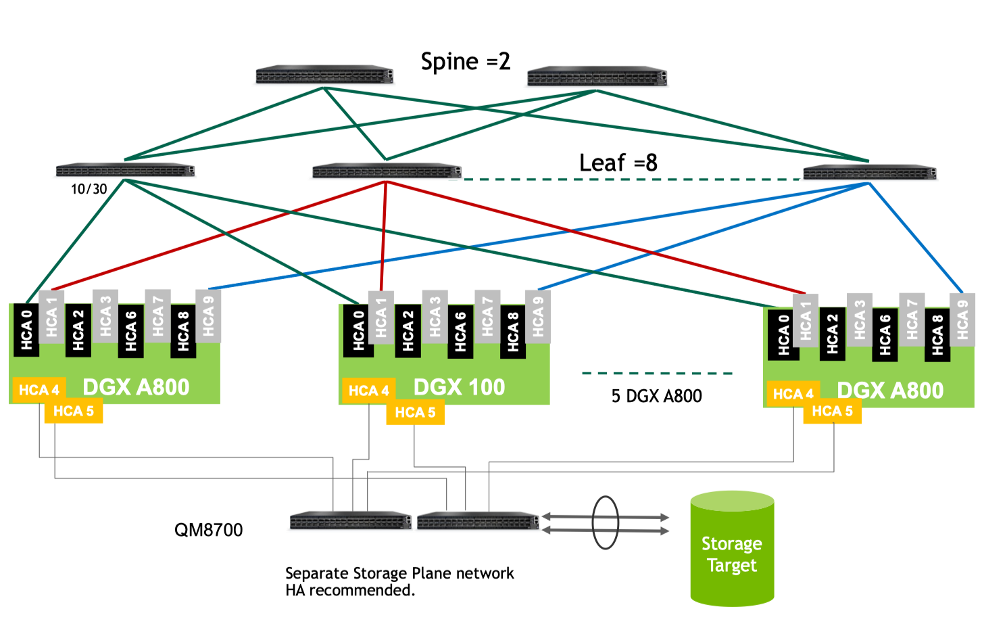
这张图是一张无阻塞全速导轨优化:每台DGX GPU节点共配置8张IB卡,每张卡上连1台交换机,这些交换机被称为叶子(Leaf)交换机,共需8个叶子交换机;确切地说HCA1连第一个叶子交换机,HCA2连第二个叶子交换机,以此类推。叶子交换机之间的通信通过骨干(Spine)交换机来保障速率。
这样做的目的就是为了避免降速,任何一张IB卡都可以和整个网络中其他IB卡高速通信,也就是说,任何一个GPU都可以以极快地速度与其他GPU高速通信。
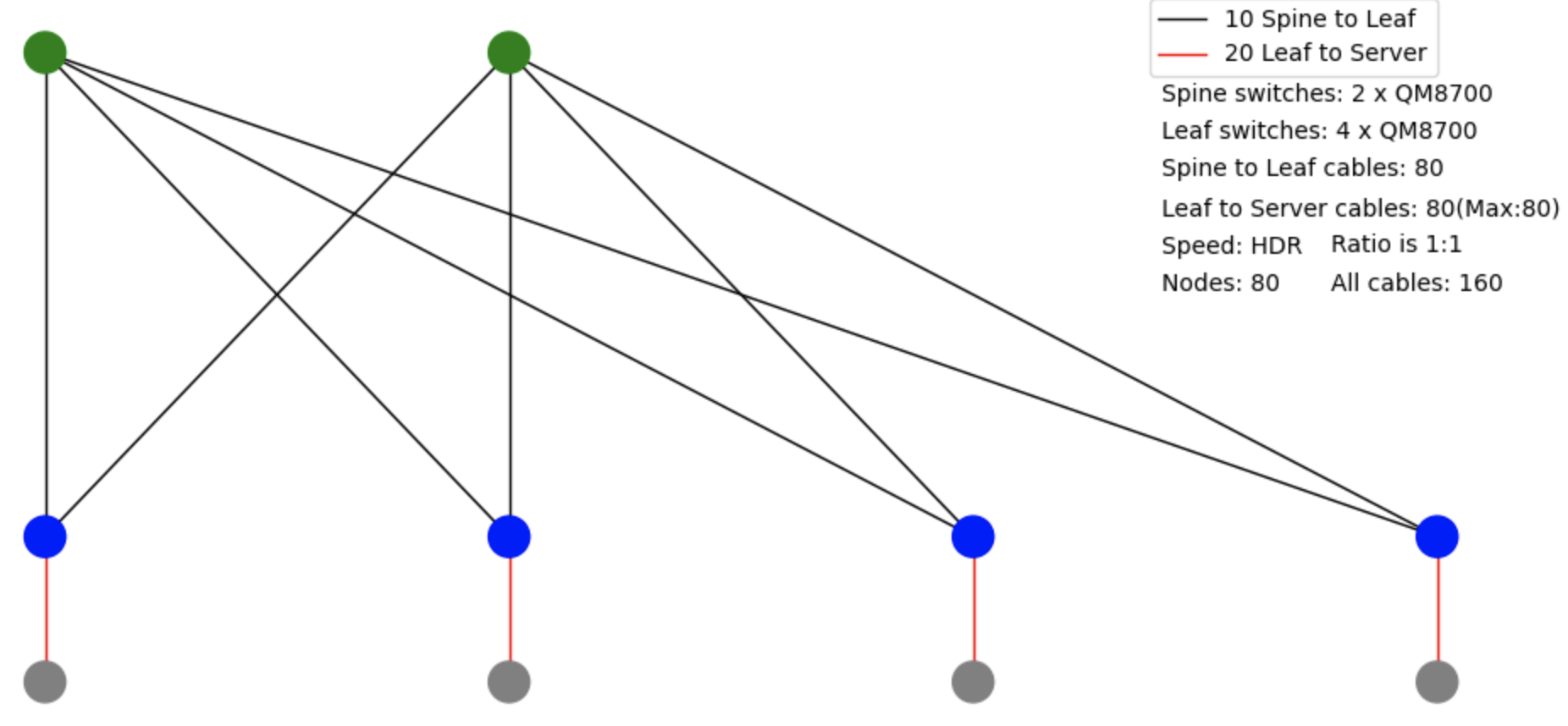
下面这张图是我们实际部署的一个6台交换机组成的全速网络,密密麻麻的线非常恐怖:

它背后的拓扑是下面这个样子,2个绿色的是 Spine 交换机,4个蓝色的是 Leaf 交换机,蓝色和绿色之间共80根线,蓝色下面接计算节点。
SHARP:网络优化
搭建好一个全速网络后,还有一些网络路由方面的优化,比如: Scalable Hierarchical Aggregation and Reduction Protocol (SHARP)。SHARP 是 NVIDIA InfiniBand 网络技术栈中负责进一步优化网络。它提供的一个最核心的功能是:将必须经过 CPU 收发的网络包 offload 到 InfiniBand 交换机上,进一步减少计算节点负载。这样计算节点更专注于计算,而非网络包的收发和处理,同时能减少网络上不必要的流量。
当然,SHARP 也包含在 NVIDIA 提供的驱动中,一个脚本即可开启。
Benchmark
如果想测试你的系统的集合通讯的性能,可以使用nccl-tests这个库,这个库需要依赖CUDA、MPI和NCCL编译,并使用 mpirun 进行多机通信测试。一张HDR(200Gbps)网卡的理论峰值是 24GB/s ,一般情况下,增加 InfiniBand 网卡,就可以获得更高的多机通讯性能。
下面是我们2节点的allreduce实测峰值,网络拓扑为低配版本,GPU为8卡NVLink a800。
| 性能实测 | |
|---|---|
| 1卡 | 16GB/s |
| 4卡 | 30GB/s |
| 4卡 + GPUDirect RDMA | 80GB/s |
| 10卡 + GPUDirect RDMA + SHARP | 95GB/s |
参考资料:
GTC 2023: Scaling Deep Learning Training: Fast Inter-GPU Communication with NCCL
GTC 2020: Distributed Training and Fast Inter-GPU communication with NCCL