MacroBase:斯坦福开源的端到端异常点检测和解释系统
本文和大家分享一个来自Stanford的开源大数据和机器学习系统:MacroBase。
MacroBase源于Stanford的DAWN项目(Data Analytics for What’s Next,下一代数据分析)。Stanford团队称,DAWN项目的初衷是为了让人工智能更加平民化,更多普通人也可以构建AI应用,享受人工智能技术所带来的生产力的提升。可能一些人对DAWN项目并不熟悉,但我们肯定听说过并使用过Apache Spark或Apache Mesos,DAWN团队曾经在这些项目中投入大量研发精力。如今,DAWN开始将视野放到端到端的机器学习问题上,他们构建了一系列工具,希望能够让机器学习工具更加高效,更容易使用。
MacroBase就是DAWN项目中的一个分支,它是一个实时异常点检测系统。定位异常点之后,MacroBase还会对这个结果进行解释,定位到底是哪些因素所影响导致异常的出现。用知乎网友张泰源的解释:“MacroBase不仅会告诉你出事了,还会告诉你为什么出事了。”MacroBase团队发表了很多论文,比如某篇论文获得Best of SIGMOD 2017。本次我主要学习的是他们发表在ACM Transactions on Database Systems上的《MacroBase: Prioritizing Attention in Fast Data》,论文里对MacroBase的具体实现和算法都有详细的介绍。同时,MacroBase代码也在github开源了:https://github.com/stanford-futuredata/macrobase 。
背景
工业界为了快速定位问题,通常会对各类设备进行监控,监控数据会实时上传到服务端。比如,大型数据中心在运维时会收集物理机、虚拟机和应用程序上的的各类数据,用以监控服务器和程序是否正常运行。AWS美国东部的数据库曾爆出异常,影响了运行在其上的Netflix和Reddit的应用。但是,AWS的工程师并没有及时跟进解决,造成了重大损失。
这类监控问题可以被归纳为异常点检测问题。异常点检测的一大挑战是数据量太大,数据速度太快,人的精力很难覆盖这么庞大的数据量。因此,论文的题目是Prioritizing Attention in Fast Data,如果人力无法胜任这么庞大的工作,可以先让机器做一些初步的分析,MacroBase对流数据做了提纯,自动识别出流数据中的异常,并进行异常的归因,以此节省人的精力。
系统设计
MacroBase是一个流处理系统,它实时监测数据流,进行异常点检测,并对异常结果进行解释。它是一个实时流处理系统,使用了流处理界领先的Dataflow模型。下图为MacroBase一个数据分析工作流(Pipeline),可以看到,这个图与Spark的有向无环图(DAG)模型、Flink的数据流图模型极其相似。
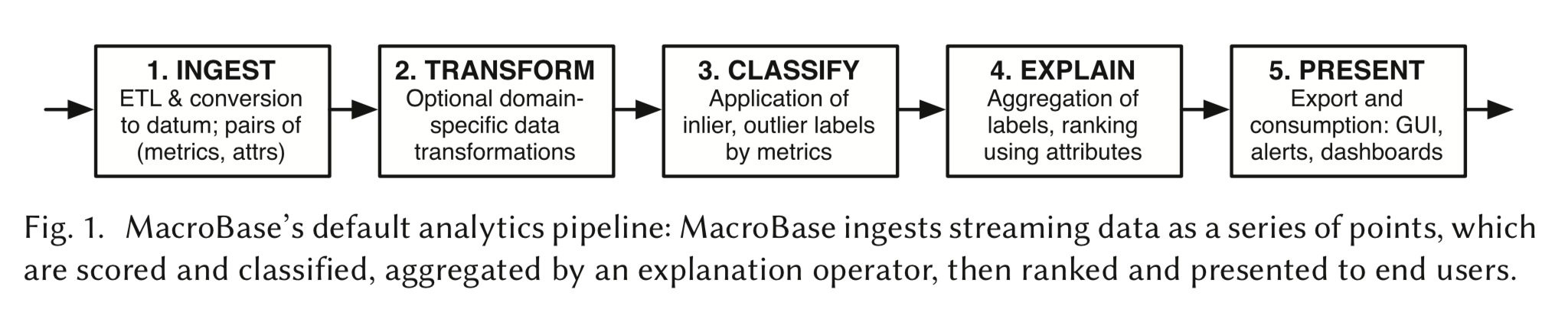
MacroBase Dataflow模型
整个Pipeline分为五大部分:
- Ingest:数据的输入。可以从外部数据源经过ETL转化,将数据导入MacroBase。
- Transform:对数据进行一定的转化处理。比如,进行时间维度上的处理:设置时间窗口、去除时间序列数据中的周期性偏差(Seasonality Removal)等;进行一些统计学处理:数据归一化、数据降维等;针对特定领域的数据处理:对视频数据使用光流处理(Optical Flow)等。
- Classify:数据经过Transform处理后,MacroBase使用一些模型进行分类。最简单的模型是规则,MacroBase默认使用的是无监督模型,即基于数据的统计学特性区分出哪些是正常点(Inlier)、哪些是异常点(Outlier)。MacroBase也支持用户使用自己的监督学习模型。
- Explain:基于刚刚分类结果,生成一些解释,以告知使用者哪些特征导致了异常点。比如,数据中心运维案例中,分析出型号为5052的机器产生了更多异常点,但是正常数据里,这样的数据模式不明显。
- Present:将解释结果展示给用户。解释结果是一个列表,最有可能导致异常的特征会被排在最前面。
MacroBase是一个框架,其核心功能是在数据流上进行Classify和Explain。因为MacroBase是一个框架,它允许用户在已有的基础上进行扩展,比如自己定义Classify所使用的机器学习模型。
如果用户不进行自定义,MacroBase提供了一个默认的Pipeline,这个Pipeline是基于无监督学习的,数据流图如下所示。
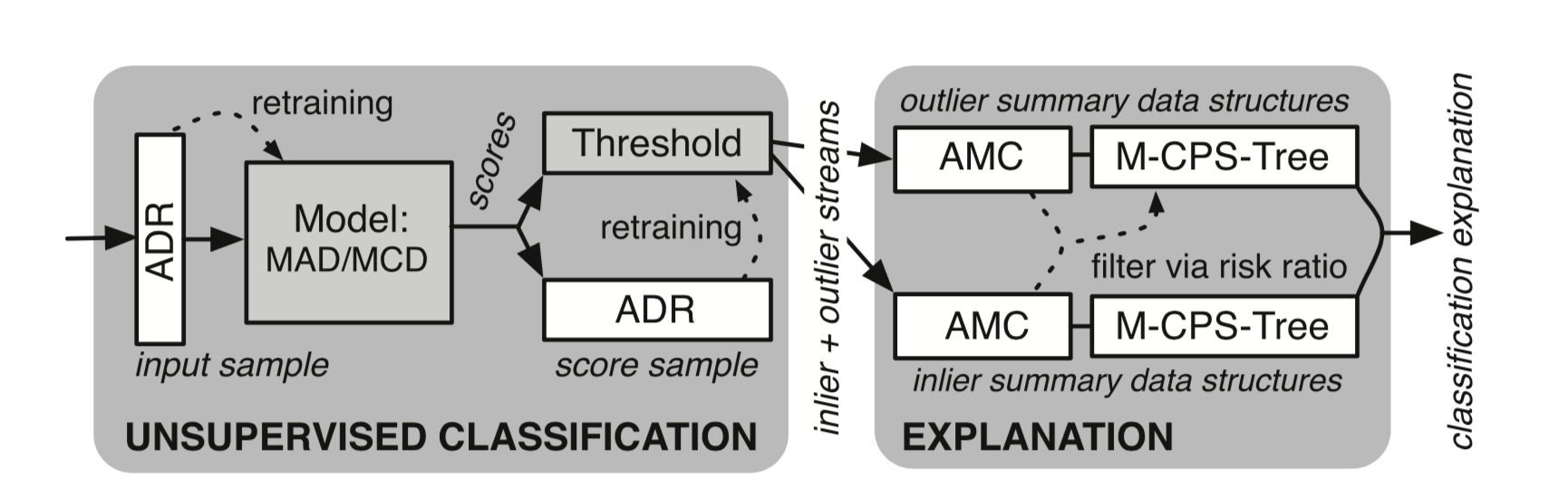
MacroBase默认的无监督学习Pipeline
这张图省却了Ingest、Transform和Present几个阶段,重点展示了Classify和Explain过程。图中的专有名词缩写较多,下面会逐一进行解释。
Classify
这里先绕开MacroBase,谈谈数据流上的机器学习。对于数据流上进行机器学习模型的在线预测,最简单有效的办法都是基于监督学习模型。一般是离线训练好一个模型,线上系统读取加载这个模型,每接收到一条新数据,线上系统根据离线模型来预测新流入数据。离线模型一般非常准确,但是离线模型一般是基于批处理的,更新速度较慢。目前,我们身边很多机器学习应用都是使用很久以前训练的模型,来预测未来新流入的数据。
数据流上的无监督学习其实是一个巨大的挑战。无监督学习一般需要对整个数据集进行遍历和学习,当学到一些参数后,再用来进行新一轮的预测。在批处理领域,训练的问题似乎并不难,因为数据本身就是批量存储的。但是在数据流上,尤其是高速数据流上,计算引擎一般是将数据缓存在本机的内存或者磁盘中,内存和磁盘的所能承载的数据量是有限的,因此,如果数据量巨大,我们是不可能将整个数据集缓存下来的。另外,流数据本身有时效性,在绝大多数流处理场景下,人们只对最近的数据比较关注,一个月之前、一星期之前或者一天之前的数据必须经过衰减才行。
MacroBase对此采用的方案是采样(Sample)。对于采样问题,有一个专门的名词:Reservoir Sampling。Reservoir Sampling表示,当数据总体共有n条,n非常大,且n对于流处理来说未知,将n条数据都放入内存不现实,需要使用一定的采样方法不断生成一个k条数据组成的样本。系统刚启动时,内存中的数据小于k,当数据慢慢增多,达到k的限制时,需要使用一种机制,将新数据替换已有的k条数据,以不断更新样本。MacroBase提出了一个名为Adaptable Damped Reservoir(ADR)的算法,用来动态生成样本集。生成样本集的过程需要考虑两个问题:1. 每条流入数据能够进入样本的概率应该是一样的;2. 数据能够根据时间衰减。MacroBase的ADR采样算法考虑了这两个问题,主要基于两个思想:1. 每条数据赋予一个权重(Weight),最终的采样概率跟权重正相关;2. 对权重进行时间上的衰减。从经验上来讲,MacroBase的ADR采样算法应该是可行的。在图中,ADR也是整个过程的入口。
接着是在数据集上进行无监督学习过程。MacroBase使用了异常点检测算法,常见的异常点检测一般基于样本数据的统计学特性,由于本人专长并不在统计学上,因此这里只做一些简单介绍。最传统的异常点检测假设数据基于正态分布,那么偏离均值(Mean)几个标准差(Standard Deviation)的数据可以被认定为异常点。这种朴素的思想有一个缺点,那就是一个偏离较大的异常点很可能造成整个样本均值和标准差的偏离。对此,MacroBase将目光转向了中位数。对于一元数据,它使用了Median Absolute Deviation(MAD)方法,因为中位数对异常点更不敏感,能够抵消异常点带来的样本偏离。对于多元数据,它使用了Minimum Covariance Determinant(MCD),主要基于Mahalanobis 距离。无论是一元的MAD还是多元的MCD,其实都是已有的异常点检测算法,在搜索引擎中搜索可以了解这两个方法的具体计算过程,这里不再详细叙述。在上图中为Model部分所使用的算法。
经过MAD或MCD两个统计方法的计算,我们可以确定一个阈值,超过阈值的数据可以被认定为异常点。比如,我们设定99分位值的数据为阈值边界,超过99分位的数据被识别为异常点,其他数据被认定为正常数据。在批处理领域,对于一个数据集,这个边界可能是确定的,但在流处理领域,数据不断流入,阈值也需要不断更新。MacroBase使用了第二个ADR采样,用来计算阈值。
Explain
有了阈值,我们就可以识别出异常点了。对流入数据分类后,进入到下一环节:Explain。假设数据有M维特征,到底哪些特征导致异常点区别于正常点呢?MacroBase使用了一个流行病学的概念:相对风险(Risk Ratio)。举个例子,如果吸烟者发生肺癌的概率是20%,而非吸烟者发生肺癌的概率为1%,从是否吸烟这个特征上来讲,吸烟者相比非吸烟者有20倍的相对风险发生肺癌。可见,Risk Ratio表示某个属性相比其他属性来说更可能导致异常点出现。用原文的话来描述Risk Ratio:
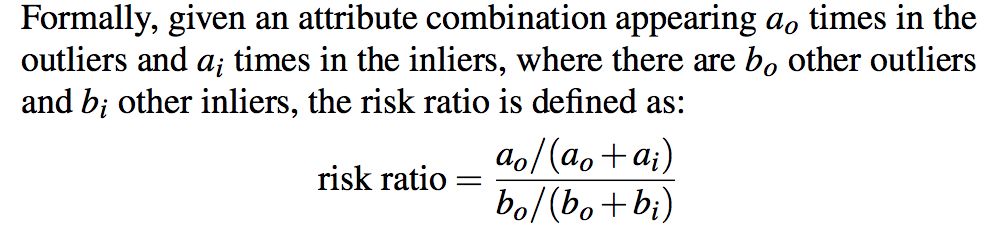
在数据中心的例子中,我们可以计算特征机器型号相比特征机房房间号哪个Risk Ratio更高,就说明哪个属性最有可能导致了机器异常。这个问题在数据挖掘中被称为Frequent Patterns Mining,即发现数据集中出现频次比较高的某种模式。MacroBase使用了韩家炜2000年提出的FPGrowth算法。
然而,这又是一个批处理容易,流处理很难的问题。当然还是因为流处理无法记录所有的数据。MacroBase提供的思路为Amortized Maintenance Counter(AMC)和CPS-Tree,其大致思想是,在处理过程中要丢掉一部分数据,牺牲一定准确度来换取实时性。
小结
MacroBase融合了数据库、计算引擎、机器学习等多个领域,并在这些领域的顶级学术会议上获得非常好的反响,可谓是机器学习的集大成者。另一方面,其实MacroBase中使用的绝大多数方法和思路都是基于前人的工作,它最大的贡献就是将一些方法和思路落地,并且开源了出来。通过论文和开源代码,可以窥见Stanford实验室超强的工程能力。实际上,在计算机工程实践上,算法模型的力量固然重要,但是将算法落地,能够提供实际的价值,这是绝大多数从业人员所要面对和解决的问题。从这个角度来讲,MacroBase项目本身开源出来就是一大成功。