Python机器学习库是如何打包并安装的
尽管依赖问题非常棘手,但明白包管理以及包编译安装原理有助于我们深刻理解计算机基本原理,避免成为一个调包侠。
最近在一台GPU机器上安装了LightGBM,主要是希望LightGBM能够利用GPU的算力进行加速,中间遇到GPU驱动以及CUDA等问题,断断续续持续了一个月才完全使其正常运行。为了彻底弄明白Python打包和安装依赖的问题,我下载了LightGBM、TensorFlow等机器学习库的源码,并做了一些调研。
为什么pip安装的机器学习库对GPU支持不好
对于主流机器学习库,比如TensorFlow、PyTorch、LightGBM等,主要都是使用C/C++编写的。C/C++有如下优势:
- 如果用Python语言实现,Python解释器(例如CPython)会将Python代码翻译转化成机器能够理解的代码。而C/C++代码被直接编译成机器码,能够充分利用CPU、GPU等硬件的算力。
- CPython有一个限制并行计算的GIL锁。C/C++程序能够更好地进行并行计算,避免了CPython的GIL锁。
- C/C++可以显式(Explicitly)管理变量和内存,处理结果具有确定性(Deterministically)。
以TensorFlow为例,它提供了Python的调用接口,用户一般用Python来调用TensorFlow。实际上,其底层代码绝大多数是用C/C++编写的。Python只是TensorFlow的一个前端(Front End),Python需要通过调用C语言的API,进而调用底层的TensorFlow核心库。它的架构图如下所示:
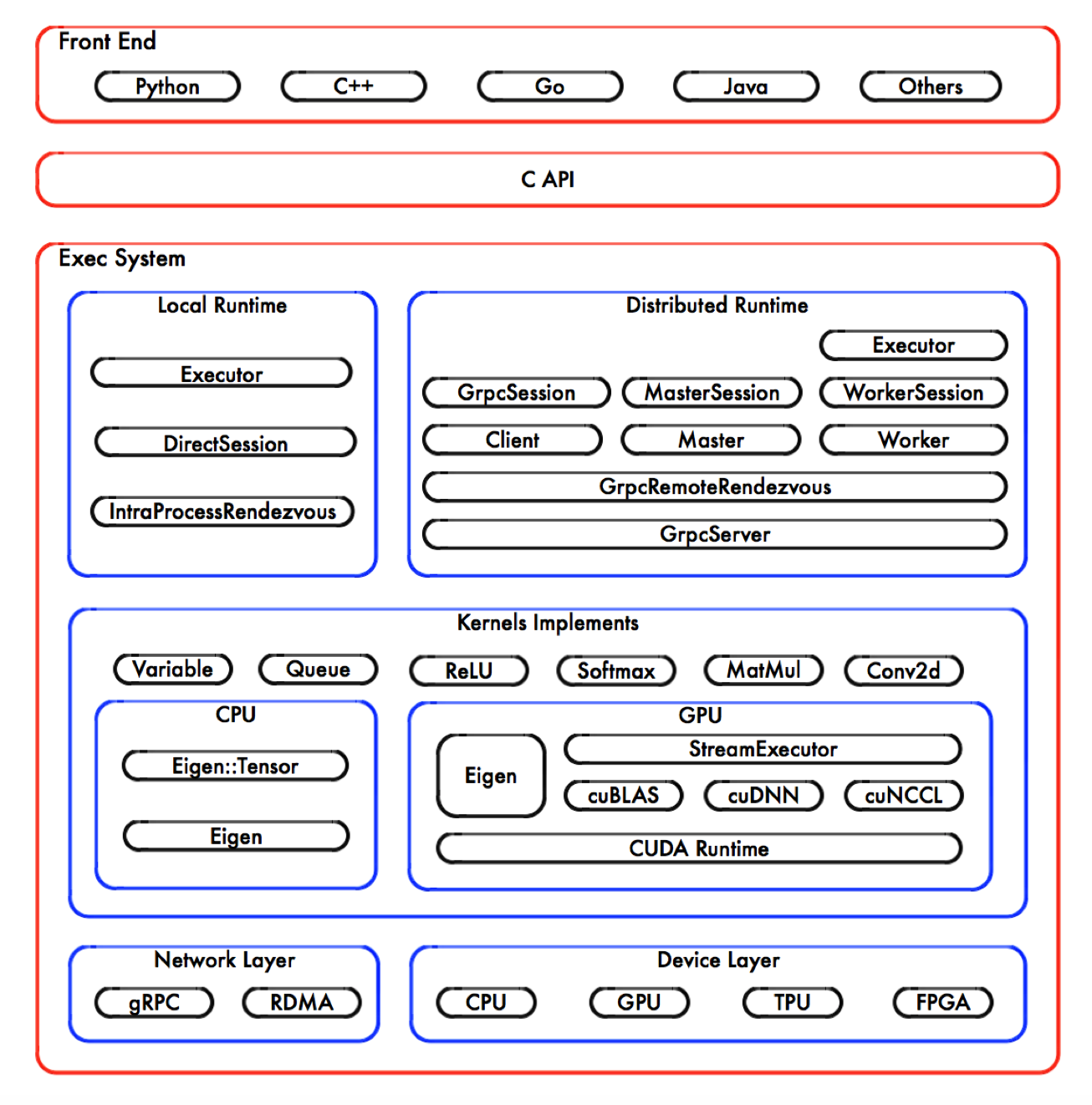
TensorFlow架构图 来源:TensorFlow Internals
上图中,最底层是硬件,包括了网络和计算设备,这里先只关注计算设备。由于CPU、GPU等硬件设计的区别,一些矩阵运算在不同硬件上的机器码有质的区别。线性代数部分一般基于Eigen库,这是一个专注于向量和矩阵运算的C++库;Eigen::Tensor是一个使用C++模板技术,它可以为多核 CPU/GPU 生成高效的并发代码。

英伟达GPU软硬件依赖栈
GPU部分最底层是操作系统和驱动,再往上是提供给程序员的开发接口CUDA。英伟达在CUDA之上提供了cuBLAS、cuDNN等库,cuBLAS是运行在英伟达GPU上的线性代数库(Basic Linear Algebra Subprograms,简称BLAS),cuDNN是英伟达为优化深度神经网络,在CUDA上包装的库,里面包含了Tensor计算、卷积、池化等常见DNN操作。cuBLAS和cuDNN代码会最终编译成英伟达GPU可运行的机器码。
相关信息
cuDNN对英伟达硬件、驱动和CUDA版本有依赖要求,由于版本迭代,新版本的cuDNN只能运行在高版本的驱动和CUDA上。英伟达官方提供了版本依赖表。对于使用英伟达GPU的朋友,第一件事是基于自己的硬件安装最新的驱动。如果驱动、CUDA和cuDNN版本与上层应用不匹配,容易出现各类问题。很多时候,我们按照网上的教程安装了驱动、CUDA,并用pip安装了TensorFlow,最后发现有99%的概率依然用不了。因为,TensorFlow提供的pip安装包主要基于下面的版本进行构建的。
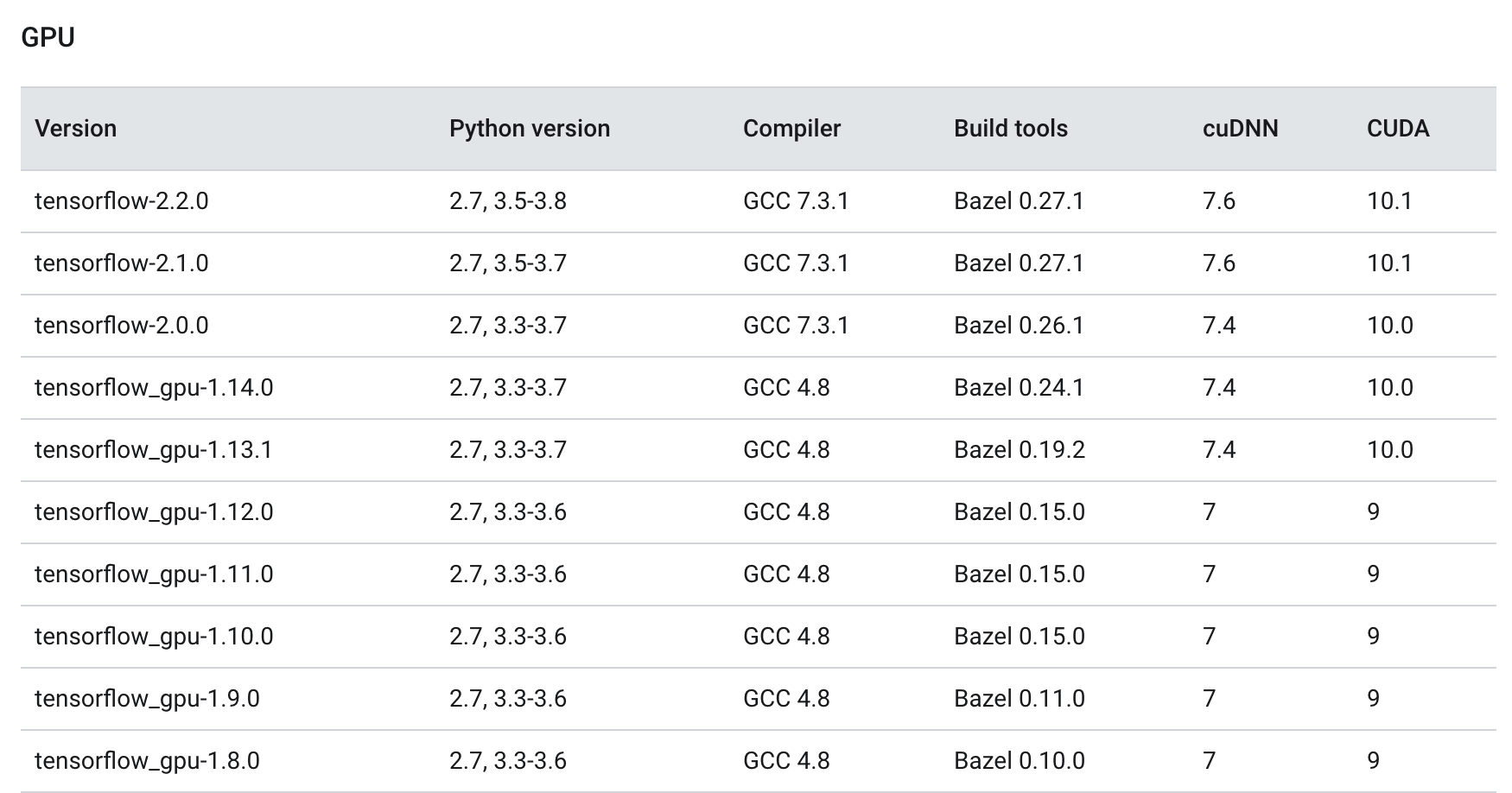
TensorFlow官方提供的经过测试的版本依赖关系
到底什么是包
广义上来讲,包(Package)其实就是一个软件集合,安装完包之后,我们就可以使用包里的软件了。Windows上缺少包的概念,类Unix系统一般使用包管理软件(Package Manager)来管理和安装软件,我们在手机上常用的应用商店其实就是一个包管理软件。软件发布者将编译好的软件发布到包管理仓库(Repository,简称Repo),用户通过包管理软件来下载和安装,只不过类Unix系统一般使用命令行来安装这些软件。
常见的包管理有:
在操作系统上安装软件:
- Ubuntu的apt、CentOS的yum、macOS的homebrew
在编程语言中安装别人开发的库:
- Python的pip、Ruby的Gem
包管理软件有对应的Repo:
- pip的PyPI,conda的Anaconda.org、R的CRAN
无论包管理模式如何,这些包管理系统都会帮助我们解决:
管理源码(Source Code)或者编译打包之后的二进制文件(Binary)。
解决软件包之间的依赖问题。比如,LightGBM还依赖了NumPy等其他包。部分依赖还对版本号有要求。
从源码开始编译一个包其实很麻烦:
很多时候需要基础环境一致,这包括操作系统版本(高版本的操作系统glibc版本比较高,一些新兴机器学习包一般基于更高版本的glibc,这些包无法安装到低版本的操作系统上)、编译工具(例如类Unix系统的GCC、CMake,Windows上的Visual Studio等)。
当前包所依赖的其他软件,比如GPU版的TensorFlow所依赖的cuDNN、LightGBM所依赖的NumPy等。
编译过程相当耗时。比如,TensorFlow的构建时间就非常长。
因此很多包管理系统在发布的时候,提供二进制文件。二进制文件下载解压之后就可以运行了,有点像Windows上的绿色免安装软件。但是:
- 别人编译好的软件是在别人的基础环境上进行的,这就导致这个软件非常依赖当初编译它的环境。
- 安装当前包之前肯定要先安装好这个包所依赖的软件包。
可见,包管理也是一个有一定挑战的问题。就像很多桌面软件和游戏只有Windows的版本一样,一些大数据、深度学习类的应用因为基于Linux环境开发和构建,常常对Linux支持更好。
pip和conda
回到Python的包管理上,经过这些年的发展,Python领域目前有两大主流包管理系统:pip和conda。那这两个到底有什么区别呢?
pip是Python官方的包管理工具:
- 它从PyPI(Python Package Index)上拉取数据,或者说它的Repo在PyPI上。绝大多数的Python包会优先发布到PyPI上。目前(2020年5月),PyPI上的项目有23万之多。
- 支持源码和二进制文件,二进制文件以Wheel文件形式存在。
- 只支持Python,不关注其他一些非常重要但是更加底层的软件包,比如针对Intel CPU加速的数学库Intel MKL。
pip安装包时,尽管也对当前包的依赖做检查,但是并不保证当前环境的所有包的所有依赖都同时满足。这可能导致一个环境的依赖冲突,当某个环境所安装的包越来越多,很早之前安装的包可能和当前包相互冲突。
conda是另外一个被广泛应用的工具,它:
它从Anaconda.org上拉取数据。Anaconda上有一些主流Python包,但在数量级上明显少于PyPI,缺少一些小众的包。
它只支持二进制文件,二进制文件是提前编译好的。
不仅支持Python,还支持R、C/C++等其他语言的包。
提供了环境隔离,可以使用
conda命令创建多个环境,每个环境里安装Python、R等环境,某个特定的环境内包含了独立的Python解释器,不同环境之间互不影响。相比而言,pip只提供安装功能,多环境之间的隔离需要依赖另外的工具(如virtualenv)来完成。从这个角度来讲,conda可以管理Python解释器,而pip必须依附于Python解释器。conda在安装包时,对所安装包的依赖检查更严格,它会保证当前环境里的所有包的所有依赖都满足。
| conda | pip | |
|---|---|---|
| Repo | Anaconda,包数量远少于PyPI | PyPI,Python包会被优先发布到PyPI上 |
| 包内容 | 二进制 | 源码和二进制 |
| 支持语言 | Python、R、C/C++等 | 只支持Python |
| 多环境管理 | 可以创建多个环境,环境内包含Python解释器 | 本身不支持,需要依赖其他工具 |
| 依赖检查 | 严格的依赖检查 | 依赖检查不严格 |
可以看到,目前没有一个完美的Python包管理模式,conda虽然对依赖检查更严格,但是它支持的包比较少。pip对依赖检查不够严格,会导致环境的冲突,但是很多Python包,尤其是一些小众的Python包会优先发布到PyPI上。因此,我们可能需要将conda和pip结合起来,并且要善于创建不同的环境,每个环境处理某些具体的计算任务,以免环境里的各类包越来越臃肿,造成依赖冲突。
机器学习库安装方法
TensorFlow
如果想在GPU上使用TensorFlow,官方建议使用Docker。用户只需要安装GPU驱动即可,连CUDA都不需要安装。Docker在一定程序上能解决环境的隔离。
如果不习惯使用Docker,一些文章推荐使用conda来安装TensorFlow。因为conda不仅管理Python,还支持C/C++的库。因此在安装TensorFlow时,它不仅将TensorFlow所需要的一些二进制文件下载安装,还安装了一些其他依赖包。
使用conda创建一个名为tf_gpu的虚拟环境,安装GPU版本的TensorFlow:
conda create --name tf_gpu tensorflow-gpu
安装过程中显示除了TensorFlow本身,conda还将安装包括CUDA、cuDNN在内的依赖包:
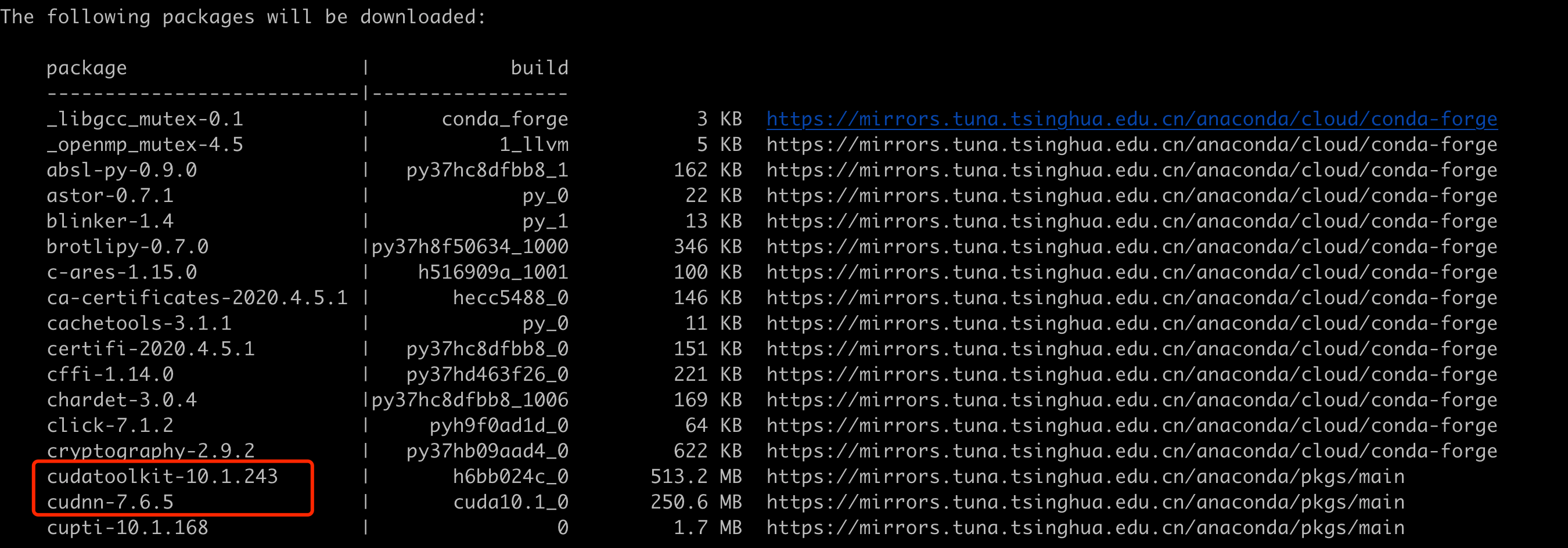
conda安装TensorFlow时会安装相关依赖,包括CUDA、cuDNN、BLAS等
LightGBM
相比TensorFlow,LightGBM尽管也在Anaconda.org上有二进制文件,但是并没有明确是否支持GPU,其官方文件中GPU版本是基于源码安装的。因此,LightGBM可以作为一个小众的案例。
如果我们使用pip安装LightGBM,可以直接安装二进制文件,也可以从使用源码安装。
在LightGBM的PyPI页面中显示,LightGBM依赖C/C++库,比如Windows的Visual Studio(2015或更新版本),Linux的glibc >=2.14。
拉取二进制文件并安装:
pip install lightgbm
使用源码安装,Linux和macOS需要先安装CMake。
pip install --no-binary :all: lightgbm
# 安装GPU版本
pip install lightgbm --install-option=--gpu
安装GPU版本之前需要先安装GPU驱动。LightGBM使用开源的OpenCL而不是CUDA进行GPU加速,因此还要安装OpenCL。使用源码安装本质上是使用CMake将C/C++代码编译,编译过程中依赖了本地的基础环境,包括了C/C++各个类库、GPU驱动、OpenCL等。
安装命令成功执行之后,LightGBM会被放在当前Python解释器的site-packages目录下。
cd prefix/lib/python3.6/site-packages/lightgbm
tree
.
├── basic.py
├── callback.py
├── compat.py
├── engine.py
├── __init__.py
├── lib_lightgbm.so
├── libpath.py
├── plotting.py
├── __pycache__
│ ├── basic.cpython-36.pyc
│ ├── callback.cpython-36.pyc
│ ├── compat.cpython-36.pyc
│ ├── engine.cpython-36.pyc
│ ├── __init__.cpython-36.pyc
│ ├── libpath.cpython-36.pyc
│ ├── plotting.cpython-36.pyc
│ └── sklearn.cpython-36.pyc
├── sklearn.py
└── VERSION.txt
安装之后会有一个lib_lightgbm.so的动态链接库。这是C/C++代码编译之后生成的库,Python通过ctypes来访问动态链接库中的C/C++接口。于是,我们就可以在Python中调用这些C/C++的程序。
小结
为了避免依赖问题,我们可能需要按照下面的顺序来管理我们的Python包:
- Docker
- conda
- pip
- 源码安装
尽管依赖问题非常棘手,但明白包管理以及包编译安装原理有助于我们深刻理解计算机基本原理,避免成为一个调包侠。