没数据?数据共享难?担心隐私和安全?试试联邦学习
什么是联邦学习
联邦学习(Federated Learning)是这几年开始流行的概念,其主要解决的问题是:在各国数据隐私监管越来越严格的大背景下,企业和研究机构不能在随意贩卖、购买或交换涉及用户隐私的数据,没有数据,也就无法利用深度学习来训练神经网络模型,无法构建强大的人工智能。
这里说的“数据”,绝大多数是涉及用户的个人数据。比如,APP上的搜索和浏览记录、个人消费和金融信息、就医历史等。这些用户数据贴近人的隐私,是监管部门重点监控的地方。我曾在大公司工作过,对于大公司来说,坐拥大量用户,公司会一直收集用户的各类信息,业务部门A收集到的数据有可能共享给业务部门B。比如,在某个APP中搜索过某个关键字,在同一个公司另一个APP,你可能很快就看到关于这个关键词的广告。但对于中小企业和研究机构,他们没有收集用户数据的工具、平台和能力,无法获得这些数据,也就无法基于这些数据做太多数据分析和机器学习的应用。在监管还未特别严格的时候,一些公司会通过一些地下渠道买卖数据。但现在,买卖用户数据已经是红线了,绝大多数企业不敢再冒着危险买卖数据,除非有些人就是做数据黑产,就是想干一票就跑路,不在乎公司长久发展。
所以,现在的问题是,数据被所拥有的企业独享,数据之间无法共享。“数据孤岛”这个词专门用来描述这种状况。数据无法共享的问题在高校来说尤其严重,因为高校无法收集真实业务场景的数据,也就无法基于真实业务场景进行科研。绝大多数的高校研究者基于网络上经过脱敏的公开数据集,公开数据集多多少少都经过了一些处理,无法还原企业真实情况。另外一些高校有能力和企业合作,教师一般会将学生派往企业,在企业的服务器上进行数据相关操作,数据决不能从企业的数据中心流出,这种方式的交通和管理成本都较高。
传统的机器学习都是将“大而全”的数据放置在数据中心,模型的训练都会集中在单个数据中心内。联邦学习希望解决数据无法共享的问题。联邦学习能够充分的利用参与方的数据、计算和建模能力,使多方可以协作,构建通用的机器学习模型,而不需要共享数据。在数据监管越来越严格的大环境下,联邦学习能够解决数据所有权,数据隐私权,数据访问权等关键问题,所以自从联邦学习的概念提出后就获得了人工智能行业的追捧,目前已经在很多行业受到一定的应用,比如国防,电信,医疗和物联网等。
联邦学习可以:
- 各方数据都保留在本地,不泄露也不违反法律法规
- 多个参与者联合数据,建立一个共有的模型,并共同获利
- 比起将各方数据集中在一起,联邦学习必须要保证效果相差不大
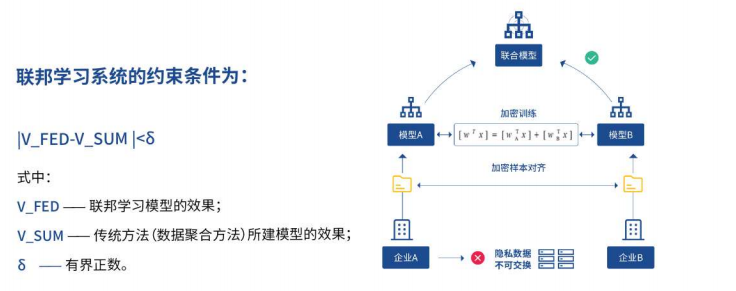
联邦学习的定义
数据堂CEO齐红威给出一个更为形象的解释。我们把机器学习比作养羊,羊就是机器学习模型,羊吃的草就是数据。传统的集中式机器学习是将大草原上的草都收割好,送到羊圈里给羊统一吃,羊一直固定在羊圈中。联邦学习不再将羊固定在羊圈中,而是改成游牧,去不同的草场上去吃草。
联邦学习的三种类型
微众银行(WeBank)在发布了联邦学习的白皮书。微信搜索ilulaoshi,关注公众号,回复“联邦学习”,获取白皮书。
白皮书将联邦学习分为三类,横向联邦学习,纵向联邦学习和联邦迁移学习。这个分类主要依据数据的分布情况。比如,我们要对一个用户建模,用户为U1、U2...每个用户都有各类特征X1、X2、X3...用户的标注被称为标签,在金融领域,用户的信用可能是我们想要预测的标签;在电子商务领域,用户的购买欲望可能是我们想要预测的标签;在教育领域,学生的成绩可能是我们想要预测的标签。那么数据分布可能分为三种情况:
- 两个数据集的用户特征(X1、X2...)基本一致,但是用户(U1、U2...)重叠度较小:比如两家银行的APP上的业务逻辑基本一致,某位用户主要使用银行A,另外的用户主要使用银行B。从两家银行的角度来讲,用户重叠度小。
- 两个数据集的用户(U1、U2...)重叠部分较大,而用户特征(X1、X2...)重叠部分较小:比如学而思培训机构和楼下的麦当劳有很多用户都是重叠的,因为很多学生和家长都会在学而思上课,在麦当劳买份快餐,但是学而思和麦当劳收集到的用户特征不一样。
- 两个数据集的用户(U1、U2...)和用户特征(X1、X2...)都不一样:比如美妆店和数码店的用户和特征都不太一样,一家美国的商超和一家中国的银行收集到的用户数据就不一样。
横向(Horizontal)联邦学习,纵向(Vertical)联邦学习和联邦迁移(Transfer)学习这三类分别对应以上三种数据分布。
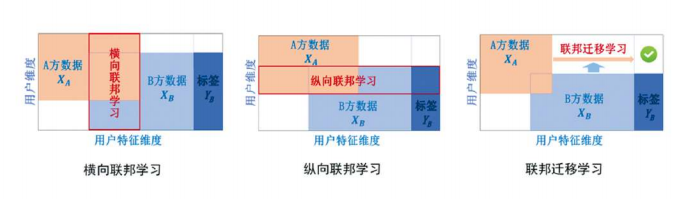
联邦学习的分类
横向联邦学习
横向联邦学习的特点是业务(特征)相似,但是用户(样本)不同。
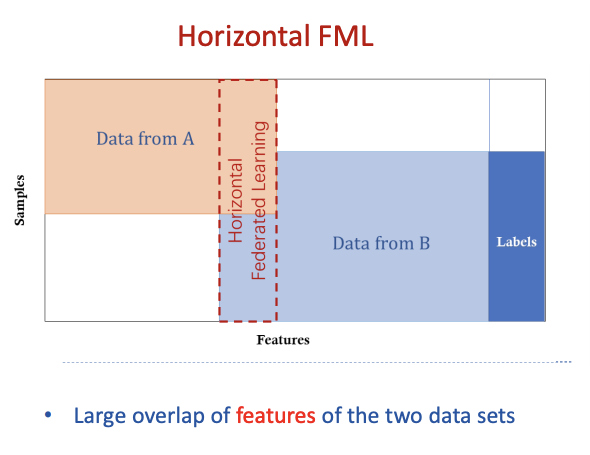
横向联邦学习
这种情况下的处理过程一般是这样:
参与方各自从服务器A下载最新模型;
每个参与方利用本地数据训练模型,加密梯度上传给服务器A,服务器A聚合各用户的梯度更新模型参数;
服务器A返回更新后的模型给各参与方;
各参与方更新各自模型。
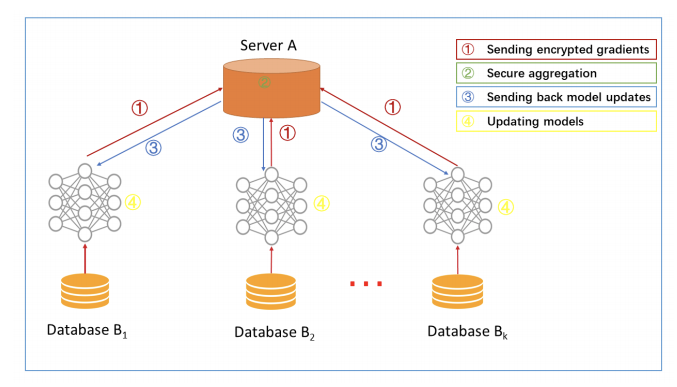
横向联邦学习架构
纵向联邦学习
纵向联邦学习的特点是分布式的数据集中大量的用户,服务器利用这样的数据来训练对应的用户的模型,但是并不获取相关的数据。
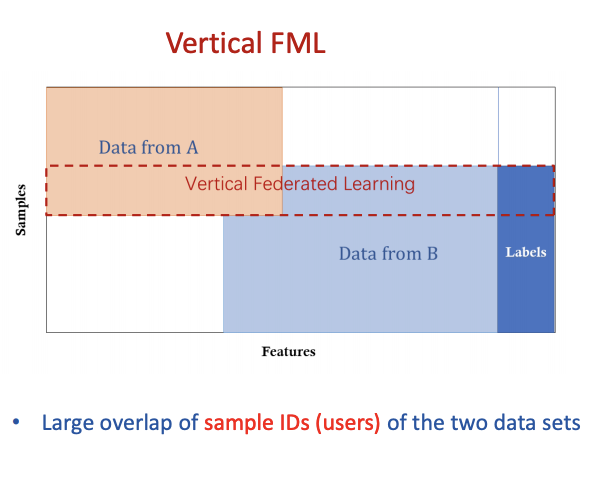
纵向联邦学习
比如,多家机构,一家是当地的商超,一家是旅行社,最后是微众银行。商超有用户的消费和购买历史,旅行社有用户的商旅消费信息,银行有用户的收支和信用记录。不同机构的用户特征不同,将这些特征联合起来,对于不同机构都有重要的商业价值。
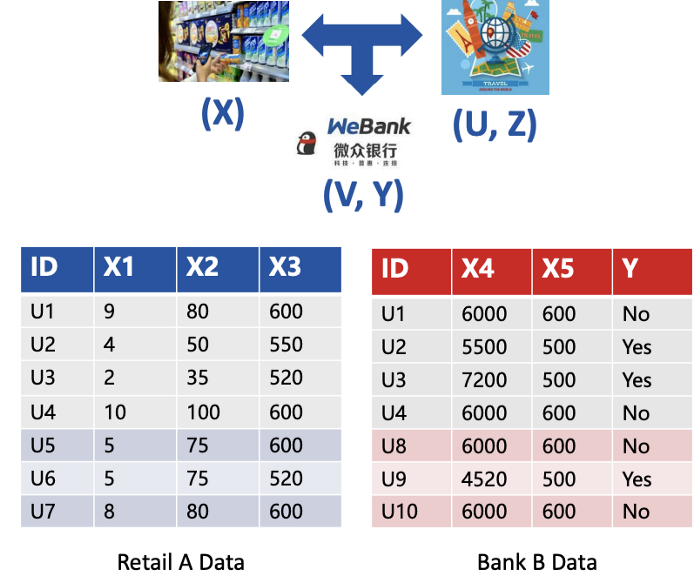
纵向联邦学习的业务场景
纵向联邦学习的架构如下:
- 服务器向客户端发送公钥
- 客户端间交换中间的训练结果
- 加密汇总后的梯度与损失数据
- 更新模型
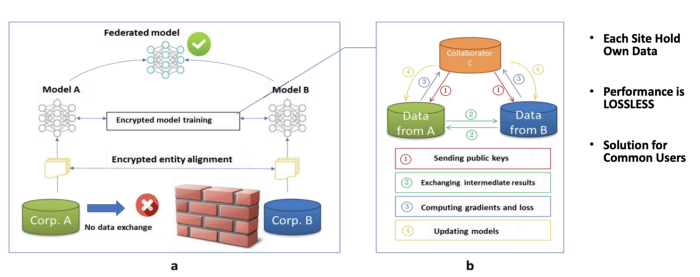
纵向联邦学习架构
联邦迁移学习
联邦迁移学习适用于参与者间特征和样本重叠都很少的场景,比如不同地区的银行和商超间的联合学习。
迁移学习是指利用数据、任务、或模型之间的相似性,在源领域训练过的模型,应用于目标领域的一种学习过程。说白了就是照猫画虎。我们都知道在中国大陆开车时,驾驶员坐在左边,靠马路右侧行驶。这是基本的规则。然而,如果在英国、香港等地区开车,驾驶员是坐在右边,需要靠马路左侧行驶。那么,如果我们从中国大陆到了香港,应该如何快速地适应 他们的开车方式呢?诀窍就是找到这里的不变量:不论在哪个地区,驾驶员都是紧靠马路中间。这就是我们这个开车问题中的不变量。 找到相似性 (不变量),是进行迁移学习的核心。
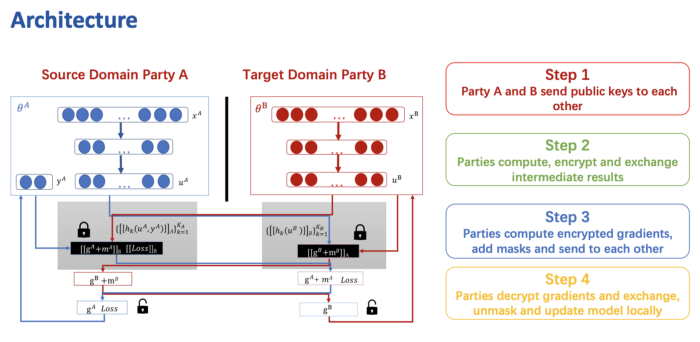
联邦迁移学习架构
联邦迁移学习的基本步骤为:
- 双方交换公钥
- 双方分别计算加密和交换中间训练结果
- 双方计算加密后的梯度,加上混淆码发给对方
- 双方解密梯度,并交换,反混淆并更新本地的模型
相比前两种联邦学习,联邦迁移学习的难度最大。
参考资料