Hello World背后的故事:如何在Linux上编译C语言程序
C语言的经典程序“Hello World”并不难写,很多朋友都可以闭着眼将它写出来。那么编译一个“Hello World”到底经历了怎样的过程呢?
从源代码到可执行文件
我们将这个文件命名为hello.c:
#include <stdio.h>
int main() {
printf("Hello World\n");
return 0;
}
程序的第一行引用了stdio.h,stdio.h里有一些C标准库预定义好的方法,比如printf()方法,printf()方法可将字符串打印到标准输出流。
接着,int main()定义了主函数,是这个程序的入口。main()方法的返回值是int,在本程序中,我们返回了0,0表示程序正常结束,非0的结果表示程序异常结束。
在进行下一步的编译之前,我们需要明确:计算机基于二进制,运行在计算机上的程序和数据本质上都是二进制的。二进制写起来难度太大,不适合开发,于是人们一步步抽象,最后发明了高级语言,比如C、C++、Java、Python等。使用高级语言编程,需要通过编译器或解释器,将源代码“翻译”成计算机可执行的二进制文件。可在计算机上直接执行的二进制文件被称作可执行文件。无论是在Windows上还是Linux上,.c、.cpp文件是无法直接运行的,需要使用编译工具将.c等源代码文件转化为可执行文件。例如,.exe文件可以在Windows上被计算机运行。
Hello World程序比较简单,现实中我们用到的很多软件都由成百上千个源代码文件组成,将这些源代码文件最终转化为可执行文件的过程,被称为构建(Build)。复杂软件的构建过程会包括一系列活动:
- 从版本控制系统(比如git)上获取最新的源代码
- 编译当前源代码、检查所依赖的其他库或模块
- 执行各类测试,比如单元测试
- 链接(Link)所依赖的库或模块
- 生成可执行文件
构建大型软件确实非常麻烦,一般都会有一些工具辅助完成上述工作。我们把上述这些过程拆解,只关注编译的过程。编译一般分为四步:预处理(Preprocess)、编译(Compile)、汇编(Assembly)和链接(Link)。
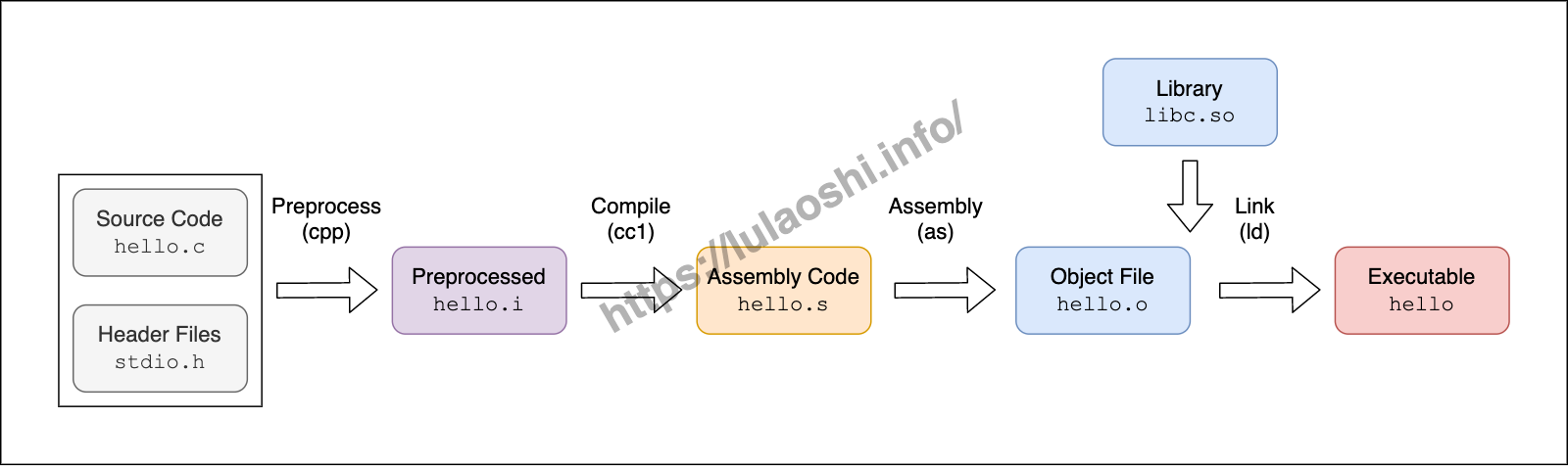
编译HelloWorld需要经过预处理、编译、汇编和链接四个步骤
下面以Linux下的GCC编译过程为例做一些拆解。在介绍编译前,我们先简单介绍一下GCC。
GCC简介
GCC是GNU Compiler Collection的缩写,GCC是一系列编译器的集合,是Linux操作系统的核心组件之一。GCC最初名为GNU C Compiler,当时它只是一款C语言的编译器,不过随着后续迭代,它支持C++、Fortran、Go等语言,GCC也因此成为一个编译器集合。GCC有以下特点:
- GCC支持的编程语言多。比如,
g++是C++编译器,gfortran是Fortran编译器。 - GCC支持的硬件全。GCC可以将源代码编译成x86_64、ARM、PowerPC等硬件架构平台的可执行文件。
- GCC支持众多业界标准。GCC能很快支持最新的C++标准,GCC支持OpenMP、OpenACC。
虽然编译器并非只有GCC一种,macOS上有Clang,Windows上有MSVC,但GCC的这些特点让它从众多编译器间脱颖而出,很多开源软件会选择GCC完成编译工作。
刚才提到,软件构建的过程比较复杂,GCC的一些“兄弟”工具提供了很多支持功能:
- GNU Make:一款自动化编译和构建工具,多文件、多模块的大型软件工程经常需要使用GNU Make。
- GDB:GNU Debugger,用于调试。
- GNU Binutils:一组二进制工具集,包括链接器
ld、汇编器as等,GNU Bintuils可以和GCC、GNU Make一起完成构建过程。我们将在下文使用这些工具。
综上,GCC在Linux操作系统占有举足轻重的地位。
好,我们开始了解一下如何使用GCC编译hello.c文件。下面的命令可以直接将hello.c编译为一个可执行文件:
$ gcc hello.c
它会生成一个名为a.out的可执行文件,执行这个文件:
$ ./a.out
也可以不使用a.out这个名字,我们自己对其进行命名:
$ gcc hello.c -o myexe
这样就生成了一个名为myexe的可执行文件。
前面的命令一步到位,得到了可执行文件,实际上gcc对大量内容进行包装,隐藏了复杂步骤。下面我们从把预处理、编译、汇编和链接几大步骤拆解看看整个编译过程。
预处理
使用预处理器cpp工具进行预处理。注意,这里的cpp是C Preprocessor的缩写,并不是C-plus-plus的意思。
cpp hello.c -o hello.i
这时,我们得到了经过预处理的hello.i文件:
...
extern int printf (const char *__restrict __format, ...);
...
# 2 "hello.c" 2
# 3 "hello.c"
int main() {
printf("Hello World\n");
return 0;
}
这个文件非常长,有八百多行之多,里面有大量的方法,其中就有printf()方法。
预编译主要处理源代码中以#开始的预编译指令,主要处理规则如下:
- 处理
#include预编译指令,将被包含的文件插入到该预编译指令的位置。这是一个递归的过程,如果被包含的文件还包含了其他文件,会递归地完成这个过程。 - 处理条件预编译指令,比如
#if、#ifdef、#elif、#else、#endif。 - 删除
#define,展开所有宏定义。 - 添加行号和文件名标识,以便于在编译过程中产生编译错误或者调试时都能够生成行号信息。
编译
编译的过程主要是进行词法分析、语法分析、语义分析,这背后涉及编译原理等一些内容。这里只进行编译,不汇编,可以生成硬件平台相关的汇编语言。
$ gcc -S hello.i -o hello.s
gcc其实已经做了封装,背后是使用一个名为cc1的工具,cc1并没有放在默认的路径里。Ubuntu 16.04系统上,cc1位于:/usr/lib/gcc/x86_64-linux-gnu/5.4.0/cc1:
$ /usr/lib/gcc/x86_64-linux-gnu/5.4.0/cc1 hello.i -o hello.s
针对华为鲲鹏ARM的OpenEuler系统上,cc1位于:/usr/libexec/gcc/aarch64-linux-gnu/7.3.0/cc1:
$ /usr/libexec/gcc/aarch64-linux-gnu/7.3.0/cc1 hello.i -o hello.s
汇编代码hello.s大致如下:
.file "hello.i"
.section .rodata
.LC0:
.string "Hello World"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $.LC0, %edi
call puts
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.12) 5.4.0 20160609"
.section .note.GNU-stack,"",@progbits
在x86_64架构中,printf()方法在底层是用call puts来实现的,call用来调用一个函数。puts函数只出现了一个名字,它是C标准库里定义的函数,具体的实现并没有在上面这个程序中定义。
汇编
得到汇编代码后,离二进制可执行文件仅有一步之遥,我们可以用as工具将汇编语言翻译成二进制机器码:
$ as hello.s -o hello.o
二进制机器码就很难看懂了:
$ xxd hello.o
00000000: 7f45 4c46 0201 0100 0000 0000 0000 0000 .ELF............
00000010: 0100 3e00 0100 0000 0000 0000 0000 0000 ..>.............
00000020: 0000 0000 0000 0000 a002 0000 0000 0000 ................
00000030: 0000 0000 4000 0000 0000 4000 0d00 0a00 ....@.....@.....
00000040: 5548 89e5 bf00 0000 00e8 0000 0000 b800 UH..............
00000050: 0000 005d c348 656c 6c6f 2057 6f72 6c64 ...].Hello World
00000060: 0000 4743 433a 2028 5562 756e 7475 2035 ..GCC: (Ubuntu 5
00000070: 2e34 2e30 2d36 7562 756e 7475 317e 3136 .4.0-6ubuntu1~16
00000080: 2e30 342e 3132 2920 352e 342e 3020 3230 .04.12) 5.4.0 20
...
...
虽然这个文件已经是二进制的机器码了,但是它仍然不能执行,因为它缺少系统运行所必须的库,比如C语言printf()对应的汇编语言的puts函数。确切的说,系统还不知道puts函数在内存中的具体位置。如果我们在一份源代码中使用了外部的函数或者变量,还需要重要的一步:链接。
链接
很多人不太了解链接,但这一步却是C/C++开发中经常使用的部分。
下面的命令进行链接,生成名为hello的可执行文件:
$ gcc hello.o -o hello
上面的命令基于动态链接的方式,生成的hello已经是一个可执行文件。实际上,这个命令隐藏了很多背后的内容。printf()方法属于libc库,上面的命令并没有体现出来如何将hello.o团队和libc库链接的过程。为了体现链接,我们使用链接器ld,将多个模块链接起来,生成名为myhello的可执行文件:
$ ld -o myhello hello.o /usr/lib/x86_64-linux-gnu/crt1.o /usr/lib/x86_64-linux-gnu/crti.o /usr/lib/x86_64-linux-gnu/crtn.o -lc -dynamic-linker /lib64/ld-linux-x86_64.so.2
我们终于将一份源代码编译成了可执行文件!这个命令有点长,涉及到文件和路径也有点多,它将多个文件和库链接到myhello中。crt1.o、crti.o和crtn.o是C运行时所依赖的环境。如果提示crt1.o这几个文件找不到,可以使用find命令来查找:
$ find /usr/lib -name 'crt1.o'
我们知道,main()方法是C语言程序的入口,crt1.o这几个库是在处理main()方法调用之前和程序退出之后的事情,这需要与操作系统协作。在Linux中,一个新的程序都是由父进程调用fork(),生成一个子进程,然后再调用execve(),将可执行文件加载进来,才能被操作系统执行。所以,准确地说,main()方法是这个程序的入口,但仅仅从main()方法开始,并不能顺利执行这个程序。
ld命令中-lc表示将搜索libc.so的动态链接库。对于Linux的ld,-l参数后面跟随库名(namespec)是一种约定俗成的链接规则,动态链接库会在namespec前加上前缀lib,最终会被命名为libnamespec.so。这里我们想使用C标准库,namespec为c,实际链接的是libc.so这个动态链接库。
此外,ld-linux-x86_64.so.2是链接器ld本身所依赖的库。
我们可以比较一下hello.o链接前后的区别。使用反汇编工具objdump看一下链接前:
$ objdump -dS hello.o
hello.o: 文件格式 elf64-x86_64
Disassembly of section .text:
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: bf 00 00 00 00 mov $0x0,%edi
9: e8 00 00 00 00 callq e <main+0xe>
e: b8 00 00 00 00 mov $0x0,%eax
13: 5d pop %rbp
14: c3 retq
它只有一个main函数,callq调用了某个方法,这个方法在内存中的地址还是不确定的。callq其实就是call,反汇编时会显示为callq。再来看链接后的myhello:
$ objdump -dS myhello
myhello: 文件格式 elf64-x86_64
Disassembly of section .init:
0000000000400340 <_init>:
...
Disassembly of section .plt:
0000000000400360 <puts@plt-0x10>:
...
0000000000400370 <puts@plt>:
400370: ff 25 aa 03 20 00 jmpq *0x2003aa(%rip) # 600720 <_GLOBAL_OFFSET_TABLE_+0x18>
400376: 68 00 00 00 00 pushq $0x0
40037b: e9 e0 ff ff ff jmpq 400360 <_init+0x20>
0000000000400380 <__libc_start_main@plt>:
...
Disassembly of section .plt.got:
0000000000400390 <.plt.got>:
...
Disassembly of section .text:
00000000004003a0 <main>:
4003a0: 55 push %rbp
4003a1: 48 89 e5 mov %rsp,%rbp
4003a4: bf 70 04 40 00 mov $0x400470,%edi
4003a9: e8 c2 ff ff ff callq 400370 <puts@plt>
4003ae: b8 00 00 00 00 mov $0x0,%eax
4003b3: 5d pop %rbp
4003b4: c3 retq
4003b5: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
4003bc: 00 00 00
4003bf: 90 nop
00000000004003c0 <_start>:
4003c0: 31 ed xor %ebp,%ebp
4003c2: 49 89 d1 mov %rdx,%r9
4003c5: 5e pop %rsi
4003c6: 48 89 e2 mov %rsp,%rdx
4003c9: 48 83 e4 f0 and $0xfffffffffffffff0,%rsp
4003cd: 50 push %rax
4003ce: 54 push %rsp
4003cf: 49 c7 c0 60 04 40 00 mov $0x400460,%r8
4003d6: 48 c7 c1 f0 03 40 00 mov $0x4003f0,%rcx
4003dd: 48 c7 c7 a0 03 40 00 mov $0x4003a0,%rdi
4003e4: e8 97 ff ff ff callq 400380 <__libc_start_main@plt>
4003e9: f4 hlt
4003ea: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
00000000004003f0 <__libc_csu_init>:
...
0000000000400460 <__libc_csu_fini>:
...
Disassembly of section .fini:
0000000000400464 <_fini>:
...
这个文件是一个ELF文件,也就是Linux上的可执行文件。我们看到除了main之外,还增加了很多内容,一些内容这里就省略了。我们看main中的callq 400370 <puts@plt>,这行命令确定了puts的具体地址:400370。另外,增加了_start,_start是程序的真正入口,在_start中会进行初始化等工作。
前面使用的是动态链接,也可以使用静态链接的方式:
$ ld -static -o statichello hello.o -L`gcc --print-file-name=` /usr/lib/x86_64-linux-gnu/crt1.o /usr/lib/x86_64-linux-gnu/crti.o /usr/lib/x86_64-linux-gnu/crtn.o --start-group -lc -lgcc -lgcc_eh --end-group
hello.c的源代码只有几行,经过动态链接后的可执行文件4.9KB,静态链接后的可执行文件888KB。
小结
其实,我之前的技术栈主要集中在Java、Python。对C/C++了解并不多,最近需要编译一些软件,同时也在学习编译器的一些基本知识,因此开始重新学习起来。计算机的底层知识确实博大精深,仅仅一个Hello World,竟然经历了这么复杂的过程。预处理、编译、汇编、链接四步中,前三步都有现成的工具可供使用,如果不是专门研发编译器的朋友,大可不必深挖。相比而下,我们开发和编译程序时,经常用到链接。虽然学了很多年的计算机,写了一些程序,但我对链接其实非常不熟悉。对于我来说,超出我以往知识范畴的点包括:如何链接、静态链接和动态链接、main()之前操作系统和编译器所做的工作等等。