AlphaCode论文及原理快速解读
这两天科技媒体沸腾了!DeepMind继AlphaGo、AlphaFold之后,推出了Alpha系列又一神器:AlphaCode。据说这是一个可以自己写代码的AI,并且已经在实际比赛中击败了 46% 左右人类选手!
我们看看科技媒体的标题:
AlphaCode惊世登场!编程版“阿法狗”悄悄参赛,击败一半程序员
AI卷趴程序员!DeepMind祭出竞赛级代码生成系统AlphaCode,超越近半码农
没想到,这大过年的,DeepMind就给程序员添堵:原来最早被AI淘汰的竟然是程序员...
那么AlphaCode到底是个什么神级应用,它会能否替代程序员呢?看完长达73页的论文,本文带大家简单解读一下 AlphaCode。
Problem Setup:问题设置
AlphaCode 参加的是一个名为 Codeforces 的在线编程平台。虽然我并不熟悉 Codeforces,但曾经为了准备面试刷过 LeetCode。如果说 LeetCode 就是为了程序员进互联网大厂刷题而生,主要考察程序员的算法和数据结构的能力的话,那 Codeforces 是一个竞赛版的 LeetCode,Codeforces 上的题目更像 ACM ICPC 或者信息学奥林匹克竞赛。
Codeforces 上的题目五花八门,但是都需要参赛者编程求解。每个题目有描述,有输入样例,有正确的输出样例,即test cases。如果提交的程序能够将所有test cases都跑出正确的结果,那么就算该题通过。一道题只有10次试错机会。

Sampling & Evaluation:海量试错

上图为 AlphaCode 的架构,左侧(Data)为模型和数据部分,主要使用 Transformer 进行预训练和微调,右侧(Samping & Evaluation)是如何生成代码并参与 Codeforces 比赛。
AlphaCode 使用了经典的 Transformer 模型。有关 Transformer 的介绍,网络上已经有不少,我自己之前也写过一些 Transformer 和 BERT 的入门文章。关注深度学习的朋友都知道,Transfomer 作为当前大红大紫的AI模型,虽然在各个榜单上刷榜,但它并不具有人类基本的推理能力。
相比Transformer,我认为使得 AlphaCode 成功的主要在于这个 Sampling & Evaluation。这个 Sampling & Evaluation 系统有点类似搜索引擎或者推荐引擎。AI拥有存储和制作海量内容的能力,但无法知道人类真正需要什么。最关键的就是如何从海量内容中进行筛选。搜索或推荐引擎一般会对海量内容进行检索,最终呈现给用户的只有几条内容。海量的内容需要经过几大步骤:召回、粗排、精排、重排。其实就是先从海量的内容库中,先粗略筛选出一万篇的内容,再使用更精细的模型对一万篇进行一次次筛选,最终选择出与用户需求最相关的几篇内容。
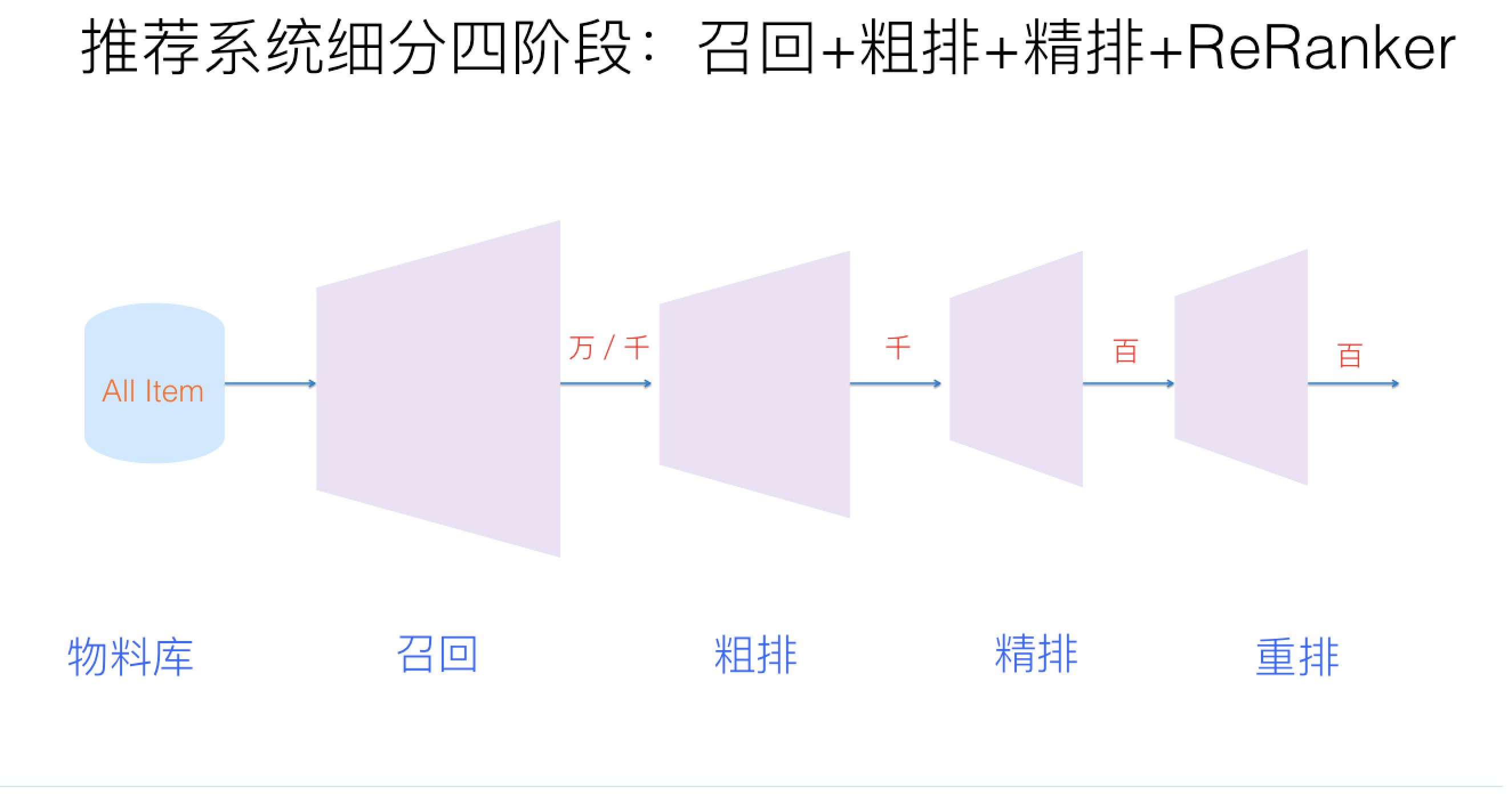
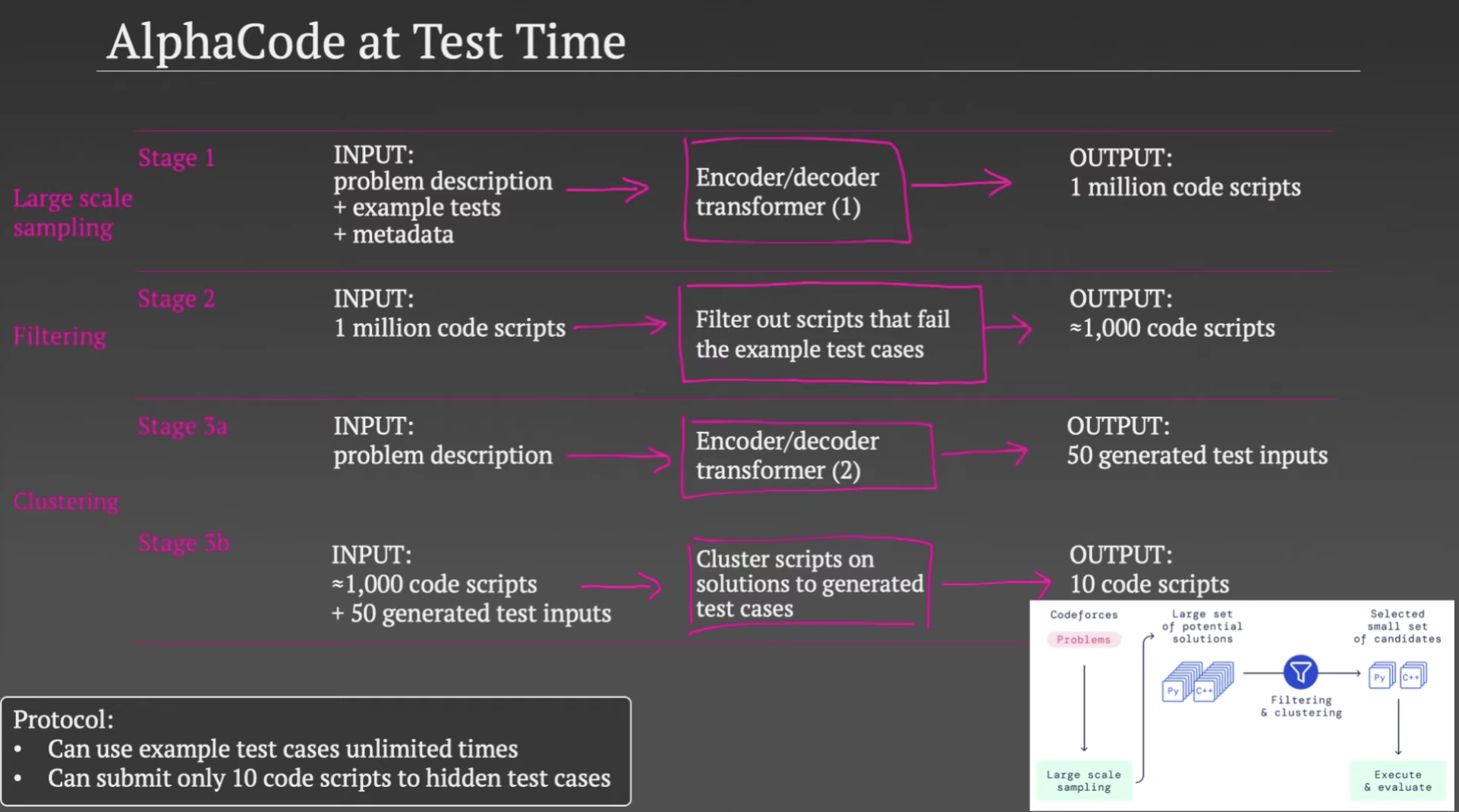
AlphaCode 使用了一个 Transformer 模型,根据编程题目描述,生成百万份代码,这些生成的代码中99%可能根本跑不通。AlphaCode 使用编程题目中的test cases,验证这些生成的代码,这个过程会过滤掉99%的错误代码。
经过过滤之后,仍然可能有上千份代码能跑通,而且这些能跑通题目给出的测试样例的代码中很多非常相似。一个编程题目只有10次提交机会,每一次提交的机会都非常珍贵。不可能将上千份代码都提交上去。AlphaCode 这时候做了一个聚类(Clustering)。首先:AlphaCode 使用了第二个 Transformer 模型,根据编程题目中的文字描述,自动生成一些test cases。但是生成的test cases并不保证准确性,它是为了接下来的聚类用的。然后:将生成的test cases喂给那些代码,如果一些代码的生成结果近乎一样,说明这些代码背后的算法或逻辑相似,可被归为一类。文章称,经过聚类之后,从数目较大的类中选出代码去提交,更有胜算。
图4演示了这个过程,大致包括四步:
- 根据编程题目中的描述等信息,使用第一个Transformer模型,生成百万份代码。
- 使用编程题目中的测试样例test cases验证这百万份代码,把不能通过的过滤掉,剩下大约上千份代码。
- 使用第二个Transformer模型,生成一些test cases。
- 使用第3步生成的test cases,对第2步留下的代码进行验证并聚类,如果两份代码得到的结果相同,则分到同一类。经过聚类后,最终留下10类代码。
Training:模型训练
AlphaCode 使用的经典的预训练+微调(Pretraining + Fine-tuning)范式。
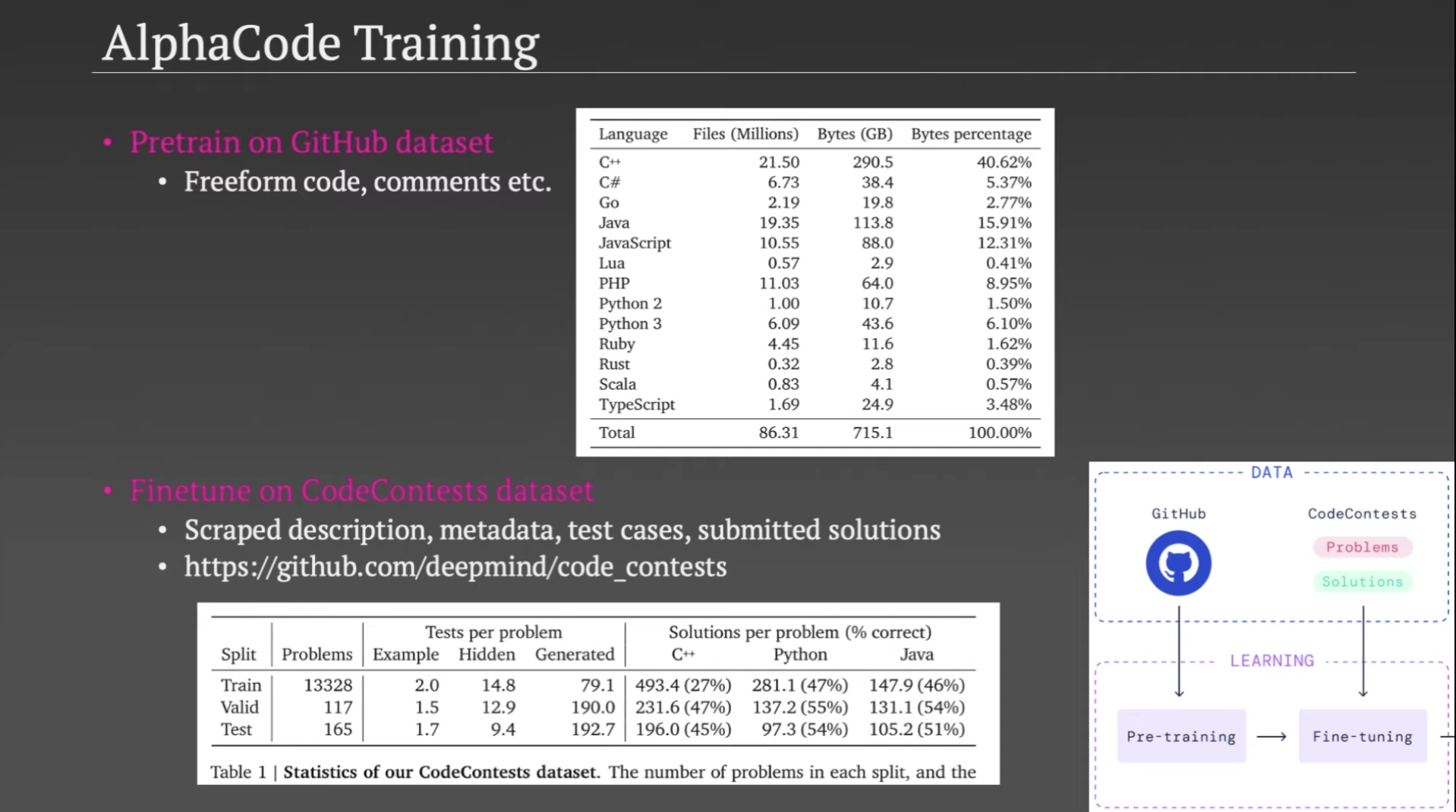
预训练使用的是从 GitHub 爬下来的开源代码,经过了精细的预处理和清洗,大约有715GB。看到这个规模的训练数据,就知道只有屈指可数的几家巨无霸公司能够做这个预训练,实在是太大了,估计需要成千上万块GPU。预训练部分单纯就是让模型学习不同编程语言的套路,或者说学习编程语言中的语义和语法。
微调部分使用的是 CodeContests 数据集,这个数据集收集了很多类似 Codeforces 这样的编程平台上的编程题目、元数据以及人类正确和错误的代码提交结果。目的是针对 Codeforces 这样的编程竞赛,让模型学会如何生成对应的代码。这个数据集大约2GB。
AlphaCode 主要使用了编码器-解码器(Encoder-Decoder)的 seq2seq 方式建模。seq2seq 最经典的应用是机器翻译。给定源文本内容,Encoder 将自然语言编码为一些向量,Decoder 根据向量将自然语言解码为目标文本。那么对于AI自动写代码这个问题,就是输入编程题目,让模型生成目标代码。

Capabilities & Limitations:能力和限制
深度学习是黑盒模型,我们不知道到底模型学到了什么,能否像人类一样认知和推理。论文花了很大精力和篇幅讨论了 AlphaCode 的能力和限制。
作者们提出了一个论点,即 AlphaCode 并不是单纯从训练数据中寻找相似解法,或者说 AlphaCode 并不是单纯从训练数据中拷贝代码。作者的验证方法是对比了生成的代码和训练集中的代码中的代码片段重合的情况,或者说检验 AlphaCode 是不是单纯从训练集里找一些核心代码片段并直接拷贝过来。因此,作者们认为,AlphaCode 具有解决新问题的能力,而不是照猫画虎地把训练数据拷贝搬运过来。知乎上有信息学竞赛选手感慨,有些题目对于人类专业选手来说都很难快速想出解法,但 AlphaCode 却能够得到答案。
作者们发现,模型生成的代码非常依赖编程题目中的描述。比如,同样一个解法,题目描述越冗长,AlphaCode 的求解准确度越低。但是对编程题目的一些其他改变对求解影响不大,比如更改变量名、同义词替换等。
总结
作者认为,AlphaCode 能够击败半数人类选手,主要原因在于:
- 训练数据足够大且质量高。
- Transformer 预训练模型能够将训练数据中涵盖的知识编码到模型中。
- Sampling & Evaluation 的海量试错机制,先生成海量可能的答案,再一步步缩小搜索空间。
阅读完论文和一些解读之后,我感觉至少短期内,离AI替代程序员应该还有一段距离。但是,未来,可真不好说...
参考文献