神经机器翻译数据集WMT预处理流程
神经机器翻译(Neural Machine Translation,NMT)借助深度神经网络对不同语言的文本进行翻译,本文主要介绍机器翻译数据集WMT16 en-de的预处理过程。
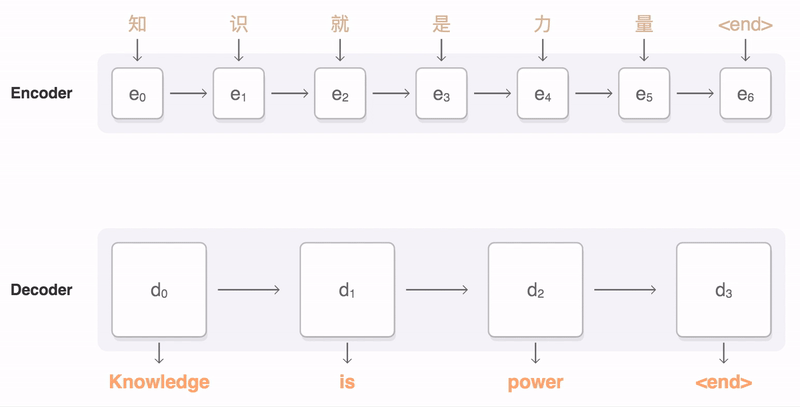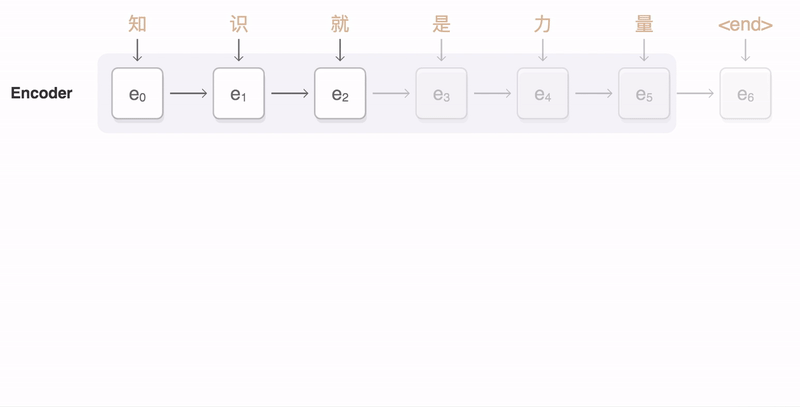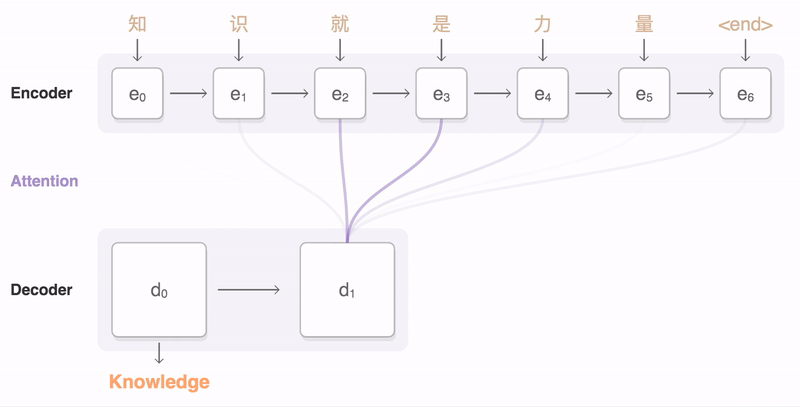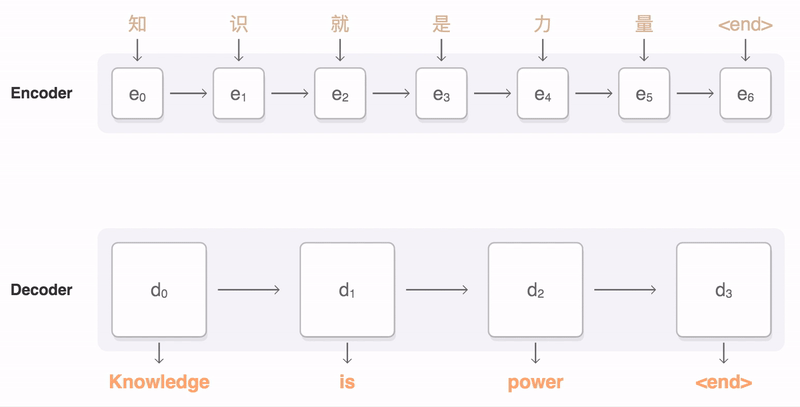
机器翻译
训练语料库
对于神经机器翻译,想要被翻译的源语言被称为Source,想要翻译的目标语言被称为Target。训练数据为两种不同语言的句子对(Source Target Sentence Pair)。以英语(en)德语(de)翻译为例,一个训练数据样本为:
source.en (English):
I declare resumed the session of the European Parliament adjourned on Friday 17 December 1999, and I would like once again to wish you a happy new year in the hope that you enj
oyed a pleasant festive period.
target.de (German):
Ich erkläre die am Freitag, dem 17. Dezember unterbrochene Sitzungsperiode des Europäischen Parlaments für wiederaufgenommen, wünsche Ihnen nochmals alles Gute zum Jahreswechse
l und hoffe, daß Sie schöne Ferien hatten.
自然语言处理中通常将文本定义为由多个**词条(Token)**组成的序列。Token可以是单词,也可以是词干、前缀、后缀等。先把问题最简单化,将Token理解成单词。我们需要使用分词器(Tokenizer)将一个完整的句子拆分成Token。像英语和德语,单词之间有空格分隔,Tokenizer只需要将空格、标点符号等提取出来,就可以获得句子中的Token。常见的Tokenizer有Moses tokenizer.perl脚本或spaCy,nltk或Stanford Tokenizer之类的库。前面的例子经过Tokenizer对标点符号和空格做简单处理后为:
I declare resumed the session of the European Parliament adjourned on Friday 17 December 1999 , and I would like once again to wish you a happy new year in the hope that you en
joyed a pleasant festive period .
其实看不出太多变化,只是所有的单词以及标点符号之间都多了空格。
使用Tokenizer对原始语料进行切分后,生成大量的Token,这些Token共同组成了词表(Vocabulary)。比如,一个英文词表可以是:
I
declare
resumed
...
然而,如果将Token定义为单词,建立基于单词的模型有很多缺点。由于模型输出的是单词的概率分布,因此词表中单词数量很大情况下,模型会变得非常慢。如果单词表中包括拼写错误和各类派生单词,则词表的大小实际上是无限的。我们希望模型只处理最常见的单词,所以需要使用一些方式对单词的数量加以限制。词表大小通常设置为10,000到100,000。以单词作为Token的另一个缺点是该模型无法学习单词的常见“词干”。例如,对于“loved”和“loving”,尽管它们有共同的词干,但模型会认为他们是两种完全不同的词。
处理单词为Token问题的一种方法是使用统计的方法生成子词(Subword)。例如,单词“loved”可以被分为“ lov”和“ ed”,而“ loving”可以被分为“ lov”和“ ing”。这使模型在各类新词上有泛化能力,同时还可以减少词表大小。有许多生成Subword的技术,例如Byte Pair Encoding(BPE)。
BPE获得Subword的步骤如下:
- 准备足够大的训练语料,并确定期望的Subword词表大小;
- 将单词拆分为成最小单元。比如英文中26个字母加上各种符号,这些作为初始词表;
- 在语料上统计单词内相邻单元对的频数,选取频数最高的单元对合并成新的Subword单元;
- 重复第3步直到达到第1步设定的Subword词表大小或下一个最高频数为1。
要为给定的文本生成BPE,可以使用subword-nmt 这个工具,具体使用方法可以参照其GitHub中的说明进行操作。下面是一个例子,其中<train.tok.file>是已经经过Tokenizer进行过处理的文本文件。
# Clone from Github
git clone https://github.com/rsennrich/subword-nmt
cd subword-nmt
# Learn a vocabulary using 10,000 merge operations
./learn_bpe.py -s 10000 <train.tok.file> codes.bpe
# Apply the vocabulary to the training file
./apply_bpe.py -c codes.bpe < train.tok.file> train.tok.bpe
对数据集进行BPE后,句子可能如下所示。adjourned(休会)一词使用并不频繁,被分解为ad@@、jour、ned三部分。由于Token粒度变得更细,词表也需要随之更新。
I declare resumed the session of the European Parliament ad@@ jour@@ ned on Friday 17 December 1999 , and I would like once again to wish you a happy new year in the hope that
you enjoyed a pleasant fes@@ tive period .
WMT数据集处理
神经机器翻译领域国际上最常用的数据集是WMT,很多机器翻译任务基于这个数据集进行训练,Google的工程师们基于WMT16 en-de准备了一个脚本:wmt16_en_de.sh。这个脚本先下载数据,再使用Moses Tokenizer,清理训练数据,并使用BPE生成32,000个Subword的词汇表。可以使用梯子直接下载预处理后的文件:
将文件解压后,可以获得以下文件:
| 文件名 | 内容 |
|---|---|
| train.tok.clean.bpe.32000.en | 经过BPE处理后英语训练数据,每行一个句子。 |
| train.tok.clean.bpe.32000.de | 经过BPE处理后德语训练数据,每行一个句子。 |
| vocab.bpe.32000 | 经过BPE处理后的词表,每行一个Token。 |
| newstestXXXX.* | 测试数据集,与训练集所使用的预处理方式相同,用于测试和验证。 |